








KDD (ACM SIGKDD Conference on Knowledge Discovery and Data Mining ) 是機(jī)器學(xué)習(xí),、人工智能與大數(shù)據(jù)分析領(lǐng)域頂級(jí)國際會(huì)議之一,,與ICML、NeurIPS,、CVPR 并稱為人工智能方向的頂級(jí)會(huì)議,。KDD 2025將于8月3日—8月7日在加拿大多倫多舉行,。PKU-DAIR實(shí)驗(yàn)室論文《LLMs are Noisy Oracles! LLM-based Noise-aware Graph Active Learning for Node Classification》被KDD 2025錄用,。
LLMs are Noisy Oracles! LLM-based Noise-aware Graph Active Learning for Node Classification
作者:Zeang Sheng, Weiyang Guo, Yingxia Shao, Wentao Zhang, Bin Cui
Github鏈接:https://github.com/PKU-DAIR/Noisy_LLM_Oracle
一、問題背景與動(dòng)機(jī)
圖神經(jīng)網(wǎng)絡(luò)(Graph Neural Networks, GNNs)因其出色的鄰域信息捕捉能力,,被廣泛應(yīng)用于節(jié)點(diǎn)分類,、鏈接預(yù)測(cè)和藥物發(fā)現(xiàn)等圖學(xué)習(xí)任務(wù)中,。與其他深度學(xué)習(xí)模型類似,GNN需要依賴充足的高質(zhì)量標(biāo)注數(shù)據(jù)進(jìn)行訓(xùn)練,,才能在下游任務(wù)中表現(xiàn)優(yōu)異,。然而,圖結(jié)構(gòu)數(shù)據(jù)中樣本間復(fù)雜的連接關(guān)系使得人工標(biāo)注的難度遠(yuǎn)高于圖像或文本數(shù)據(jù),,導(dǎo)致標(biāo)注成本高昂,。例如,主流基準(zhǔn)大規(guī)模圖數(shù)據(jù)集OGB[1]中的ogbn-papers100M僅有約1%的節(jié)點(diǎn)被標(biāo)注,。
近年來,,大語言模型(Large Language Models, LLMs)在文本任務(wù)中展現(xiàn)的零樣本能力引發(fā)了廣泛關(guān)注。已有研究[2]嘗試將圖數(shù)據(jù)轉(zhuǎn)化為文本形式后利用LLM進(jìn)行圖學(xué)習(xí)任務(wù),,盡管其性能尚未超越專有GNN模型,,但展現(xiàn)了良好的泛化能力?;诖?,一個(gè)近期工作LLM-GNN[3]提出用LLM替代人工標(biāo)注以低成本緩解數(shù)據(jù)稀缺問題。該方案通過后置過濾(Post Filtering, PS)剔除LLM不確定的標(biāo)注,,并采用基于均勻分布假設(shè)的噪聲可感圖主動(dòng)學(xué)習(xí)算法RIM [4]處理標(biāo)注噪聲,。
本文通過實(shí)驗(yàn)分析發(fā)現(xiàn),同一個(gè)LLM在不同數(shù)據(jù)集上的標(biāo)注噪聲分布非常復(fù)雜且和具體數(shù)據(jù)集特征有關(guān),,因此LLM-GNN采用的均勻分布假設(shè)存在局限性,。
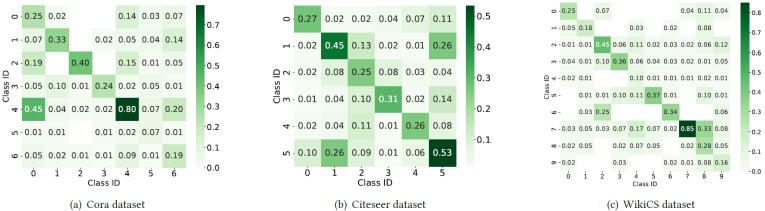
圖1. LLM在不同數(shù)據(jù)集上的標(biāo)注噪聲分布
