








PKU-DAIR實(shí)驗(yàn)室兩項(xiàng)成果被ASPLOS 2025錄用
ASPLOS (ACM International Conference on Architectural Support for Programming Languages and Operating Systems) 是計(jì)算機(jī)科學(xué)領(lǐng)域頂級的國際學(xué)術(shù)會議之一,專注于計(jì)算機(jī)體系結(jié)構(gòu),、編程語言與操作系統(tǒng)等領(lǐng)域,。ASPLOS是計(jì)算機(jī)系統(tǒng)領(lǐng)域最具影響力的會議之一,,屬于計(jì)算機(jī)科學(xué)領(lǐng)域的A類會議(中國計(jì)算機(jī)學(xué)會CCF評定的A類會議),錄用的難度相對較大,,接受率通常較低,,約為15%到20%之間,每年接收的論文約為100~150篇,。PKU-DAIR實(shí)驗(yàn)室《Spindle: Efficient Distributed Training of Multi-Task Large Models via Wavefront Scheduling》和《FlexSP: Accelerating Large Language Model Training via Flexible Sequence Parallelism》兩篇論文被ASPLOS 2025錄用,!論文核心作者包括北大PKU-DAIR實(shí)驗(yàn)室四年級博士生王馭捷、三年級碩士生竺沈涵,、北航本科四年級科研實(shí)習(xí)生王士舉等,。歡迎對分布式深度學(xué)習(xí)系統(tǒng)、高效大模型框架感興趣的學(xué)界業(yè)界人士關(guān)注我們的工作,!
論文接收信息如下:
1. Spindle: Efficient Distributed Training of Multi-Task Large Models via Wavefront Scheduling
作者:Yujie Wang, Shenhan Zhu, Fangcheng Fu, Xupeng Miao, Jie Zhang, Juan Zhu, Fan Hong, Yong Li, Bin Cui
論文鏈接:https://arxiv.org/abs/2409.03365
近期最先進(jìn)的大規(guī)?;P途邆淞送瑫r(shí)理解和處理多個(gè)任務(wù)、多種數(shù)據(jù)模態(tài)的強(qiáng)大能力,,例如語言任務(wù)、圖像任務(wù),、視頻任務(wù),、語音任務(wù)等。這類模型通常由一個(gè)統(tǒng)一的基礎(chǔ)模型結(jié)構(gòu)和多個(gè)專門化的模型組件組成,,其模型結(jié)構(gòu)復(fù)雜,,圖1展示了多任務(wù)多模態(tài)大模型的復(fù)雜結(jié)構(gòu)。現(xiàn)有的大模型訓(xùn)練系統(tǒng)均主要針對單一任務(wù),、單一模態(tài)的模型而設(shè)計(jì),,而如此復(fù)雜的多任務(wù)多模態(tài)大模型會對高效訓(xùn)練系統(tǒng)的設(shè)計(jì)帶來巨大挑戰(zhàn),一方面其復(fù)雜模型結(jié)構(gòu)和多任務(wù)多模態(tài)特性使其存在嚴(yán)重的負(fù)載異構(gòu)性,,導(dǎo)致現(xiàn)有系統(tǒng)訓(xùn)練這類模型容易造成資源浪費(fèi)和低效,,另一方面復(fù)雜的模型結(jié)構(gòu)同時(shí)也帶來復(fù)雜的執(zhí)行依賴,而現(xiàn)有系統(tǒng)無法高效處理這種依賴,。
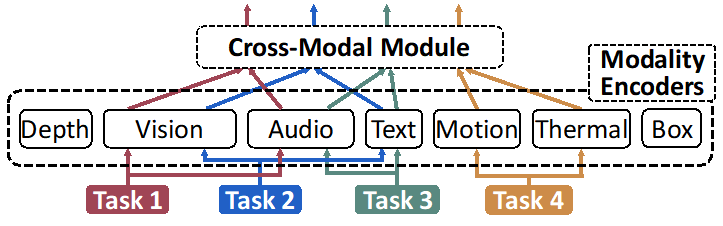
圖1:多任務(wù)多模態(tài)大模型的復(fù)雜模型結(jié)構(gòu)
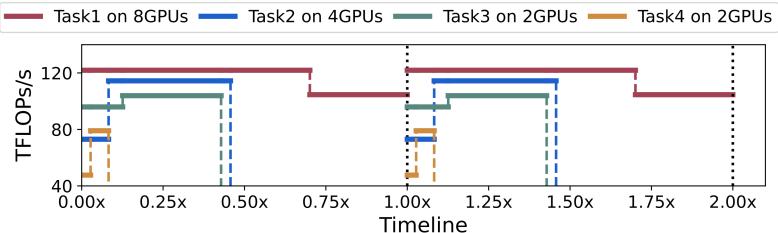
圖2:現(xiàn)有系統(tǒng)訓(xùn)練多任務(wù)多模態(tài)大模型的資源低效和浪費(fèi)
為此,,本工作設(shè)計(jì)了一個(gè)全新的訓(xùn)練系統(tǒng)——Spindle,旨在通過波面調(diào)度(Wavefront Scheduling)的方法實(shí)現(xiàn)多任務(wù)多模態(tài)大模型高效分布式訓(xùn)練,。Spindle的核心思想是將負(fù)載異構(gòu)和執(zhí)行依賴的復(fù)雜模型分解為多個(gè)順序執(zhí)行的波(Wave),。具體而言,波(Wave)是Spindle中最小粒度的執(zhí)行調(diào)度單位,,在每個(gè)波內(nèi),,集群中會存在多個(gè)算子并行執(zhí)行,這些算子各自占據(jù)一部分集群資源并具有相近的執(zhí)行時(shí)間開銷,,一個(gè)波代表著一種集群資源分配模式,。Spindle將復(fù)雜的模型執(zhí)行分解為多個(gè)波,,并順序地解決聯(lián)合優(yōu)化問題,包括異構(gòu)負(fù)載感知的并行化和依賴驅(qū)動的執(zhí)行調(diào)度,,從而實(shí)現(xiàn)多任務(wù)大模型的高效訓(xùn)練,。

