 511
511
 2024-10-19 00:02:43(已編輯)
2024-10-19 00:02:43(已編輯)
神經(jīng)信息處理系統(tǒng)會議,,NeurIPS(Conference on Neural Information Processing Systems)是機(jī)器學(xué)習(xí)和計(jì)算神經(jīng)科學(xué)領(lǐng)域中重要的學(xué)術(shù)會議之一,,同時也是中國計(jì)算機(jī)學(xué)會(CCF)推薦的A類會議。NeurIPS每年舉辦一次,,通常在12月舉行,。第38屆NeurIPS 2024將于2024年12月10日至15日在加拿大溫哥華Vancouver Convention Center 召開。
以下是接收論文信息:
1. Ling Yang, Zhaochen Yu, Tianjun Zhang, Shiyi Cao, Minkai Xu, Wentao Zhang, Joseph E. Gonzalez, Bin Cui.
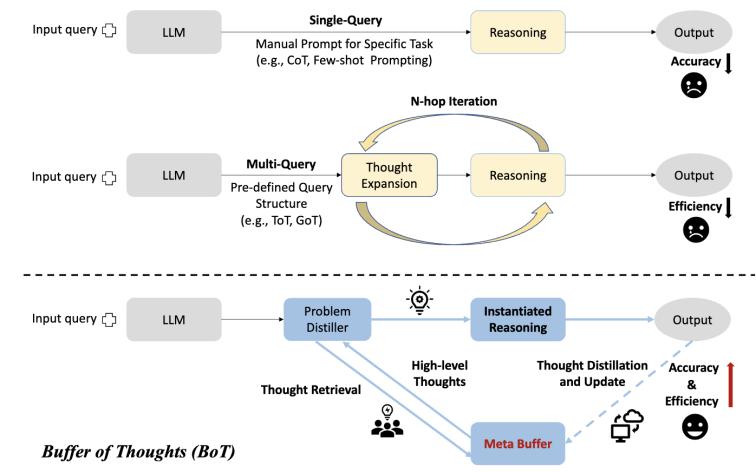
Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models,,NeurIPS 2024 (Spotlight)
【論文簡介】
本文介紹了Buffer of Thoughts (BoT),,這是一種新穎且多功能的思維增強(qiáng)推理方法,旨在提高大語言模型(LLMs)的準(zhǔn)確性,、效率和穩(wěn)健性,。具體來說,我們提出了元緩沖區(qū),,用于存儲一系列信息豐富的高級思維模板,,這些模板從各種任務(wù)的解決過程中提煉而來。對于每個問題,,我們檢索相關(guān)的思維模板,并自適應(yīng)地將其與特定的推理結(jié)構(gòu)結(jié)合,,以進(jìn)行高效推理,。為了保證可擴(kuò)展性和穩(wěn)定性,,我們還提出了緩沖管理器,動態(tài)更新元緩沖區(qū),,從而隨著更多任務(wù)的解決增強(qiáng)其容量,。我們在10個具有挑戰(zhàn)性的推理密集型任務(wù)上進(jìn)行了廣泛實(shí)驗(yàn),相較于之前的SOTA方法,,取得了顯著的性能提升:在Game of 24上提升11%,,在Geometric Shapes上提升20%,在Checkmate-in-One上提升51%,。進(jìn)一步分析表明,,BoT具有優(yōu)越的泛化能力和模型穩(wěn)健性,同時平均僅需多查詢提示方法(如思維樹/圖)的12%的成本,。值得注意的是,,我們發(fā)現(xiàn)Llama3-8B+BoT有潛力超越Llama3-70B模型。
