








SIGMOD會(huì)議是數(shù)據(jù)庫(kù)領(lǐng)域最具影響力的頂級(jí)國(guó)際學(xué)術(shù)會(huì)議之一,,與VLDB和ICDE并稱(chēng)為數(shù)據(jù)庫(kù)領(lǐng)域的三大頂級(jí)會(huì)議,。PKU-DAIR實(shí)驗(yàn)室發(fā)表于SIGMOD 2024的研究成果《CAFE: Towards Compact, Adaptive, and Fast Embedding for Large-scale Recommendation Models》榮獲了SIGMOD24 Honorable Mention for Best Artifact,該獎(jiǎng)項(xiàng)每年僅授予至多三篇文章,,旨在表彰那些在可復(fù)現(xiàn)性,、靈活性和可移植性方面表現(xiàn)卓越的研究工作。
導(dǎo)讀
近年來(lái),,深度學(xué)習(xí)推薦模型(DLRM)中嵌入表的內(nèi)存需求不斷增長(zhǎng),,給模型訓(xùn)練和部署帶來(lái)了巨大的挑戰(zhàn)。現(xiàn)有的嵌入壓縮解決方案無(wú)法同時(shí)滿足三個(gè)關(guān)鍵設(shè)計(jì)要求:高內(nèi)存效率,、低延遲和動(dòng)態(tài)數(shù)據(jù)分布的適應(yīng)性,。本文提出了CAFE,一種緊湊,、自適應(yīng)和低延遲的嵌入壓縮框架,,可以同時(shí)滿足上述要求。CAFE的設(shè)計(jì)理念是動(dòng)態(tài)地為重要的特征(稱(chēng)為熱特征)分配更多的內(nèi)存資源,,為不重要的特征分配更少的內(nèi)存,。在CAFE中,我們提出了一種快速且輕量級(jí)的草圖數(shù)據(jù)結(jié)構(gòu),,名為HotSketch,,用于捕獲特征重要性并實(shí)時(shí)識(shí)別熱特征。對(duì)于每個(gè)熱特征,,我們?yōu)槠浞峙湮ㄒ坏那度耄?/span>對(duì)于非熱門(mén)特征,,我們使用哈希嵌入技術(shù)允許多個(gè)特征共享一個(gè)嵌入。在該設(shè)計(jì)理念下,,我們進(jìn)一步提出了多級(jí)哈希嵌入框架來(lái)優(yōu)化非熱門(mén)特征的嵌入表,。我們從理論上分析了HotSketch的準(zhǔn)確性,并分析了模型的收斂性,。實(shí)驗(yàn)表明,,CAFE顯著優(yōu)于現(xiàn)有的嵌入壓縮方法,在10000倍的壓縮比下,,在Criteo Kaggle數(shù)據(jù)集和CriteoTB數(shù)據(jù)集上的測(cè)試AUC分別提高了3.92%和3.68%,。
一、問(wèn)題背景
近年來(lái),,嵌入技術(shù)廣泛應(yīng)用于數(shù)據(jù)庫(kù)領(lǐng)域,,其中深度學(xué)習(xí)推薦模型(DLRM)是嵌入技術(shù)最重要的應(yīng)用之一,。典型的DLRM將分類(lèi)特征向量化為可學(xué)習(xí)的嵌入,然后將嵌入與其他數(shù)值特征一起喂給下游神經(jīng)網(wǎng)絡(luò),。最近,,嵌入表的內(nèi)存需求隨著DLRM分類(lèi)特征數(shù)量的指數(shù)級(jí)增長(zhǎng)而增長(zhǎng),,給各種應(yīng)用帶來(lái)了巨大的存儲(chǔ)挑戰(zhàn),。在本文中,我們重點(diǎn)關(guān)注壓縮超大規(guī)模DLRM的嵌入表,。DLRM有離線訓(xùn)練和在線訓(xùn)練兩種范式,。