








TKDE(IEEE Transactions on Knowledge and Data Engineering)是數(shù)據(jù)庫與數(shù)據(jù)科學(xué)領(lǐng)域影響力最高的學(xué)術(shù)期刊之一,,也是CCF推薦的A類學(xué)術(shù)期刊之一,。PKU-DAIR實(shí)驗(yàn)室論文《OpDiag: Unveiling Database Performance Anomalies through Query Operator Attribution》被TKDE錄用。
OpDiag: Unveiling Database Performance Anomalies through Query Operator Attribution
作者:Shiyue Huang, Ziwei Wang, Yinjun Wu, Yaofeng Tu, Jiankai Wang, Bin Cui
代碼鏈接:https://github.com/hjhhsy120/opdiag
一,、問題背景與動(dòng)機(jī)
在現(xiàn)代數(shù)據(jù)庫應(yīng)用中,,性能異常是影響系統(tǒng)運(yùn)行效率與穩(wěn)定性的重要因素,通常涉及復(fù)雜的診斷與修復(fù)過程,,需要大量的人力開銷?,F(xiàn)有的自動(dòng)診斷工具,例如DBSherlock [1],、ISQUAD [2]等,,大多只能定位異常性能指標(biāo),判斷異常類型,,而無法為異常修復(fù)提供細(xì)節(jié)指導(dǎo),。2023年的研究工作BALANCE [3]具有定位異常查詢的功能,但仍然無法提供更細(xì)粒度的診斷信息,。
以索引缺失異常為例,,DBSherlock的診斷報(bào)告僅包含異常指標(biāo)與異常類型,數(shù)據(jù)庫管理員(DBA)需要進(jìn)行查詢事務(wù)和數(shù)據(jù)庫表的排查,,才能確定哪個(gè)列需要添加索引,。BALANCE能夠定位異常查詢,但是對(duì)于復(fù)雜查詢,,DBA仍然需要排查其涉及的表列,,帶來一定的人力開銷。理想的診斷報(bào)告應(yīng)直接指出哪個(gè)表的哪個(gè)列缺少了索引,,這樣DBA可以直接添加索引進(jìn)行修復(fù),,避免繁瑣的排查與試錯(cuò)過程。
經(jīng)觀察,,性能異常修復(fù)所需的細(xì)粒度信息通常與查詢算子相綁定,。例如,,缺失的索引與相關(guān)表列上的scan算子是綁定的。因此,,我們考慮設(shè)計(jì)數(shù)據(jù)庫性能異常的算子級(jí)診斷方案,,為后續(xù)修復(fù)提供直接指導(dǎo),從而減少人力開銷,,提高運(yùn)維效率,。
二、方法
1. 框架流程
我們提出的算子級(jí)診斷方案OpDiag框架如圖1所示,。該框架分為離線訓(xùn)練與在線診斷兩部分,。
離線訓(xùn)練階段,在數(shù)據(jù)庫上運(yùn)行benchmark,,采集性能指標(biāo)與查詢計(jì)劃信息,,訓(xùn)練query encoder、aggregator和classifier模型,。
在線診斷階段,,data collector持續(xù)從系統(tǒng)中采集性能指標(biāo),輸入classifier模型判斷是否發(fā)生異常,。一旦發(fā)生異常,,data collector立即采集查詢計(jì)劃信息,開始診斷流程,,包括性能指標(biāo)重要度,、可疑查詢、可疑算子的定位,。最后,,輸出診斷報(bào)告,為后續(xù)修復(fù)提供指導(dǎo),。
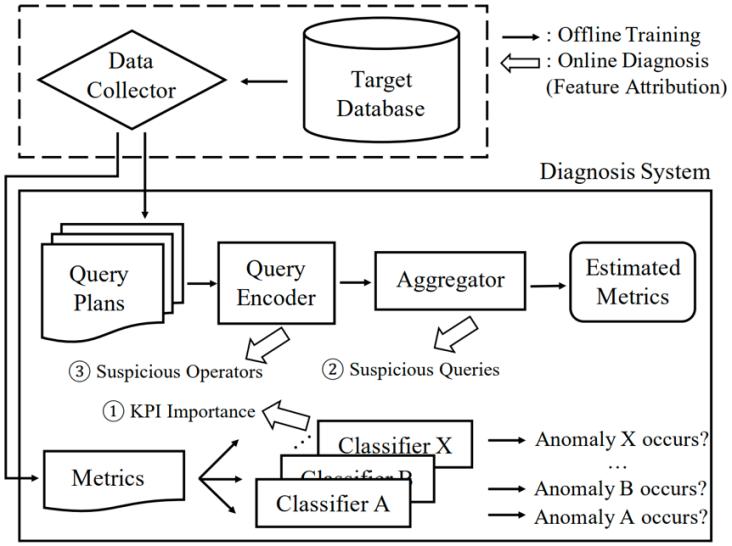
圖1. OpDiag框架
2. 細(xì)粒度建模
OpDiag針對(duì)查詢算子與性能異常之間的關(guān)系,,進(jìn)行了細(xì)粒度建模。
首先,,query encoder以查詢計(jì)劃為輸入,,使用Tree-CNN模型[4]進(jìn)行編碼,輸出單個(gè)查詢的編碼向量,。Tree-CNN的正向計(jì)算過程如圖2所示,,其主要優(yōu)勢在于,在保留樹結(jié)構(gòu)信息的同時(shí),,不會(huì)受到樹深的過度影響,。
其次,aggregator以多個(gè)并發(fā)查詢的編碼向量為輸入,,使用DNN進(jìn)行聚合,,輸出系統(tǒng)性能指標(biāo)的預(yù)測值,。在訓(xùn)練過程中,query encoder與aggregator作為一個(gè)整體進(jìn)行訓(xùn)練,,feature為查詢算子特征,,label為性能指標(biāo)。
最后,,classifier以性能指標(biāo)為輸入,,使用隨機(jī)森林模型,判斷異常是否發(fā)生,。我們對(duì)每個(gè)異常使用一個(gè)二分類器,,以避免互相干擾。訓(xùn)練時(shí),,classifier以真實(shí)性能指標(biāo)為feature,,而不是前面的預(yù)測值,這樣可以引入更多監(jiān)督信號(hào),,提高準(zhǔn)確率。
由此,,OpDiag實(shí)現(xiàn)了查詢算子,、查詢、性能指標(biāo),、異常類型判斷的多層次細(xì)粒度建模,,為后續(xù)的歸因方法奠定了基礎(chǔ)。