建模LLM標(biāo)注噪聲分布的難點(diǎn)在于雙重感知需求:1.數(shù)據(jù)集可感:實(shí)驗(yàn)分析表明,,同一LLM在不同數(shù)據(jù)集上會(huì)呈現(xiàn)高度異質(zhì)性的噪聲分布,。這種數(shù)據(jù)集依賴性要求噪聲模型必須動(dòng)態(tài)適配目標(biāo)數(shù)據(jù)集的特性。2. LLM可感:不同LLM因架構(gòu)和訓(xùn)練差異表現(xiàn)出獨(dú)特的標(biāo)注行為特征?,F(xiàn)有研究證實(shí),,某些LLM擅長(zhǎng)結(jié)構(gòu)化關(guān)系推理但在實(shí)體分類中表現(xiàn)不穩(wěn)定,而另一些則相反,。因此,,噪聲模型需精準(zhǔn)捕捉當(dāng)前所用LLM的固有偏差。這一問題的根本矛盾在于:缺乏真實(shí)標(biāo)簽使得傳統(tǒng)校準(zhǔn)方法失效,;簡(jiǎn)單假設(shè)(如均勻分布)無法兼容上述雙重感知需求,。這一矛盾催生了本文的核心研究問題——如何在沒有真值監(jiān)督的條件下,構(gòu)建同時(shí)滿足數(shù)據(jù)集可感與LLM可感的噪聲分布估計(jì)算法,。
二,、DMA框架詳解
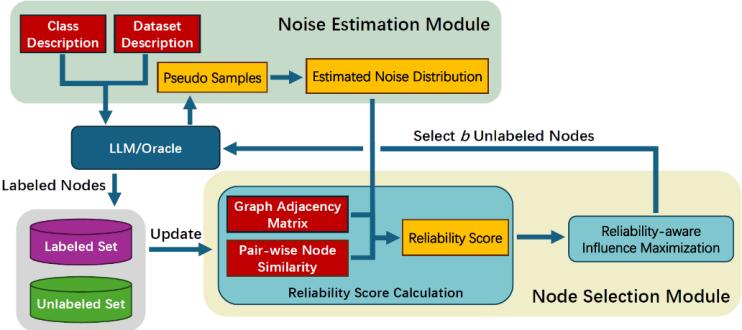
圖2. DMA框架流程圖
1. DMA流程概述:
DMA框架的工作流程概覽如圖2所示。我們構(gòu)建DMA的目的是利用LLM對(duì)圖結(jié)構(gòu)數(shù)據(jù)進(jìn)行標(biāo)注,。具體而言,,DMA接收未標(biāo)注的圖和標(biāo)注預(yù)算B作為輸入,隨后選擇B個(gè)最具價(jià)值的節(jié)點(diǎn)進(jìn)行標(biāo)注,,使得基于標(biāo)注數(shù)據(jù)訓(xùn)練的GNN在下游圖學(xué)習(xí)任務(wù)中表現(xiàn)最優(yōu),。DMA由兩個(gè)核心模塊組成:噪聲估計(jì)模塊和節(jié)點(diǎn)選擇模塊。噪聲估計(jì)模塊負(fù)責(zé)以數(shù)據(jù)集可感和LLM可感的方式,,顯式估計(jì)大語言模型的標(biāo)注噪聲分布,;節(jié)點(diǎn)選擇模塊則利用估計(jì)的噪聲分布計(jì)算各節(jié)點(diǎn)的可靠性分?jǐn)?shù),并通過可靠性感知的影響力最大化策略篩選有價(jià)值節(jié)點(diǎn),。本節(jié)后續(xù)內(nèi)容將詳細(xì)闡述DMA的這兩個(gè)模塊
2. 噪聲估計(jì)模塊:
本文提出一種數(shù)據(jù)集可感與LLM可感的方法,,用于顯式估計(jì)大語言模型的標(biāo)注噪聲分布。我們的設(shè)計(jì)基于以下核心思想:表征相似的類別更易被相互混淆,?;谠撍枷耄肼暪烙?jì)模塊首先確定每個(gè)類別的表征,,進(jìn)而據(jù)此近似推導(dǎo)LLM的標(biāo)注噪聲分布,。相應(yīng)地,噪聲估計(jì)模塊包含兩個(gè)連續(xù)步驟:1)偽樣本生成,,2)噪聲分布計(jì)算,。
1)偽樣本生成:
本步驟旨在為數(shù)據(jù)集中的每個(gè)類別生成偽樣本,其嵌入向量將作為對(duì)應(yīng)類別的表征,。這些偽樣本由用于標(biāo)注的LLM生成以確保與標(biāo)注結(jié)果的一致性(示意圖見圖3),。具體實(shí)現(xiàn)時(shí),我們?yōu)槊總€(gè)類別構(gòu)建包含數(shù)據(jù)集描述和類別描述的提示詞(Prompt),,要求LLM生成最匹配目標(biāo)類別的數(shù)據(jù)樣本,。這樣一來,生成的偽樣本能夠反映基準(zhǔn)LLM對(duì)數(shù)據(jù)集中各類別的理解,,具有數(shù)據(jù)集適應(yīng)性和LLM特異性,。