離線訓(xùn)練時(shí),預(yù)先收集訓(xùn)練數(shù)據(jù),,并在整個(gè)訓(xùn)練過(guò)程后部署模型以供使用,。在線訓(xùn)練中,訓(xùn)練數(shù)據(jù)是實(shí)時(shí)生成的,,模型同時(shí)更新參數(shù)并服務(wù)請(qǐng)求,。本文主要針對(duì)在線訓(xùn)練的場(chǎng)景,因?yàn)樵诰€訓(xùn)練的難度更大,,且在線訓(xùn)練的壓縮方法可以直接應(yīng)用于離線訓(xùn)練,。在線訓(xùn)練中的嵌入壓縮有三個(gè)重要的設(shè)計(jì)要求:
- 高內(nèi)存效率。為了在內(nèi)存限制內(nèi)保持模型質(zhì)量,,一種方案是使用分布式實(shí)例,,但它們會(huì)帶來(lái)大量的通信開(kāi)銷(xiāo)。此外,,嵌入表的訓(xùn)練和部署通常發(fā)生在存儲(chǔ)容量較小的邊緣或終端設(shè)備上,,使得內(nèi)存問(wèn)題更加嚴(yán)重。另一方面,,由于模型質(zhì)量直接影響利潤(rùn),即使AUC(ROC 曲線下面積)0.001的微小變化也會(huì)帶來(lái)相當(dāng)大的對(duì)利潤(rùn)的影響,。因此,,我們需要保持模型質(zhì)量的內(nèi)存高效壓縮方法。
- 低延遲,。延遲是服務(wù)質(zhì)量的關(guān)鍵指標(biāo),,因此嵌入的壓縮方法必須足夠快,以避免引入顯著的延遲,。
- 對(duì)數(shù)據(jù)分布變化的適應(yīng)性,。在線訓(xùn)練中,數(shù)據(jù)分布并不像離線訓(xùn)練那樣固定,,一般會(huì)隨著時(shí)間動(dòng)態(tài)變化,。我們需要適合在線訓(xùn)練的自適應(yīng)壓縮方法,。
現(xiàn)有的行壓縮方法可以分為基于哈希和自適應(yīng)方法兩類(lèi)?;诠5?/span>方法利用簡(jiǎn)單的哈希函數(shù)將特征映射到具有沖突的嵌入中[1],,盡管它們簡(jiǎn)單易用,但預(yù)先確定的哈希函數(shù)會(huì)扭曲特征的語(yǔ)義信息,,導(dǎo)致模型精度大幅下降,;集成特征頻率信息[2]可以提高離線訓(xùn)練中基于哈希方法的模型質(zhì)量,但不能應(yīng)用于在線訓(xùn)練,。自適應(yīng)方法在訓(xùn)練過(guò)程中識(shí)別重要特征以適應(yīng)在線訓(xùn)練[3],,但現(xiàn)有方法的壓縮率受到重要性分?jǐn)?shù)存儲(chǔ)的限制,導(dǎo)致內(nèi)存效率較低,,且額外的檢查,、采樣操作會(huì)增加整體延遲??傊?,現(xiàn)有方法無(wú)法同時(shí)滿足所有的三個(gè)關(guān)鍵要求。
二,、CAFE設(shè)計(jì)方案
1. 總體流程
我們提出的嵌入框架CAFE能夠同時(shí)滿足高內(nèi)存效率,、低延遲、適應(yīng)數(shù)據(jù)分布動(dòng)態(tài)變化三個(gè)要求,。CAFE的核心思想是動(dòng)態(tài)區(qū)分重要特征(稱(chēng)為熱特征)和不重要特征(稱(chēng)為非熱特征),,并為熱特征分配更多的資源。具體來(lái)說(shuō),,根據(jù)我們的理論推導(dǎo),,我們使用梯度的L2范數(shù)定義特征的重要性得分。我們觀察到,,在大多數(shù)訓(xùn)練數(shù)據(jù)中,,特征重要性遵循高度傾斜的分布,其中大多數(shù)特征的重要性得分較小,,只有一小部分熱門(mén)特征非常重要,。如圖1所示,Criteo Kaggle數(shù)據(jù)集和CriteoTB數(shù)據(jù)集中的特征重要性分布分別近似參數(shù)1.05和1.1的Zipf分布,。