








VLDB 2025 | 多任務(wù)異構(gòu)數(shù)據(jù)感知的LoRA微調(diào)系統(tǒng)
VLDB(International Conference on Very Large Data Bases)是數(shù)據(jù)庫(kù)領(lǐng)域的頂級(jí)國(guó)際學(xué)術(shù)會(huì)議之一,與SIGMOD,、ICDE并稱為數(shù)據(jù)庫(kù)領(lǐng)域的三大頂會(huì),。第51屆VLDB將于2025年9月1日至5日在英國(guó)倫敦召開。PKU-DAIR實(shí)驗(yàn)室論文《LobRA: Multi-tenant Fine-tuning over Heterogeneous Data》被VLDB 2025錄用,,系PKU-DAIR實(shí)驗(yàn)室自研分布式深度學(xué)習(xí)系統(tǒng)河圖Hetu圍繞大模型訓(xùn)練的新成果,。
LobRA: Multi-tenant Fine-tuning over Heterogeneous Data
作者:Sheng Lin, Fangcheng Fu, Haoyang Li, Hao Ge, Xuanyu Wang, Jiawen Niu, Yaofeng Tu, Bin Cui
代碼鏈接:https://github.com/PKU-DAIR/Hetu
PKU-DAIR實(shí)驗(yàn)室近期針對(duì)異構(gòu)模型和數(shù)據(jù)負(fù)載的優(yōu)化已開展了一系列相關(guān)工作:
- HotSPa [SOSP’24]: https://dl.acm.org/doi/10.1145/3694715.3695969
- Malleus [SIGMOD’25]: https://arxiv.org/abs/2410.13333
- FlexSP [ASPLOS’25]: https://arxiv.org/abs/2412.01523
- Hydraulis: https://arxiv.org/abs/2412.07894
- ByteScale: ?https://arxiv.org/abs/2502.21231
1. 背景與挑戰(zhàn)
隨著基于Transformer的預(yù)訓(xùn)練模型發(fā)展,模型尺寸不斷擴(kuò)大,,下游應(yīng)用對(duì)微調(diào)的需求不斷增長(zhǎng),。云廠商通常提供“模型即服務(wù)”(Model as a Service, MaaS)的架構(gòu),允許用戶上傳數(shù)據(jù)集完成個(gè)性化的微調(diào)請(qǐng)求,。為了減小多微調(diào)任務(wù)的執(zhí)行開銷,,LoRA[1] 作為一種參數(shù)高效微調(diào)技術(shù)被廣泛應(yīng)用,,減小模型微調(diào)所需的顯存并提高效率,。鑒于租戶的微調(diào)請(qǐng)求通?;谕粋€(gè)預(yù)訓(xùn)練模型,同時(shí)服務(wù)多租戶的微調(diào)請(qǐng)求成為提高服務(wù)效率的關(guān)鍵,。然而,,現(xiàn)有的微調(diào)框架如NeMo 和 mLoRA[2] 都假設(shè)訓(xùn)練負(fù)載是同構(gòu)的(即所有序列長(zhǎng)度一致),并根據(jù)數(shù)據(jù)集內(nèi)的最長(zhǎng)序列進(jìn)行資源配置和并行策略選擇,,在實(shí)踐中無(wú)法達(dá)到整體訓(xùn)練效率最優(yōu),。
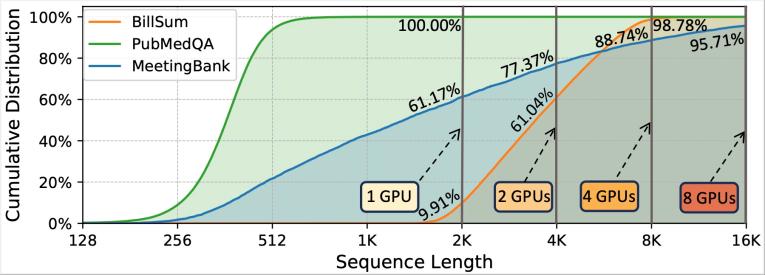 圖1:多租戶任務(wù)數(shù)據(jù)集中序列長(zhǎng)度的長(zhǎng)尾分布
圖1:多租戶任務(wù)數(shù)據(jù)集中序列長(zhǎng)度的長(zhǎng)尾分布