2. Xiaonan Nie, Qibin Liu, Fangcheng Fu, Shenhan Zhu, Xupeng Miao, Xiaoyang Li, Yang Zhang, Shouda Liu, Bin Cui.
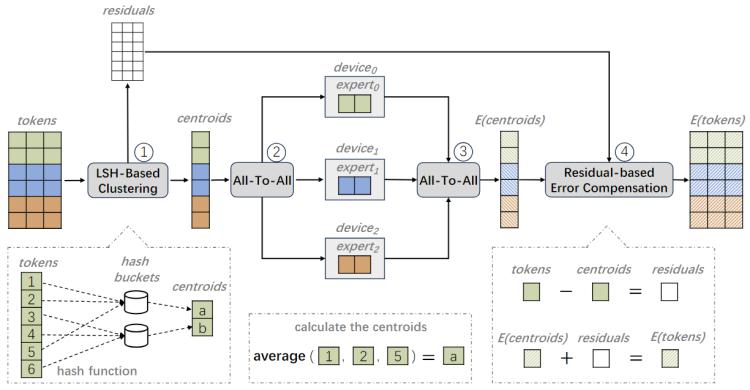
LSH-MoE: Communication-efficient MoE Training via Locality-Sensitive Hashing,,NeurIPS 2024
【論文簡介】
大規(guī)模Transformer模型在各種下游任務(wù)中表現(xiàn)優(yōu)異,,但隨著模型規(guī)模的擴(kuò)展,其訓(xùn)練成本也相應(yīng)增加,。為了高效擴(kuò)大模型規(guī)模,,業(yè)界廣泛采用了混合專家(MoE)架構(gòu),該架構(gòu)由一個門控網(wǎng)絡(luò)和一系列專家組成,,通過將輸入數(shù)據(jù)路由到固定數(shù)量的專家而不是全部專家,,來保持訓(xùn)練成本恒定。在現(xiàn)有的大規(guī)?;旌蠈<矣?xùn)練系統(tǒng)中,,專家通常分布在不同的GPU上以實(shí)現(xiàn)并行化,因此輸入數(shù)據(jù)需要額外的全對全(AlltoAll)通信以傳輸?shù)侥繕?biāo)專家并進(jìn)行相應(yīng)的計(jì)算,。然而,,通過評估三種主流混合專家模型在常用GPU集群上的訓(xùn)練過程,我們發(fā)現(xiàn)全對全通信占比平均為45%,,這大大限制了混合專家模型的訓(xùn)練效率和可擴(kuò)展性,。針對此問題,我們提出了LSH-MoE,,一種基于位置敏感哈希(LSH)的通信高效的混合專家訓(xùn)練框架,。我們首先介紹了現(xiàn)有系統(tǒng)中混合專家訓(xùn)練擴(kuò)展的難題,并重點(diǎn)關(guān)注利用詞元(token)相似性來進(jìn)行數(shù)據(jù)壓縮的可能性,。然后,,我們引入了一種高效的基于位置敏感哈希的壓縮技術(shù),該技術(shù)利用正軸體(cross-polytope)哈希函數(shù)進(jìn)行快速聚類。我們進(jìn)一步采用了基于殘差的誤差補(bǔ)償方案,,以減小壓縮帶來的精度損失,。為了驗(yàn)證方法的有效性,我們在語言模型(RoBERTa,、GPT和T5)和視覺模型(Swin)上進(jìn)行了預(yù)訓(xùn)練和微調(diào)任務(wù)的實(shí)驗(yàn),。結(jié)果表明,我們的方法在不同任務(wù)中比現(xiàn)有方法實(shí)現(xiàn)了1.28倍到2.2倍的加速,。
3. Ye Tian*, Ling Yang*, Haotian Yang, Yuan Gao, Yufan Deng, Jingmin Chen, Xintao Wang, Zhaochen Yu, Xin Tao, Pengfei Wan, Di Zhang, Bin Cui.
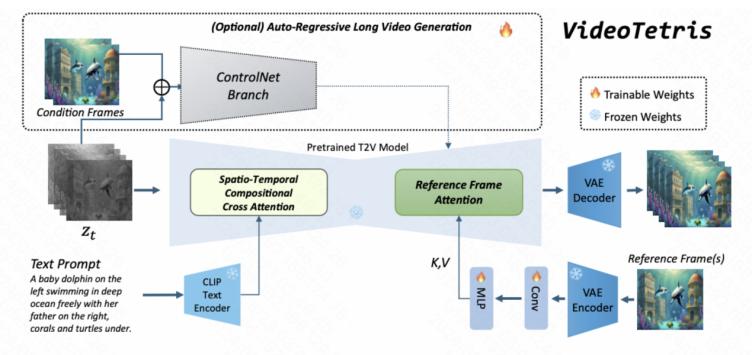
VideoTetris: Towards Compositional Text-to-Video Generation, NeurIPS 2024
【論文簡介】
擴(kuò)散模型在文本到視頻(T2V)生成方面取得了顯著成功,。然而,現(xiàn)有方法在處理涉及多個對象或?qū)ο髷?shù)量動態(tài)變化的復(fù)雜(長)視頻生成場景時可能面臨挑戰(zhàn),。為了解決這些限制,,我們提出了VideoTetris,這是一種支持組合式T2V生成的新框架,。具體而言,,我們提出了時空組合擴(kuò)散,通過在空間和時間上操控去噪網(wǎng)絡(luò)的注意力圖,,精確遵循復(fù)雜的文本語義,。此外,我們還提出了增強(qiáng)的視頻數(shù)據(jù)預(yù)處理,,以改進(jìn)關(guān)于運(yùn)動動態(tài)和提示理解的訓(xùn)練數(shù)據(jù),,并配備了一種新的參考幀注意機(jī)制,以提高自回歸視頻生成的一致性,。大量實(shí)驗(yàn)表明,,VideoTetris在組合式T2V生成中取得了令人印象深刻的定性和定量結(jié)果。
