 537
537
 2025-01-09 17:17:15(已編輯)
2025-01-09 17:17:15(已編輯)
SIGMOD 2025 | PKU-DAIR實驗室論文
被SIGMOD 2025錄用
ACM SIGMOD是數(shù)據(jù)庫領(lǐng)域影響力最高的國際學(xué)術(shù)會議之一,,也是CCF推薦的A類國際學(xué)術(shù)會議之一,近年來接收率17%-20%左右,。SIGMOD2025將于2025年6月22日-27日在德國柏林舉行,。
PKU-DAIR實驗室論文《MEMO:Fine-grained Tensor Management For Ultra-long ContextLLM Training》被數(shù)據(jù)庫領(lǐng)域頂級會議SIGMOD 2025錄用。
面向長序列大模型訓(xùn)練的細粒度張量管理
作者:Pinxue Zhao, Hailin Zhang, Fangcheng Fu, Xiaonan Nie, Qibin Liu, Fang Yang, Yuanbo Peng, Dian Jiao, Shuaipeng Li, Jinbao Xue, Yangyu Tao, Bin Cui
論文鏈接:https://arxiv.org/abs/2407.12117
1. 引言
在預(yù)訓(xùn)練階段使用長文本是增強大模型長文本能力的關(guān)鍵方法,。然而,在實際中,,長文本訓(xùn)練面臨以下嚴重挑戰(zhàn):
(1)重計算開銷大,。在長文本訓(xùn)練中,激活值顯存隨文本長度線性增大,。由于GPU顯存限制,,實際訓(xùn)練中通常需開啟全重計算。重計算會導(dǎo)致約20%的額外端到端計算開銷,。
(2)顯存碎片化導(dǎo)致Pytorch顯存分配器經(jīng)常調(diào)用``cudaFree''和``cudaMalloc''兩個同步操作重新整理顯存,,嚴重拖慢訓(xùn)練效率。
2. 方法
(1)針對重計算開銷,,我們注意到,,由于Transformer層的計算時間隨序列長度平方增長,而層內(nèi)激活值隨序列長度線性增長,,我們提出使用CPU Swap替代(或部分代替)重計算,,從而減小重計算開銷。具體而言,,為確保CPU-GPU數(shù)據(jù)傳輸被單個Transformer層的計算覆蓋,,以及確保系統(tǒng)CPU內(nèi)存不被耗盡,我們提出了細粒度的Swap策略,。因為在長序列場景下,,F(xiàn)lashAttention計算成為整個Transformer層計算的瓶頸,,我們將每個Transformer層的輸入和FlashAttention的輸出完整Swap,而對其余激活值,,只Swap其一部分,。通過這樣的設(shè)計,我們盡可能減小了重計算開銷,,充分利用了空閑的CPU內(nèi)存和PCIe帶寬,。
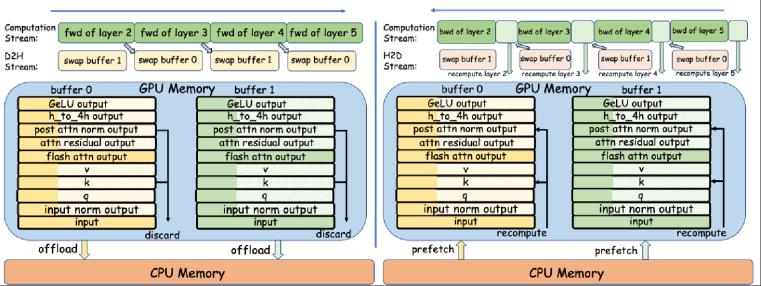
圖1. 細粒度swapping和重計算示意
(2)針對顯存碎片問題,我們利用大語言模型由多個相同的Transformer層堆疊而成的性質(zhì),,提出一種雙層的混合整數(shù)線性規(guī)劃算法解決這一問題,。具體而言,我們首先執(zhí)行一輪訓(xùn)練,,獲得張量顯存的存取序列,。基于這一序列,,我們使用混合整數(shù)線性規(guī)劃算法確定每個張量的地址,,最小化顯存峰值和碎片。進而,,在正式訓(xùn)練時,,每個激活值張量的地址都已預(yù)先確定,從而避免了Pytorch顯存分配器頻繁進行顯存重整,。

圖2. 雙層MIP算法示意
3. 實驗結(jié)果
我們基于Megatron-LM和TransformerEngine實現(xiàn)了我們的系統(tǒng),,MEMO。端到端實驗結(jié)果表明,,我們通過減少顯存碎片以及減少重計算開銷,,可以在單機8卡A800上支持7B GPT模型訓(xùn)練1 Million長度的文本,并且達到超50%的MFU,。更多實驗數(shù)據(jù)可以參考論文,。
下圖展示了MEMO的擴展性。我們可以發(fā)現(xiàn)MEMO具有線性擴展性,,在8機64卡上支持7B模型,,8 Million序列長度的訓(xùn)練。其余實驗可參考論文,。

圖3. (a) 支持的最大序列長度 (b)在最大序列長度下的MFU (c)不同序列長度下的MFU
4. 總結(jié)
本工作提出面向長序列語言模型訓(xùn)練的一種細粒度張量管理方案--MEMO,。通過結(jié)合細粒度的CPU Swapping和重計算技術(shù),以及顯存規(guī)劃,,MEMO成功支持更長序列的訓(xùn)練,,并且實現(xiàn)了更高的訓(xùn)練效率,以及擁有較好的擴展性。
北京大學(xué)數(shù)據(jù)與智能實驗室(Data And Intelligence Research Lab at Peking Univeristy,,PKU-DAIR實驗室)由北京大學(xué)計算機學(xué)院崔斌教授領(lǐng)導(dǎo),,長期從事數(shù)據(jù)庫系統(tǒng)、大數(shù)據(jù)管理與分析,、人工智能等領(lǐng)域的前沿研究,,在理論和技術(shù)創(chuàng)新以及系統(tǒng)研發(fā)上取得多項成果,已在國際頂級學(xué)術(shù)會議和期刊發(fā)表學(xué)術(shù)論文100余篇,,發(fā)布多個開源項目,。課題組同學(xué)曾數(shù)十次獲得包括CCF優(yōu)博、ACM中國優(yōu)博,、北大優(yōu)博,、微軟學(xué)者、蘋果獎學(xué)金,、谷歌獎學(xué)金等榮譽,。PKU-DAIR實驗室持續(xù)與工業(yè)界展開卓有成效的合作,與騰訊,、阿里巴巴,、蘋果、微軟,、百度,、快手、中興通訊等多家知名企業(yè)開展項目合作和前沿探索,,解決實際問題,,進行科研成果的轉(zhuǎn)化落地。









載")