因此,,CAFE為熱點(diǎn)特征的嵌入分配更多的內(nèi)存,為非熱點(diǎn)特征的嵌入分配更少的內(nèi)存,,從而在嵌入表的內(nèi)存使用量不變的情況下顯著提高模型質(zhì)量,。 圖2是CAFE框架的示意圖,在CAFE 中,我們提出了一種新穎的HotSketch算法,,用于實(shí)時(shí)記錄top-k熱特征的重要性,。在每次訓(xùn)練迭代中,我們首先在HotSketch里查詢(xún)輸入樣本中的每個(gè)特征,,重要性分?jǐn)?shù)超過(guò)閾值的視為熱門(mén)特征,;然后我們分別查找熱門(mén)特征和非熱門(mén)特征的嵌入,我們給熱門(mén)特征分配唯一的嵌入,,而讓多個(gè)非熱門(mén)特征共享一個(gè)嵌入,;隨著訓(xùn)練數(shù)據(jù)分布的變化,熱門(mén)特征和非熱門(mén)特征之間可以互相遷移,;在神經(jīng)網(wǎng)絡(luò)反向階段,,我們使用特征的梯度范數(shù)來(lái)更新特征重要性。
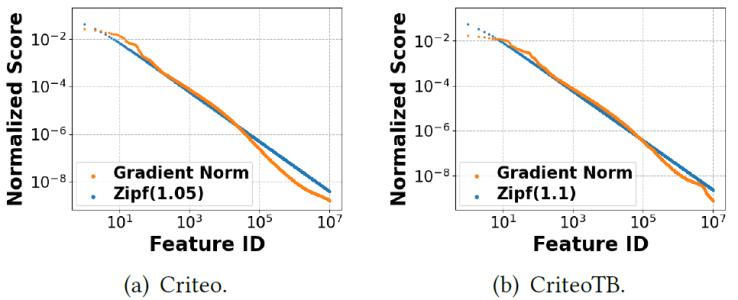
圖1. 特征重要性分布

圖2. CAFE示意圖
2. HotSketch算法
HotSketch算法旨在訓(xùn)練中識(shí)別高重要性分?jǐn)?shù)的熱門(mén)特征,,這本質(zhì)上是在流數(shù)據(jù)中查找top-k頻繁項(xiàng)(特征)的問(wèn)題,。目前,Space-Saving[4]是解決該問(wèn)題最受認(rèn)可的算法,,它在排序的雙向鏈表中維護(hù)頻繁項(xiàng),,并使用哈希表來(lái)索引。然而,,該哈希表不僅使內(nèi)存使用量增加了一倍,,而且指針操作引起的大量?jī)?nèi)存訪問(wèn)導(dǎo)致時(shí)間效率低下。我們提出的HotSketch刪除了哈希表,,同時(shí)仍然保持o(1)時(shí)間復(fù)雜度,,并很好地繼承了Space-Saving的理論結(jié)果。
數(shù)據(jù)結(jié)構(gòu):如圖3所示,,HotSketch由多個(gè)桶組成,,我們使用哈希函數(shù)將特征映射到桶中。 每個(gè)桶包含多個(gè)槽,,其中每個(gè)槽都存儲(chǔ)一個(gè)特征及其重要性分?jǐn)?shù),。
插入:對(duì)于每個(gè)傳入特征,我們首先計(jì)算哈希函數(shù)來(lái)定位桶,,并遇到三種可能的情況:(1) 該特征記錄在桶中,,我們將新分?jǐn)?shù)添加到其重要性得分上;(2)桶中沒(méi)有記錄該特征且存在空槽,,那么我們將該特征和分?jǐn)?shù)插入到空槽中;(3)桶已滿且未記錄該特征,,那么我們找到得分最小的特征替換為插入的特征并添加分?jǐn)?shù),。
討論:HotSketch具有以下優(yōu)點(diǎn):(1)HotSketch插入速度快,具有o(1) 時(shí)間復(fù)雜度,并且只有一次內(nèi)存訪問(wèn),;(2) HotSketch內(nèi)存效率高,,它不存儲(chǔ)指針,并且短暫冷啟動(dòng)后不會(huì)出現(xiàn)空槽,;(3)HotSketch對(duì)硬件友好,,可以通過(guò)多線程和SIMD進(jìn)行加速,從而實(shí)現(xiàn)數(shù)據(jù)并行性,。

圖3. HotSketch示意圖
3. 遷移策略