4. Yifei Xia, Fangcheng Fu, Wentao Zhang, Jiawei Jiang, Bin Cui.
Efficient Multi-task LLM Quantization and Serving for Multiple LoRA Adapters, NeurIPS 2024
【論文簡介】
在LLM多任務(wù)服務(wù)場景下,,負(fù)載不均等問題導(dǎo)致的資源浪費(fèi)是一個普遍存在但常被忽視的挑戰(zhàn),。模型不僅需要頻繁在不同任務(wù)之間切換,還要應(yīng)對各任務(wù)不同的計(jì)算需求,。這種復(fù)雜情況往往使現(xiàn)有的LLM服務(wù)系統(tǒng)在資源分配上效率低下,,同時頻繁切換不同任務(wù)的LoRA適配器,也會導(dǎo)致內(nèi)存消耗過高,、吞吐量降低,。 為解決這一問題,我們提出了LoRA-Inlaid系統(tǒng),,旨在降低資源消耗的同時提升系統(tǒng)服務(wù)質(zhì)量,。在多任務(wù)場景下,不同任務(wù)需要頻繁切換適配器,,這導(dǎo)致顯存足跡過大,。為此,,我們通過研究不同任務(wù)的適配器對基座模型影響的差異,提出了一種高效的量化算法,,成功降低了多任務(wù)服務(wù)時的顯存足跡,。 此外,,為應(yīng)對實(shí)時變化的請求類型,,我們設(shè)計(jì)了靈活的適配器動態(tài)添加方案。通過GPU與CPU的異步協(xié)同處理,,LoRA-Inlaid能夠以最小的資源代價快速部署新任務(wù),,同時確保在線服務(wù)的穩(wěn)定性。為優(yōu)化資源利用,,我們針對多任務(wù)服務(wù)的特性,,設(shè)計(jì)了一種新穎的多任務(wù)推理調(diào)度算法,進(jìn)一步提升了系統(tǒng)整體效率,。最終,,LoRA-Inlaid在多任務(wù)場景中不僅能靈活應(yīng)對不同任務(wù)的需求,還在吞吐量,、延遲,、作業(yè)完成時間及服務(wù)水平目標(biāo)達(dá)成率等方面實(shí)現(xiàn)了顯著提升。

5. Xinchen Zhang*, Ling Yang*, Yaqi Cai, Zhaochen Yu, Kai-Ni Wang, Jiake Xie, Ye Tian, Minkai Xu, Yong Tang, Yujiu Yang, Bin Cui.
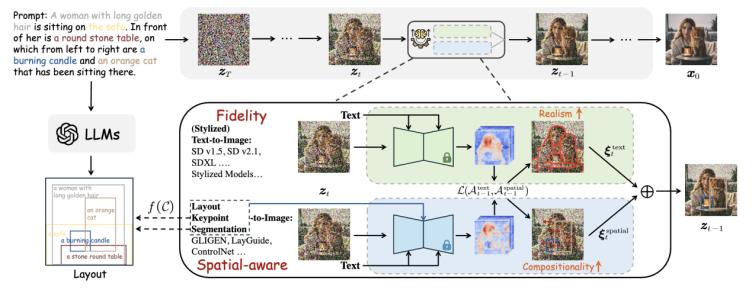
RealCompo: Balancing Realism and Compositionality Improves Text-to-Image Diffusion Models, NeurIPS 2024
【論文簡介】
擴(kuò)散模型在文本到圖像生成方面取得了顯著進(jìn)展,。然而,,現(xiàn)有模型在多對象組合生成時仍面臨許多困難。本文提出了RealCompo,,一種無需訓(xùn)練且易于遷移的文本到圖像生成框架,,旨在利用文本到圖像模型和空間感知圖像擴(kuò)散模型(如布局、關(guān)鍵點(diǎn)和分割圖)的優(yōu)勢,,提升生成圖像的真實(shí)感和組合性,。我們提出了一種直觀且新穎的平衡器,可以在去噪過程中動態(tài)平衡兩種模型的優(yōu)勢,,允許任何模型無需額外訓(xùn)練即可即插即用,。大量實(shí)驗(yàn)表明,RealCompo在多對象組合生成中持續(xù)優(yōu)于最先進(jìn)的文本到圖像模型和空間感知圖像擴(kuò)散模型,,同時保持生成圖像的滿意真實(shí)感和組合性,。值得注意的是,RealCompo可以無縫擴(kuò)展到各種空間感知圖像擴(kuò)散模型和風(fēng)格化擴(kuò)散模型,。