圖3. 偽樣本生成示例
2)噪聲分布計(jì)算:
本步驟利用前步生成的偽樣本近似LLM的標(biāo)注噪聲分布,。對(duì)于類別,,我們從基準(zhǔn)LLM獲取其偽樣本的嵌入向量作為該類別表征。隨后計(jì)算所有類別對(duì)的余弦相似度矩陣:
隨后通過行歸一化(1-范數(shù))得到標(biāo)準(zhǔn)化矩陣,。根據(jù)“相似表征類別易混淆”的核心思想,,該矩陣衡量了LLM將類別節(jié)點(diǎn)誤標(biāo)注為類別的概率。因此該矩陣即為DMA中估計(jì)的LLM標(biāo)注噪聲分布,,該分布將用于節(jié)點(diǎn)選擇模塊中的節(jié)點(diǎn)可靠性評(píng)分計(jì)算,。
3. 節(jié)點(diǎn)選擇模塊
我們?yōu)镈MA中的節(jié)點(diǎn)選擇模塊設(shè)計(jì)了一個(gè)新的圖主動(dòng)學(xué)習(xí)算法,,該算法基于現(xiàn)有研究RIM進(jìn)行改進(jìn):RIM假設(shè)標(biāo)注噪聲服從均勻分布,并通過計(jì)算節(jié)點(diǎn)可靠性分?jǐn)?shù)實(shí)現(xiàn)可靠節(jié)點(diǎn)選擇,。然而如圖1所示,LLM的標(biāo)注噪聲分布與均勻分布相差甚遠(yuǎn),。因此,,當(dāng)采用LLM進(jìn)行數(shù)據(jù)標(biāo)注時(shí),我們提出的節(jié)點(diǎn)選擇算法進(jìn)一步利用了噪聲估計(jì)模塊中估計(jì)的LLM噪聲分布,,從而實(shí)現(xiàn)更精確的可靠性分?jǐn)?shù)計(jì)算,。
RIM僅針對(duì)已標(biāo)注節(jié)點(diǎn)更新影響力質(zhì)量(Influence Quality),而對(duì)未標(biāo)注節(jié)點(diǎn)則簡(jiǎn)單采用預(yù)設(shè)的標(biāo)注準(zhǔn)確度分?jǐn)?shù)作為其影響力質(zhì)量,。與RIM不同,,DMA的節(jié)點(diǎn)選擇模塊將已標(biāo)注節(jié)點(diǎn)的影響力質(zhì)量分?jǐn)?shù)沿圖中的邊傳遞至全圖所有節(jié)點(diǎn),從而實(shí)現(xiàn)所有節(jié)點(diǎn)影響力質(zhì)量的動(dòng)態(tài)更新,。這種方法能為未標(biāo)注節(jié)點(diǎn)生成更具意義的影響力質(zhì)量評(píng)估,。DMA的更新過程在原理上與PageRank[5]分?jǐn)?shù)計(jì)算具有相似性。DMA的節(jié)點(diǎn)選擇模塊的其余部分沿用了RIM的設(shè)計(jì),,該框架基于社交影響力最大化領(lǐng)域的經(jīng)典研究[6],。其核心思想是:優(yōu)先選擇能夠最大程度擴(kuò)展已標(biāo)注節(jié)點(diǎn)激活范圍的未標(biāo)注節(jié)點(diǎn),圖4給出了一個(gè)簡(jiǎn)略的偽代碼流程,,具體算法流程請(qǐng)參見論文,。

圖4. DMA中節(jié)點(diǎn)選擇算法偽代碼
三、實(shí)驗(yàn)結(jié)果