具體而言,在實(shí)際的多租戶微調(diào)請(qǐng)求服務(wù)中,,不同租戶的微調(diào)數(shù)據(jù)集之間具有異構(gòu)性,。如圖1所示,一方面,,不同任務(wù)類型的數(shù)據(jù)集的序列長(zhǎng)度不同,,例如常見的對(duì)話數(shù)據(jù)集以短序列為主,而總結(jié)類數(shù)據(jù)集則以長(zhǎng)序列為主,;另一方面,,在同時(shí)服務(wù)多個(gè)微調(diào)請(qǐng)求時(shí),多任務(wù)數(shù)據(jù)集整體服從長(zhǎng)尾分布,,即存在大量短序列和少量長(zhǎng)序列,。
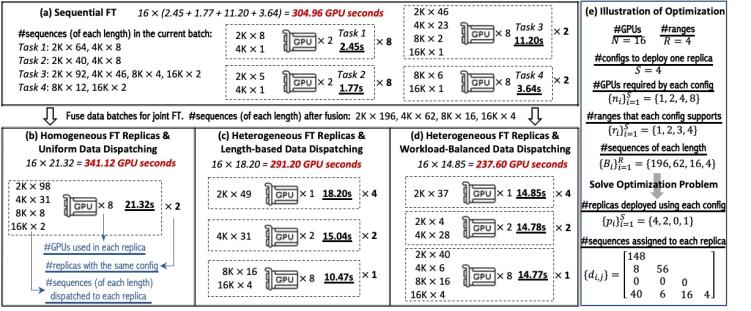
圖2:多任務(wù)微調(diào)下不同執(zhí)行方案及相應(yīng)卡時(shí)的示例
在分布式微調(diào)時(shí),對(duì)數(shù)據(jù)并行,、模型并行等并行策略的選擇會(huì)導(dǎo)致不同的內(nèi)存消耗,、通信開銷和執(zhí)行效率。如圖2(a)和圖2(b)所示,,在同時(shí)服務(wù)多租戶微調(diào)任務(wù)時(shí),,如果簡(jiǎn)單地將所有數(shù)據(jù)合并且采用同構(gòu)策略,需要的卡時(shí)反而比順序跑要更長(zhǎng),,而在圖2(c)和圖2(d)中,,利用同時(shí)存在不同模型并行度的異構(gòu)策略,能更高效地處理異構(gòu)數(shù)據(jù)負(fù)載,。
2. 方法
以此為出發(fā)點(diǎn),,我們提出了異構(gòu)微調(diào)系統(tǒng)LobRA,通過異構(gòu)的并行策略部署來(lái)處理不同租戶任務(wù)之間的異構(gòu)數(shù)據(jù)負(fù)載,。圖2(d)展示了一個(gè)簡(jiǎn)單的例子,,我們的系統(tǒng)會(huì)在微調(diào)開始前根據(jù)多任務(wù)的數(shù)據(jù)分布情況確定靜態(tài)的并行策略方案,并在每輪訓(xùn)練迭代中根據(jù)工作負(fù)載的異構(gòu)特征進(jìn)行負(fù)載均衡的數(shù)據(jù)分發(fā),,以減少模型等待梯度同步的資源浪費(fèi),。這種基于異構(gòu)理念設(shè)計(jì)的訓(xùn)練范式能夠讓異構(gòu)負(fù)載在各自的顯存約束內(nèi)選擇合適的模型并行方案,從而達(dá)到整體的高效訓(xùn)練,。
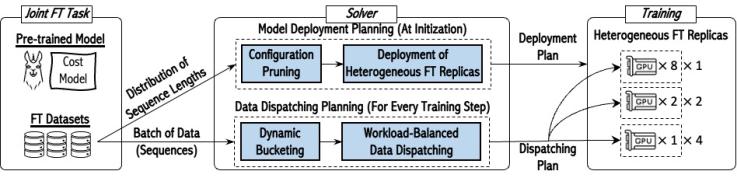
圖3:LobRA系統(tǒng)架構(gòu)圖
圖3展示了LobRA的系統(tǒng)架構(gòu)圖,,其由求解器和異構(gòu)訓(xùn)練模塊組成,。我們將求解器分為兩個(gè)階段:靜態(tài)的并行策略部署求解(Model Deployment Planning)和動(dòng)態(tài)的數(shù)據(jù)分發(fā)求解(Data Dispatching Planning)。
靜態(tài)階段根據(jù)多租戶任務(wù)的數(shù)據(jù)集分布將策略求解建模為一個(gè)混合整數(shù)非線性規(guī)劃(MINLP)問題,,并通過策略剪枝(Configuration Pruning)加速求解過程,,最終得到并行策略部署方案。
動(dòng)態(tài)階段則首先對(duì)每輪迭代的訓(xùn)練數(shù)據(jù)進(jìn)行動(dòng)態(tài)分桶(Dynamic Bucketing),,通過動(dòng)態(tài)規(guī)劃算法減少padding,,并將分桶結(jié)果交付給求解器給出在不同模型并行組上實(shí)現(xiàn)負(fù)載均衡的數(shù)據(jù)分發(fā)策略(Workload-Balanced Data Dispatching)。動(dòng)態(tài)階段的求解器將數(shù)據(jù)分發(fā)建模為線性規(guī)劃問題,,從而能夠在運(yùn)行時(shí)快速求解,。值得一提的是,LobRA 將數(shù)據(jù)分發(fā)求解與訓(xùn)練過程解耦并行,,從而隱藏求解器的時(shí)間開銷,。
3. 實(shí) 驗(yàn)