圖3:Spindle系統(tǒng)框架概覽

圖4:Spindle基于波面調(diào)度的訓(xùn)練執(zhí)行規(guī)劃示意圖
圖3展示了Spindle的系統(tǒng)框架架構(gòu),其由執(zhí)行規(guī)劃器(Execution Planner)和訓(xùn)練框架(Training Framework)組成,,執(zhí)行規(guī)劃器分為五個(gè)系統(tǒng)組件,,包括:圖收縮組件(Graph Contraction)負(fù)責(zé)對龐大的計(jì)算圖進(jìn)行收縮簡化,可擴(kuò)展性估計(jì)器(Scalability Estimator)負(fù)責(zé)對負(fù)載異構(gòu)的算子進(jìn)行執(zhí)行開銷和可擴(kuò)展性的準(zhǔn)確估計(jì),,資源分配器(Resource Allocator)負(fù)責(zé)對算子分配合適的計(jì)算資源量,,波面調(diào)度器(Wavefront Scheduler)負(fù)責(zé)將算子組織成多個(gè)順序執(zhí)行的波并生成波面調(diào)度方案,設(shè)備放置器(Device Placement)負(fù)責(zé)將各個(gè)算子放置到GPU設(shè)備上并生成最終的執(zhí)行規(guī)劃,,并交由運(yùn)行時(shí)引擎(Runtime Engine)進(jìn)行高效的多任務(wù)大模型訓(xùn)練,。圖4給出了一個(gè)Spindle基于波面調(diào)度的訓(xùn)練執(zhí)行規(guī)劃的示意圖,其包含了六個(gè)順序執(zhí)行的波,。

圖5:Spindle相比于現(xiàn)有系統(tǒng)的端到端性能對比實(shí)驗(yàn)
我們實(shí)現(xiàn)并構(gòu)建了該系統(tǒng),,并在多種多任務(wù)多模態(tài)模型上進(jìn)行了評估。圖5展示了Spindle相比于現(xiàn)有系統(tǒng)的端到端性能對比實(shí)驗(yàn),,實(shí)驗(yàn)結(jié)果表明,,Spindle在性能和效率方面優(yōu)于現(xiàn)有的訓(xùn)練系統(tǒng)(例如Megatron-LM和DeepSpeed),加速比最高可達(dá)71%,。
2. FlexSP: Accelerating Large Language Model Training via Flexible Sequence Parallelism
作者:Yujie Wang, Shiju Wang, Shenhan Zhu, Fangcheng Fu, Xinyi Liu, Xuefeng Xiao, Huixia Li, Jiashi Li, Faming Wu, Bin Cui
論文鏈接:https://arxiv.org/abs/2412.01523
代碼鏈接:https://github.com/PKU-DAIR/Hetu-Galvatron
隨著大語言模型(LLMs)的快速發(fā)展和取得的巨大成就,,擴(kuò)展其上下文長度(即最大支持的序列長度)成為了一個(gè)迫切需求。為支持LLM的長上下文訓(xùn)練,,序列并行作為關(guān)鍵技術(shù)應(yīng)運(yùn)而生,,它將每個(gè)輸入序列切分并分散到多個(gè)設(shè)備上,并通過必要的通信來處理這些序列,。然而,,現(xiàn)有的序列并行方法假設(shè)輸入序列是同質(zhì)的(即所有序列長度一致),并采用單一靜態(tài)并行策略,,這在實(shí)際應(yīng)用中是低效的,。