我們?cè)谖鍌€(gè)常用的圖數(shù)據(jù)集(Cora,、Citeseer,、PubMed、WikiCS,、Ogbn-arxiv)上對(duì)DMA和基線方法在下游節(jié)點(diǎn)分類任務(wù)上的性能進(jìn)行了對(duì)比分析,。我們將節(jié)點(diǎn)選擇預(yù)算B設(shè)置為20乘以各數(shù)據(jù)集的類別數(shù)量?;诿總€(gè)方法生成的標(biāo)注數(shù)據(jù),,我們訓(xùn)練了一個(gè)2層GCN/GAT模型。表1的評(píng)估結(jié)果表明,,我們提出的DMA框架持續(xù)優(yōu)于現(xiàn)有框架,。表1還顯示DMA的性能優(yōu)勢(shì)不受GNN模型選擇的影響。由于DMA主要關(guān)注選擇更可靠的節(jié)點(diǎn),,而LLM-GNN中的DA側(cè)重降低LLM標(biāo)注難度,,二者的關(guān)注點(diǎn)正交,因此兩者可以加以結(jié)合來進(jìn)一步提升下游任務(wù)效果,。表1中DA+DMA在多數(shù)配置下超越原始DMA的評(píng)估結(jié)果,,驗(yàn)證了DA與DMA的成功融合,。在大型Ogbn-arxiv數(shù)據(jù)集評(píng)估時(shí),GraphPart[7]和RIM會(huì)出現(xiàn)"OOT(超時(shí))"問題,,而DMA能成功運(yùn)行,,展現(xiàn)了后者更高的可擴(kuò)展性和運(yùn)行效率。
表1. 節(jié)點(diǎn)分類任務(wù)上的性能對(duì)比,,OOT代表超時(shí)(Out of Time)

為了驗(yàn)證DMA中噪聲估計(jì)模塊的有效性,,我們對(duì)其預(yù)測(cè)的LLM標(biāo)注噪聲分布進(jìn)行了可視化分析。圖5分別展示了Cora和Citeseer數(shù)據(jù)集上的估計(jì)噪聲分布,,同時(shí)提供真實(shí)噪聲分布作為對(duì)比基準(zhǔn),。圖5顯示,估計(jì)結(jié)果基本反映了真實(shí)噪聲分布的核心模式,,這一現(xiàn)象解釋了表1中DMA優(yōu)于基線模型的性能表現(xiàn),。然而,估計(jì)分布與真實(shí)分布之間仍存在差異:例如在Cora數(shù)據(jù)集上,,噪聲估計(jì)模塊認(rèn)為第5類節(jié)點(diǎn)的錯(cuò)誤標(biāo)注概率為0.29,,而其真實(shí)誤標(biāo)概率僅為0.07。這些偏差表明,,未來需要進(jìn)一步改進(jìn)LLM標(biāo)注噪聲分布的估計(jì)精度,。
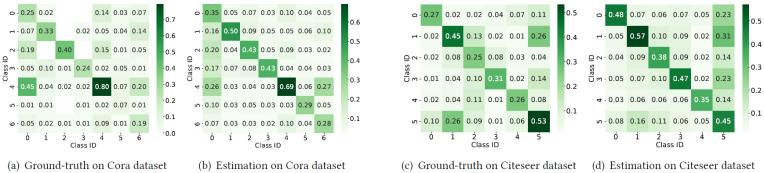
圖5. 估算的噪聲分布與真實(shí)的噪聲分布對(duì)比
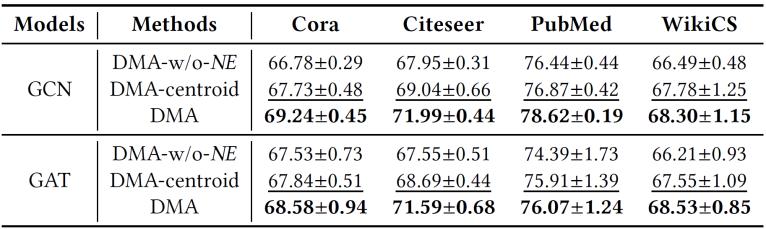
我們提出的DMA框架最核心的貢獻(xiàn)在于:其噪聲估計(jì)模塊以數(shù)據(jù)集可感和LLM可感的方式,顯式建模了LLM的標(biāo)注噪聲分布,。為驗(yàn)證該模塊是否如預(yù)期提升了最終性能,,我們?cè)O(shè)計(jì)了以下實(shí)驗(yàn):定義兩種DMA變體——1)"DMA-w/o-NE":將噪聲估計(jì)模塊中的預(yù)測(cè)噪聲分布替換為均勻分布,通過將均勻噪聲率從0.1到0.5網(wǎng)格搜索后取最高測(cè)試精度作為最終性能,;2)"DMA-centroid":采用節(jié)點(diǎn)特征經(jīng)K-Means聚類生成的質(zhì)心嵌入作為類別表示(假設(shè)該變體可利用真實(shí)標(biāo)簽對(duì)齊質(zhì)心與真實(shí)類別以保證可行性),。表2的實(shí)驗(yàn)結(jié)果表明:完整版DMA在所有評(píng)估配置下均優(yōu)于兩種變體,。DMA相對(duì)DMA-w/o-NE的性能優(yōu)勢(shì),證實(shí)了噪聲估計(jì)模塊預(yù)測(cè)標(biāo)注噪聲分布的有效性;而DMA相對(duì)DMA-centroid的優(yōu)越性,,則源于其與LLM對(duì)數(shù)據(jù)集認(rèn)知的更好對(duì)齊,,這凸顯了以數(shù)據(jù)集可感和LLM可感方式建模噪聲分布的重要性,。