在DLRM的在線訓(xùn)練過(guò)程中,,特征重要性的分布隨著數(shù)據(jù)分布的變化而波動(dòng),這意味著在整個(gè)訓(xùn)練過(guò)程中熱點(diǎn)特征并不是恒定的,。HotSketch已經(jīng)記錄了特征重要性,,自然可以通過(guò)嵌入表之間的嵌入遷移來(lái)支持動(dòng)態(tài)熱特征。我們?cè)O(shè)置了一個(gè)閾值來(lái)區(qū)分熱點(diǎn)特征,,幾乎每個(gè)首次達(dá)到HotSketch的特征都被視為非熱門(mén)特征,。當(dāng)非熱門(mén)特征的重要性得分超過(guò)閾值時(shí),它會(huì)轉(zhuǎn)變?yōu)闊衢T(mén)特征,,并且其嵌入將從共享表遷移出來(lái),,確保特征的表示在整個(gè)訓(xùn)練過(guò)程中保持平滑;相反,,HotSketch中特征的重要性會(huì)隨時(shí)間進(jìn)行衰減,,當(dāng)熱門(mén)特征的重要性得分低于閾值時(shí),它就變成非熱門(mén)特征,,考慮到新遷移的非熱特征不再重要,,因此我們簡(jiǎn)單地忽略其原始的獨(dú)占嵌入,而使用共享嵌入,。通過(guò)在HotSketch中設(shè)置合適的閾值,,我們能夠保持適度的遷移頻率從而使模型適應(yīng)分布的變化,而不會(huì)對(duì)收斂和延遲產(chǎn)生負(fù)面影響,。
4. 多級(jí)哈希嵌入
非熱特征的數(shù)量遠(yuǎn)超熱門(mén)特征,,鑒于這些非熱特征的重要性得分也符合高度傾斜的Zipf分布,因此我們可以根據(jù)其重要性進(jìn)一步分隔并分配不同的哈希嵌入表,。如圖4所示,,我們將非熱門(mén)特征劃分為不同重要性級(jí)別,并為它們分配來(lái)自多個(gè)表的不同數(shù)量的嵌入,。簡(jiǎn)單起見(jiàn),,我們關(guān)注2級(jí)哈希嵌入,其中非熱特征分為中等特征和冷特征,。我們擴(kuò)展了HotSketch的功能,,以估計(jì)中等特征的重要性分?jǐn)?shù),。由于中等特征比冷特征更重要,我們賦予它們兩個(gè)不同哈希嵌入表中的兩個(gè)嵌入向量,,而冷特征僅查找單個(gè)嵌入向量,。
圖4展示了一個(gè)示例。(1)輸入特征f1,、f2,、f3中,f1的得分大于熱閾值,,f2的得分大于中閾值,,f3的得分低于閾值,因此它們分別被分為熱特征,、中特征和冷特征,;(2) 熱特征和冷特征查找嵌入向量的方式不變;(3)中特征從兩個(gè)哈希嵌入表中查找兩個(gè)嵌入向量,,并通過(guò)池化過(guò)程獲得最終的嵌入,。為了確保訓(xùn)練過(guò)程保持平滑,當(dāng)一個(gè)特征在中類(lèi)和冷類(lèi)之間遷移時(shí),,它總是從第一個(gè)嵌入表中檢索相同的嵌入向量,。對(duì)于池化操作,在實(shí)踐中,,我們發(fā)現(xiàn)嵌入的簡(jiǎn)單求和效果很好,,因?yàn)樘卣鞯那度胂蛄靠偸窃谙嗤姆较蛏细隆6嗉?jí)哈希嵌入的設(shè)計(jì)基于這樣的觀察:唯一嵌入是一種沒(méi)有信息丟失的綜合表示,,而對(duì)于哈希嵌入,,涉及的嵌入數(shù)量越多,沖突越少,,信息量越多,。

圖4. 多級(jí)哈希嵌入示意圖
三、實(shí)現(xiàn)
我們將CAFE實(shí)現(xiàn)為基于PyTorch的插件嵌入層模塊,,可以直接替換任何基于PyTorch的推薦模型中的原始Embedding模塊,。
CAFE后端:我們用C++實(shí)現(xiàn)HotSketch算法以減少總體延遲,并使用PyTorch實(shí)現(xiàn)CAFE的其余部分,。我們HotSketch中桶的數(shù)量設(shè)置為預(yù)先確定的熱門(mén)特征數(shù)量,,每個(gè)桶有4個(gè)槽;我們對(duì)所有特征字段使用一個(gè)HotSketch結(jié)構(gòu),,而不是每個(gè)字段一個(gè)結(jié)構(gòu),,因?yàn)榭缱侄蔚臒衢T(mén)特征分布不明確,最好直接用重要性分?jǐn)?shù)來(lái)處理,。