圖1:大語言模型訓(xùn)練語料庫中序列長度的長尾分布

圖2:不同序列并行度下不同序列的訓(xùn)練時(shí)間和通信時(shí)間占比
具體而言,在真實(shí)世界的大語言模型訓(xùn)練語料庫中,,序列長度表現(xiàn)出顯著的差異,,通常呈長尾分布(如圖1所示),短序列占絕大部分,,而長序列較少,,這種差異性導(dǎo)致訓(xùn)練負(fù)載的異構(gòu)性。長序列需要更大的并行度來分?jǐn)傦@存開銷,,但這會受到跨機(jī)通信帶寬的限制,,導(dǎo)致較高的額外通信開銷(如圖2展示),。相對而言,低并行度策略更為高效,。然而,,現(xiàn)有同構(gòu)系統(tǒng)在訓(xùn)練中只能使用單一靜態(tài)的策略,這使得短序列也不得不采用低效的高并行度策略,,而短序列又占據(jù)了訓(xùn)練數(shù)據(jù)集的絕大部分,,這導(dǎo)致現(xiàn)有同構(gòu)系統(tǒng)處理真實(shí)異構(gòu)數(shù)據(jù)時(shí)效率很低。

圖3:FlexSP異構(gòu)自適應(yīng)序列并行的例子
為了解決這一問題,,我們首次提出了一個(gè)基于異構(gòu)理念設(shè)計(jì)的訓(xùn)練系統(tǒng)FlexSP,,其使用異質(zhì)自適應(yīng)的序列并行方法來處理不同序列之間的異質(zhì)工作負(fù)載。圖3展示了一個(gè)簡單的例子,,表明對于不同長度的序列采用合適的并行策略能夠提高訓(xùn)練效率,。我們的系統(tǒng)會在每輪訓(xùn)練迭代中捕捉序列長度的異質(zhì)性,并根據(jù)工作負(fù)載特征分配最優(yōu)的異構(gòu)序列并行策略組合,。這種基于異構(gòu)理念設(shè)計(jì)的并行范式和訓(xùn)練系統(tǒng)能夠天然捕捉異構(gòu)負(fù)載的特征,,并實(shí)現(xiàn)高效訓(xùn)練。

圖4:FlexSP的系統(tǒng)架構(gòu)圖
圖4展示了我們系統(tǒng)FlexSP的系統(tǒng)架構(gòu)圖,,其由求解器和執(zhí)行器組成,,求解器包含:并行規(guī)劃器(Parallelism Planner)負(fù)責(zé)將異構(gòu)序列并行的問題建模為線性規(guī)劃優(yōu)化問題并高效地求解,其包括了異構(gòu)序列并行組的構(gòu)建和時(shí)間均衡的并行組序列分配,;序列分組器(Sequence Blaster)負(fù)責(zé)將輸入的數(shù)據(jù)批次(Batch),切分為若干個(gè)數(shù)據(jù)微批次(Micro-batch),,使得集群的顯存能夠容納每一個(gè)微批次,,并將每個(gè)微批次交由并行規(guī)劃器進(jìn)行異構(gòu)策略的求解。求解器生成的最優(yōu)規(guī)劃會交由執(zhí)行器進(jìn)行訓(xùn)練,。值得一提的是,,F(xiàn)lexSP通過數(shù)據(jù)預(yù)取和求解-訓(xùn)練解耦的方式,將求解開銷(Overlap)完全隱藏于訓(xùn)練時(shí)間中,,因此不會引起任何額外開銷,。

圖5:FlexSP相比于SOTA系統(tǒng)的端到端性能實(shí)驗(yàn)對比
我們構(gòu)建了基于異構(gòu)理念設(shè)計(jì)的LLM訓(xùn)練系統(tǒng)FlexSP,并在多個(gè)數(shù)據(jù)集,、多種大小模型上進(jìn)行了實(shí)驗(yàn),,圖5展示了FlexSP相比于SOTA訓(xùn)練系統(tǒng)(例如Megatron-LM, DeepSpeed)的性能對比,實(shí)驗(yàn)結(jié)果表明,,我們的系統(tǒng)在性能上比現(xiàn)有的最先進(jìn)訓(xùn)練框架提高了最多1.98倍,。
實(shí)驗(yàn)室簡介
北京大學(xué)數(shù)據(jù)與智能實(shí)驗(yàn)室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR實(shí)驗(yàn)室)由北京大學(xué)計(jì)算機(jī)學(xué)院崔斌教授領(lǐng)導(dǎo),,長期從事數(shù)據(jù)庫系統(tǒng),、大數(shù)據(jù)管理與分析,、人工智能等領(lǐng)域的前沿研究,在理論和技術(shù)創(chuàng)新以及系統(tǒng)研發(fā)上取得多項(xiàng)成果,,已在國際頂級學(xué)術(shù)會議和期刊發(fā)表學(xué)術(shù)論文200余篇,,發(fā)布多個(gè)開源項(xiàng)目。課題組同學(xué)曾數(shù)十次獲得包括CCF優(yōu)博,、ACM中國優(yōu)博,、北大優(yōu)博、微軟學(xué)者,、蘋果獎(jiǎng)學(xué)金,、谷歌獎(jiǎng)學(xué)金等榮譽(yù)。PKU-DAIR實(shí)驗(yàn)室持續(xù)與工業(yè)界展開卓有成效的合作,,與騰訊,、阿里巴巴、蘋果,、微軟,、百度、快手,、中興通訊等多家知名企業(yè)開展項(xiàng)目合作和前沿探索,,解決實(shí)際問題,進(jìn)行科研成果的轉(zhuǎn)化落地,。
載")

評論 0