表2. 噪聲估計(jì)模塊的消融實(shí)驗(yàn)
我們對(duì)比了DMA與GraphPart,、RIM在節(jié)點(diǎn)選擇階段的時(shí)間和內(nèi)存消耗。表2展示了在五個(gè)真實(shí)圖數(shù)據(jù)集的評(píng)估結(jié)果,。實(shí)驗(yàn)結(jié)果表明DMA在時(shí)間和內(nèi)存開銷上顯著低于GraphPart,、RIM等強(qiáng)基線框架,尤其在大規(guī)模數(shù)據(jù)集上優(yōu)勢(shì)明顯,。DMA的運(yùn)行時(shí)性能優(yōu)勢(shì)源于我們采用的三項(xiàng)深度優(yōu)化策略:1)使用C++實(shí)現(xiàn)節(jié)點(diǎn)選擇操作,,并采用OpenMP并行計(jì)算各節(jié)點(diǎn)可靠度影響值;2)手動(dòng)構(gòu)建并訪問CSR格式的稀疏鄰接矩陣,,避免直接操作稠密矩陣,;3)為每個(gè)線程維護(hù)小型緩存,,預(yù)讀取并存儲(chǔ)線程專屬的稠密鄰接矩陣以減少冗余內(nèi)存訪問。
表3. 節(jié)點(diǎn)選擇模塊的開銷對(duì)比

四,、總結(jié)
現(xiàn)有工作通過采用大型語言模型(LLM)作為標(biāo)注工具,,實(shí)現(xiàn)了低成本的圖主動(dòng)學(xué)習(xí)。盡管已觀察到LLM的標(biāo)注存在噪聲,,現(xiàn)有工作仍簡(jiǎn)單假設(shè)其噪聲服從均勻分布,。然而,本文通過實(shí)驗(yàn)分析發(fā)現(xiàn),,LLM的標(biāo)注噪聲非常復(fù)雜且與數(shù)據(jù)集具體特征相關(guān),?;诜治鼋Y(jié)果,,我們提出了一種新型噪聲可感圖主動(dòng)學(xué)習(xí)框架DMA。該框架包含兩個(gè)核心模塊:1)噪聲估計(jì)模塊通過LLM生成的偽樣本,,以數(shù)據(jù)集和LLM雙重可感的方式估算標(biāo)注噪聲分布,;2)節(jié)點(diǎn)選擇模塊利用估計(jì)的噪聲分布衡量節(jié)點(diǎn)可靠性,并選擇能最大化可靠影響力的節(jié)點(diǎn),。在五個(gè)公開文本屬性圖數(shù)據(jù)集上的評(píng)估結(jié)果表明,,DMA性能始終優(yōu)于所有基線方法。
參考文獻(xiàn)
[1] Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020. Open Graph Benchmark: Datasets for Machine Learning on Graphs. arXiv preprint arXiv:2005.00687 (2020).
[2] Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. 2024. Graphgpt: Graph instruction tuning for large language models. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 491–500.