容錯(cuò)性:我們將所有HotSketch的狀態(tài)注冊(cè)為CAFE的PyTorch模塊中的buffer,,使其可以與模型參數(shù)一起保存和加載,。這種簡(jiǎn)單的設(shè)計(jì)不需要額外的修改,,使帶有CAFE的DLRM能夠使用檢查點(diǎn)進(jìn)行訓(xùn)練和推理,。
內(nèi)存管理:考慮到HotSketch不是計(jì)算密集型任務(wù),我們將整個(gè)HotSketch結(jié)構(gòu)放在CPU上,。CAFE的嵌入模塊基于PyTorch運(yùn)算符構(gòu)建,,可以在任何支持PyTorch的加速器(包括 CPU、GPU)上運(yùn)行,。
四,、實(shí)驗(yàn)結(jié)果
我們用三個(gè)模型DLRM[5]、WDL[6],、DCN[7]在四個(gè)數(shù)據(jù)集Criteo,,CriteoTB,Avazu,,KDD12上做了實(shí)驗(yàn),。我們將CAFE與Hash Embedding[1]、Q-R Trick[8],、AdaEmbed[3],、MDE[9]進(jìn)行了比較。
1,、模型質(zhì)量比較
我們用測(cè)試AUC和訓(xùn)練loss分別表示離線和在線場(chǎng)景下的模型質(zhì)量,。如圖5所示,相比Hash Embedding,、Q-R Trick,、MDE方法,CAFE能夠在同樣的壓縮率下達(dá)到最好的模型質(zhì)量,,且在訓(xùn)練過(guò)程中一直保持更低的訓(xùn)練loss,。AdaEmbed是一個(gè)自適應(yīng)方法,在低壓縮率場(chǎng)景下有很好的效果,,而CAFE不僅能夠達(dá)到更高的壓縮率,,還能在低壓縮率下取得和AdaEmbed相當(dāng)或者更好的效果。
具體而言,,所有方法中只有CAFE和Hash能達(dá)到極限的10000x壓縮率,,而其他方法只能支持較小的壓縮率,例如AdaEmbed和MDE只能支持不到100x的壓縮率,。DLRM模型里,,在Criteo數(shù)據(jù)集上,與Hash和Q-R Trick相比,,CAFE的測(cè)試AUC平均提高了1.79%和0.55%,;在CriteoTB數(shù)據(jù)集上,,改進(jìn)分別為1.304%和0.427%; 在KDD12數(shù)據(jù)集上,,改進(jìn)分別為1.86%和3.80%,。 考慮訓(xùn)練loss,與Hash和Q-R Trick相比,,CAFE在Criteo數(shù)據(jù)集上降低了2.31%,、0.72%,在CriteoTB數(shù)據(jù)集上降低了1.35%,、0.59%,,在Avazu數(shù)據(jù)集上降低了3.34%、0.76%,。與AdaEmbed相比,,CAFE在Criteo數(shù)據(jù)集上達(dá)到了幾乎相同的測(cè)試AUC和訓(xùn)練損失,在CriteoTB數(shù)據(jù)集上提升了0.04%的測(cè)試AUC和減少0.12%的訓(xùn)練損失,,在KDD12數(shù)據(jù)集上提升了0.82%的測(cè)試 AUC,,在Avazu數(shù)據(jù)集上的訓(xùn)練損失減少了0.83%。



圖5. 模型質(zhì)量對(duì)比