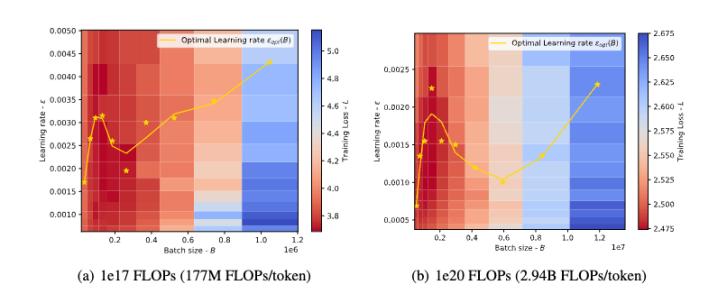
6. Shuaipeng Li*, Penghao Zhao*, Hailin Zhang*, Samm Sun, Hao Wu, Dian Jiao, Weiyan Wang, Chengjun Liu, Zheng Fang, Jinbao Xue, Yangyu Tao, Bin Cui, Di Wang.
Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling, NeurIPS 2024
【論文簡介】
在當(dāng)前的深度學(xué)習(xí)任務(wù)中,,Adam類優(yōu)化器(如Adam、Adagrad,、RMSprop,、Adafactor和Lion)已被廣泛用作SGD類優(yōu)化器的替代方案。這些優(yōu)化器通常使用梯度的符號來更新模型參數(shù),從而產(chǎn)生更穩(wěn)定的收斂曲線,。學(xué)習(xí)率和token批量大小是優(yōu)化器最關(guān)鍵的超參數(shù),,需要仔細(xì)調(diào)整以實(shí)現(xiàn)有效的收斂。先前的研究表明,,對于SGD類優(yōu)化器,,最優(yōu)學(xué)習(xí)率隨著token批量大小的增加呈線性增長(或遵循類似的規(guī)則)。然而,,這一結(jié)論并不適用于Adam類優(yōu)化器,。在本文中,我們通過理論分析和大量實(shí)驗(yàn)闡明了Adam類優(yōu)化器中最優(yōu)學(xué)習(xí)率與token批量大小之間的關(guān)系,。首先,,我們提出了在“梯度符號”情況下token批量大小與最優(yōu)學(xué)習(xí)率之間的縮放定律,并證明隨著token批量大小的增加,,最優(yōu)學(xué)習(xí)率先上升后下降,。此外,隨著訓(xùn)練的進(jìn)行,,峰值將逐漸向更大的token批量大小移動,。其次,我們在各種計(jì)算機(jī)視覺(CV)和自然語言處理(NLP)任務(wù)上進(jìn)行了實(shí)驗(yàn),,并驗(yàn)證了該縮放定律的正確性,。
北京大學(xué)數(shù)據(jù)與智能實(shí)驗(yàn)室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR實(shí)驗(yàn)室)由北京大學(xué)計(jì)算機(jī)學(xué)院崔斌教授領(lǐng)導(dǎo),,長期從事數(shù)據(jù)庫系統(tǒng),、大數(shù)據(jù)管理與分析、人工智能等領(lǐng)域的前沿研究,,在理論和技術(shù)創(chuàng)新以及系統(tǒng)研發(fā)上取得多項(xiàng)成果,,已在國際頂級學(xué)術(shù)會議和期刊發(fā)表學(xué)術(shù)論文100余篇,發(fā)布多個開源項(xiàng)目,。課題組同學(xué)曾數(shù)十次獲得包括CCF優(yōu)博,、ACM中國優(yōu)博、北大優(yōu)博,、微軟學(xué)者,、蘋果獎學(xué)金、谷歌獎學(xué)金等榮譽(yù),。PKU-DAIR實(shí)驗(yàn)室持續(xù)與工業(yè)界展開卓有成效的合作,,與騰訊、阿里巴巴,、蘋果,、微軟,、百度、快手,、中興通訊等多家知名企業(yè)開展項(xiàng)目合作和前沿探索,,解決實(shí)際問題,進(jìn)行科研成果的轉(zhuǎn)化落地,。









載")