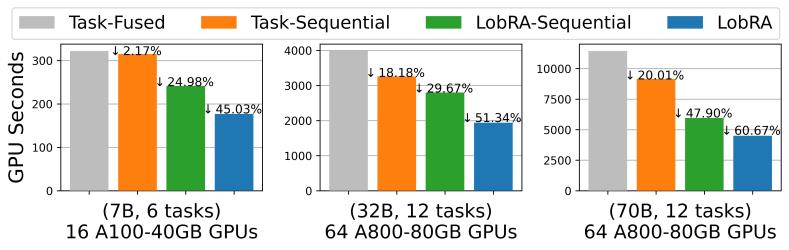 圖4:LobRA與其他執(zhí)行方案的端到端性能實(shí)驗(yàn)對(duì)比
圖4:LobRA與其他執(zhí)行方案的端到端性能實(shí)驗(yàn)對(duì)比
我們構(gòu)建了面向多租戶LoRA微調(diào)任務(wù)的訓(xùn)練框架LobRA,通過高效的多租戶異構(gòu)數(shù)據(jù)處理,,支持在70B的大模型上同時(shí)服務(wù)10個(gè)以上的多租戶微調(diào)請(qǐng)求,,并在多個(gè)數(shù)據(jù)集、多種大小模型上進(jìn)行實(shí)驗(yàn),。圖4展示了 LobRA 與不同的執(zhí)行方案的性能對(duì)比,,實(shí)驗(yàn)結(jié)果表明,我們的系統(tǒng)相比于同構(gòu)混合執(zhí)行(Task-Fused)減少了最多60.67%的卡時(shí),,且與同構(gòu)順序執(zhí)行(Task-Sequential)和異構(gòu)順序執(zhí)行(LobRA-Sequential)等方案相比有更高的訓(xùn)練效率,。
4. 總 結(jié)
在本研究中,我們提出了面向多租戶LoRA微調(diào)任務(wù)的訓(xùn)練系統(tǒng)LobRA,,該系統(tǒng)通過靜態(tài)的異構(gòu)并行策略部署和動(dòng)態(tài)的負(fù)載均衡數(shù)據(jù)分發(fā)方法實(shí)現(xiàn)了多任務(wù)異構(gòu)數(shù)據(jù)負(fù)載的高效微調(diào),。實(shí)驗(yàn)表明,LobRA能更好地節(jié)省多任務(wù)服務(wù)的卡時(shí),,優(yōu)于現(xiàn)有的執(zhí)行方案,。
參考文獻(xiàn):
[1] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. ICML, 2022.
[2] Zhengmao Ye, Dengchun Li, Zetao Hu, Tingfeng Lan, Jian Sha, Sicong Zhang, Lei Duan, Jie Zuo, Hui Lu, Yuanchun Zhou, Mingjie Tang. mLoRA: Fine-Tuning LoRA Adapters via Highly-Efficient Pipeline Parallelism in Multiple GPUs. VLDB, 2025.
實(shí)驗(yàn)室簡(jiǎn)介
北京大學(xué)數(shù)據(jù)與智能實(shí)驗(yàn)室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR實(shí)驗(yàn)室)由北京大學(xué)計(jì)算機(jī)學(xué)院崔斌教授領(lǐng)導(dǎo),,長(zhǎng)期從事數(shù)據(jù)庫(kù)系統(tǒng),、大數(shù)據(jù)管理與分析、人工智能等領(lǐng)域的前沿研究,,在理論和技術(shù)創(chuàng)新以及系統(tǒng)研發(fā)上取得多項(xiàng)成果,,已在國(guó)際頂級(jí)學(xué)術(shù)會(huì)議和期刊發(fā)表學(xué)術(shù)論文200余篇,發(fā)布多個(gè)開源項(xiàng)目,。課題組同學(xué)曾數(shù)十次獲得包括CCF優(yōu)博,、ACM中國(guó)優(yōu)博、北大優(yōu)博,、微軟學(xué)者,、蘋果獎(jiǎng)學(xué)金,、谷歌獎(jiǎng)學(xué)金等榮譽(yù)。PKU-DAIR實(shí)驗(yàn)室持續(xù)與工業(yè)界展開卓有成效的合作,,與騰訊、阿里巴巴,、蘋果,、微軟、百度,、快手,、中興通訊等多家知名企業(yè)開展項(xiàng)目合作和前沿探索,解決實(shí)際問題,,進(jìn)行科研成果的轉(zhuǎn)化落地,。
載")

評(píng)論 0