我們進(jìn)一步查看了多級(jí)哈希嵌入的效果,,如圖6所示,,其中CAFE-ML表示CAFE結(jié)合多級(jí)哈希嵌入。在不同的壓縮比下,,CAFE-ML始終比CAFE表現(xiàn)更好,,測(cè)試AUC提高了0.08%,訓(xùn)練損失降低了0.25%,。CAFE-ML在較小的壓縮比下表現(xiàn)尤其出色,,在100倍壓縮比下幾乎沒(méi)有造成性能下降。這是因?yàn)镃AFE-ML在小壓縮比下為多級(jí)哈希嵌入表分配了更多的內(nèi)存,,使得中等特征的表示更加精確,。
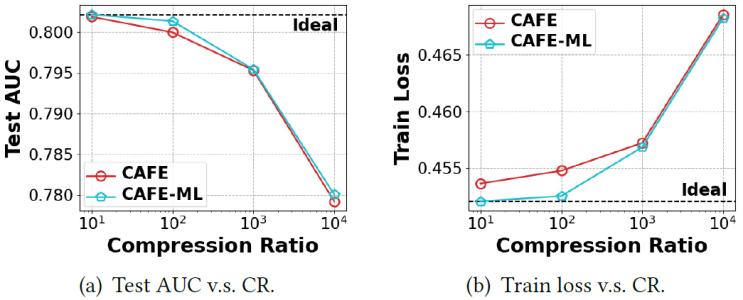
圖6. 比較多級(jí)哈希嵌入
2、吞吐量對(duì)比
我們?cè)趫D7中測(cè)試了每種方法的吞吐量,,實(shí)驗(yàn)是在壓縮率為10x的CriteoTB數(shù)據(jù)集上進(jìn)行的,。由于不同方法的數(shù)據(jù)加載時(shí)間和DNN計(jì)算時(shí)間是相同的,因此差異僅在于嵌入層的操作,。與未壓縮的嵌入操作相比,,Hash僅需要額外的模運(yùn)算,因此是訓(xùn)練和推理中最快的方法,。Q-R Trick只額外引入了哈希過(guò)程和嵌入向量的聚合,,而MDE引入了矩陣乘法、但需要更少的內(nèi)存訪問(wèn)來(lái)獲取嵌入?yún)?shù),,因此這兩個(gè)方法也有較高吞吐量,。為了適應(yīng)在線場(chǎng)景,,AdaEmbed和CAFE引入了嵌入的動(dòng)態(tài)調(diào)整,即重新分配或遷移,,從而導(dǎo)致吞吐量降低,。AdaEmbed會(huì)定期采樣數(shù)千個(gè)數(shù)據(jù)來(lái)確定是否重新分配,帶來(lái)較大時(shí)間開(kāi)銷(xiāo),;相比之下,,CAFE在HotSketch中的計(jì)算開(kāi)銷(xiāo)可以忽略不計(jì)。與AdaEmbed相比,,CAFE的訓(xùn)練吞吐量提高了33.97%,推理吞吐量提高了1.20%,。

圖7. 吞吐量對(duì)比
3,、HotSketch評(píng)測(cè)
桶中槽數(shù)的影響(圖8a-b):我們記錄使用不同槽數(shù)的HotSketch的召回率和吞吐量。實(shí)驗(yàn)使用Criteo數(shù)據(jù)集上1000x壓縮率下的熱門(mén)特征數(shù)量作為k,。在圖8a中,,召回隨著存儲(chǔ)變大而增加。根據(jù)我們的理論推導(dǎo)(見(jiàn)論文推論3.5),,給定參數(shù)1.05到1.1的Zipf分布,,每個(gè)桶的最佳槽數(shù)位于11到21。因此,,槽數(shù)為8和16比4和32表現(xiàn)出更好的召回率,。圖 8b中所示的序列化插入(寫(xiě)入)和查詢(xún)(讀取)的吞吐量約為1e7,,比DLRM本身的吞吐大得多,。考慮到我們?cè)趯?shí)踐中可以并行化操作,,HotSketch只占訓(xùn)練和推理的一小部分,。隨著槽數(shù)量的增加,吞吐量會(huì)下降,,因?yàn)樾枰嗟臅r(shí)間在桶內(nèi)進(jìn)行比較,。權(quán)衡召回率和吞吐量,我們?cè)趯?shí)現(xiàn)中采用每個(gè)桶4個(gè)槽,,此時(shí)的模型質(zhì)量已經(jīng)足夠好,。
尋找實(shí)時(shí)top-k特征(圖8c-d):我們進(jìn)行實(shí)驗(yàn)來(lái)評(píng)估HotSketch在線訓(xùn)練中尋找兩類(lèi)實(shí)時(shí)熱門(mén)特征的性能:最新的top-k特征,以及前一個(gè)時(shí)間窗口中的top-k特征,。這兩類(lèi)top-k特征在在線訓(xùn)練過(guò)程中隨著數(shù)據(jù)分布的變化而變化,,因此可以有效體現(xiàn)HotSketch適應(yīng)動(dòng)態(tài)工作負(fù)載的能力。實(shí)驗(yàn)在 Criteo 上進(jìn)行,,使用6天的在線訓(xùn)練數(shù)據(jù),,滑動(dòng)窗口大小為0.5天,。圖8c-d顯示了HotSketch在不同壓縮比下在線訓(xùn)練時(shí)的實(shí)時(shí)召回率,始終滿足>90%,,這意味著它可以很好地跟上不斷變化的數(shù)據(jù)分布,。