圖2. Tree-CNN模型
3. 細(xì)粒度歸因
在線診斷過程中,,OpDiag采用模型解釋算法,,對(duì)現(xiàn)場數(shù)據(jù)與模型進(jìn)行細(xì)粒度歸因,以判斷模型的哪部分輸入對(duì)模型輸出的影響最大,,從而進(jìn)行異常根因的定位,。其流程如圖3所示。
首先,,OpDiag對(duì)classifier的樹模型進(jìn)行解釋,,獲得性能指標(biāo)重要度。
其次,,將aggregator輸出的性能指標(biāo)按重要度加權(quán)求和,,然后使用梯度積分法[5],獲得查詢編碼向量的重要度,。根據(jù)重要度排名,,即可定位可疑查詢。
接著,,選取可疑查詢,,對(duì)query encoder使用梯度積分法進(jìn)行模型解釋,,獲得算子重要度,從而定位可疑算子,。
最后,,綜合各步驟的結(jié)果,輸出完整的診斷報(bào)告,,其中包含異常類型,、異常性能指標(biāo)、可疑查詢,、可疑算子信息,,可為異常修復(fù)提供直接指導(dǎo)。

圖3. 細(xì)粒度歸因流程
三,、實(shí)驗(yàn)結(jié)果
我們選取了三種常見性能異常進(jìn)行評(píng)測,,它們分別是索引缺失、表膨脹,、鎖等待,。在索引缺失與表膨脹的復(fù)現(xiàn)中,我們不僅注入了缺失索引表上的查詢,,還注入了同等規(guī)模的正常表上的查詢作為對(duì)照,。若對(duì)照組的可疑度排名高于目標(biāo)異常查詢,則視為診斷錯(cuò)誤,。
查詢級(jí)診斷結(jié)果如表1所示,。OpDiag能在Top-2查詢中準(zhǔn)確檢出所有案例,比現(xiàn)有工作BALANCE [3]的準(zhǔn)確率更高,。表中之所以有較多的100%,,是因?yàn)槲覀儚?fù)現(xiàn)異常時(shí)注入的查詢相對(duì)于背景負(fù)載較為突出,更容易被定位到,。
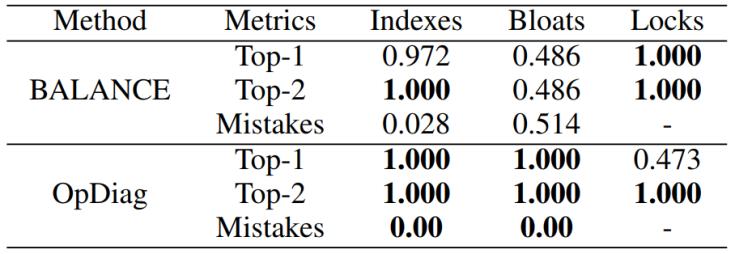
表1. 查詢級(jí)診斷結(jié)果
算子級(jí)診斷方面,,OpDiag同樣能在Top-2查詢中準(zhǔn)確檢出所有案例。圖4展示了一個(gè)索引缺失案例的診斷報(bào)告,。其中排名第一的算子為append,,表示兩表查詢結(jié)果的拼接,不影響修復(fù)過程的判斷,。排名第二的算子為缺索引表A上的scan算子,,順位高于正常表B上的scan算子,驗(yàn)證了結(jié)果的正確性,。