[3] Zhikai Chen, Haitao Mao, Hongzhi Wen, Haoyu Han, Wei Jin, Haiyang Zhang, Hui Liu, and Jiliang Tang. 2024. “Label-free Node Classification on Graphs with Large Language Models (LLMs)”. In The Twelfth International Conference on Learning Representations.
[4] Wentao Zhang, Yexin Wang, Zhenbang You, Meng Cao, Ping Huang, Jiulong Shan, Zhi Yang, and Bin Cui. 2021. “Rim: Reliable influence-based active learning on graphs”. Advances in Neural Information Processing Systems 34 (2021), 27978–27990.
[5] Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. 1999. “The PageRank citation ranking: Bringing order to the web”. Technical Report. Stanford infolab.
[6] David Kempe, Jon Kleinberg, and Éva Tardos. 2003. “Maximizing the spread of influence through a social network”. In Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining. 137–146.
[7] Jiaqi Ma, Ziqiao Ma, Joyce Chai, and Qiaozhu Mei. 2023. “Partition-Based Active Learning for Graph Neural Networks”. Transactions on Machine Learning Research (2023).
實(shí)驗(yàn)室簡(jiǎn)介
北京大學(xué)數(shù)據(jù)與智能實(shí)驗(yàn)室(Data And Intelligence Research Lab at Peking Univeristy,,PKU-DAIR實(shí)驗(yàn)室)由北京大學(xué)計(jì)算機(jī)學(xué)院崔斌教授領(lǐng)導(dǎo),,長(zhǎng)期從事數(shù)據(jù)庫系統(tǒng)、大數(shù)據(jù)管理與分析,、人工智能等領(lǐng)域的前沿研究,,在理論和技術(shù)創(chuàng)新以及系統(tǒng)研發(fā)上取得多項(xiàng)成果,已在國際頂級(jí)學(xué)術(shù)會(huì)議和期刊發(fā)表學(xué)術(shù)論文200余篇,,發(fā)布多個(gè)開源項(xiàng)目,。課題組同學(xué)曾數(shù)十次獲得包括CCF優(yōu)博、ACM中國優(yōu)博,、北大優(yōu)博,、微軟學(xué)者、蘋果獎(jiǎng)學(xué)金,、谷歌獎(jiǎng)學(xué)金等榮譽(yù),。PKU-DAIR實(shí)驗(yàn)室持續(xù)與工業(yè)界展開卓有成效的合作,與騰訊,、阿里巴巴,、蘋果、微軟,、百度,、快手,、中興通訊等多家知名企業(yè)開展項(xiàng)目合作和前沿探索,解決實(shí)際問題,,進(jìn)行科研成果的轉(zhuǎn)化落地,。
載")

評(píng)論 0