圖8. HotSketch評(píng)測(cè)
五、總結(jié)
在本文中,,我們提出了CAFE,,一種緊湊、自適應(yīng)且快速的嵌入壓縮方法,,它滿足三個(gè)基本設(shè)計(jì)要求:高內(nèi)存效率,、低延遲和對(duì)動(dòng)態(tài)數(shù)據(jù)分布的適應(yīng)性。我們引入了一種輕量數(shù)據(jù)結(jié)構(gòu)HotSketch記錄特征的重要性分?jǐn)?shù),,它產(chǎn)生的時(shí)間開(kāi)銷(xiāo)可以忽略不計(jì),,并且其內(nèi)存消耗明顯低于原始嵌入表。通過(guò)將獨(dú)占嵌入分配給一小組重要特征,,并將共享嵌入分配給其他不太重要的特征,,我們?cè)谟邢薜膬?nèi)存約束內(nèi)實(shí)現(xiàn)了卓越的模型質(zhì)量。為了適應(yīng)在線訓(xùn)練過(guò)程中的動(dòng)態(tài)數(shù)據(jù)分布,,我們采用了基于HotSketch的嵌入遷移策略,。我們通過(guò)多級(jí)哈希嵌入進(jìn)一步優(yōu)化CAFE,創(chuàng)建更細(xì)粒度的重要性組,。實(shí)驗(yàn)結(jié)果表明,,CAFE優(yōu)于現(xiàn)有方法,在Criteo和CriteoTB數(shù)據(jù)集上10000x壓縮比下,,測(cè)試AUC分別提高了3.92%,、3.68%,訓(xùn)練損失降低了4.61%,、3.24%,,在離線訓(xùn)練和在線訓(xùn)練中均表現(xiàn)出優(yōu)異的性能。
實(shí)驗(yàn)室簡(jiǎn)介
北京大學(xué)數(shù)據(jù)與智能實(shí)驗(yàn)室(Data And Intelligence Research Lab at Peking Univeristy,,PKU-DAIR實(shí)驗(yàn)室)由北京大學(xué)計(jì)算機(jī)學(xué)院崔斌教授領(lǐng)導(dǎo),,長(zhǎng)期從事數(shù)據(jù)庫(kù)系統(tǒng)、大數(shù)據(jù)管理與分析,、人工智能等領(lǐng)域的前沿研究,,在理論和技術(shù)創(chuàng)新以及系統(tǒng)研發(fā)上取得多項(xiàng)成果,已在國(guó)際頂級(jí)學(xué)術(shù)會(huì)議和期刊發(fā)表學(xué)術(shù)論文200余篇,,發(fā)布多個(gè)開(kāi)源項(xiàng)目,。課題組同學(xué)曾數(shù)十次獲得包括CCF優(yōu)博、ACM中國(guó)優(yōu)博、北大優(yōu)博,、微軟學(xué)者,、蘋(píng)果獎(jiǎng)學(xué)金、谷歌獎(jiǎng)學(xué)金等榮譽(yù),。PKU-DAIR實(shí)驗(yàn)室持續(xù)與工業(yè)界展開(kāi)卓有成效的合作,,與騰訊、阿里巴巴,、蘋(píng)果,、微軟、百度,、快手,、中興通訊等多家知名企業(yè)開(kāi)展項(xiàng)目合作和前沿探索,解決實(shí)際問(wèn)題,,進(jìn)行科研成果的轉(zhuǎn)化落地,。
載")

評(píng)論 0