圖4. 診斷報(bào)告案例
除了上述實(shí)驗(yàn)外,,我們還邀請了來自中興通訊的6名專業(yè)DBA,選取了3個(gè)工業(yè)案例,評(píng)估了在有/無OpDiag輔助的條件下,,進(jìn)行診斷與修復(fù)的耗時(shí),。如表2所示,OpDiag可大幅節(jié)省異常處理時(shí)間,。其中,,案例3的算子級(jí)診斷之所以未節(jié)省時(shí)間,是因?yàn)樵摪咐男迯?fù)涉及復(fù)雜的查詢改寫,,導(dǎo)致異常算子信息無法提供幫助,。

表2. 工業(yè)案例節(jié)省時(shí)間百分比
四、總結(jié)
在本研究中,,我們提出了數(shù)據(jù)庫性能異常的算子級(jí)診斷方案OpDiag,。該方案通過細(xì)粒度建模與歸因算法,實(shí)現(xiàn)了可疑查詢與算子的定位,,用于直接指導(dǎo)異常修復(fù),。實(shí)驗(yàn)表明,OpDiag的診斷準(zhǔn)確率高,,優(yōu)于現(xiàn)有方法,,有助于節(jié)省人工修復(fù)時(shí)間,從而提升現(xiàn)代數(shù)據(jù)庫的運(yùn)維效率,。
參考文獻(xiàn):
[1] Dong Young Yoon, Ning Niu, Barzan Mozafari. DBSherlock: A Performance Diagnostic Tool for Transactional Databases. SIGMOD, 2016.
[2] Minghua Ma, Zheng Yin, Shenglin Zhang, Sheng Wang, Christopher Zheng, Xinhao Jiang, Hanwen Hu, Cheng Luo, Yilin Li, Nengjun Qiu, Feifei Li, Changcheng Chen, Dan Pei. Diagnosing Root Causes of Intermittent Slow Queries in Large-Scale Cloud Databases. VLDB, 2020.
[3] Chaoyu Chen, Hang Yu, Zhichao Lei, Jianguo Li, Shaokang Ren, Tingkai Zhang, Silin Hu, Jianchao Wang, Wenhui Shi. BALANCE: Bayesian Linear Attribution for Root Cause Localization. SIGMOD 2023.
[4] Ryan Marcus, Parimarjan Negi, Hongzi Mao, Chi Zhang, Mohammad Alizadeh, Tim Kraska, Olga Papaemmanouil, Nesime Tatbul. Neo: A Learned Query Optimizer. VLDB, 2019.
[5] Mukund Sundararajan, Ankur Taly, Qiqi Yan. Axiomatic Attribution for Deep Networks. ICML, 2017.
實(shí)驗(yàn)室簡介
北京大學(xué)數(shù)據(jù)與智能實(shí)驗(yàn)室(Data And Intelligence Research Lab at Peking Univeristy,,PKU-DAIR實(shí)驗(yàn)室)由北京大學(xué)計(jì)算機(jī)學(xué)院崔斌教授領(lǐng)導(dǎo),長期從事數(shù)據(jù)庫系統(tǒng),、大數(shù)據(jù)管理與分析、人工智能等領(lǐng)域的前沿研究,,在理論和技術(shù)創(chuàng)新以及系統(tǒng)研發(fā)上取得多項(xiàng)成果,,已在國際頂級(jí)學(xué)術(shù)會(huì)議和期刊發(fā)表學(xué)術(shù)論文200余篇,發(fā)布多個(gè)開源項(xiàng)目,。課題組同學(xué)曾數(shù)十次獲得包括CCF優(yōu)博,、ACM中國優(yōu)博、北大優(yōu)博,、微軟學(xué)者,、蘋果獎(jiǎng)學(xué)金、谷歌獎(jiǎng)學(xué)金等榮譽(yù),。PKU-DAIR實(shí)驗(yàn)室持續(xù)與工業(yè)界展開卓有成效的合作,,與騰訊、阿里巴巴,、蘋果,、微軟、百度、快手,、中興通訊等多家知名企業(yè)開展項(xiàng)目合作和前沿探索,,解決實(shí)際問題,進(jìn)行科研成果的轉(zhuǎn)化落地,。
載")

評(píng)論 0