








?近期,,實(shí)驗(yàn)室碩士研究生段士童作為第一作者的論文“Negating Negatives: Alignment with Human Negative Samples via Distributional Dispreference Optimization”被Findings of EMNLP錄用。該工作首先指出現(xiàn)有的有監(jiān)督微調(diào)方法容易收到人類標(biāo)注偏好數(shù)據(jù)集中噪聲的影響,然后提出了僅僅使用人類標(biāo)注的負(fù)樣本實(shí)現(xiàn)對(duì)齊的任務(wù),。以此為目標(biāo)設(shè)計(jì)了分布級(jí)別優(yōu)化的D2O損失函數(shù),,并從理論證明該損失函數(shù)是實(shí)例級(jí)別優(yōu)化DPO的上界。在多個(gè)開源模型上大量的實(shí)驗(yàn)表明,,D2O在生成質(zhì)量,、減少有害性和信息豐富性方面與最新強(qiáng)基線相當(dāng)或更優(yōu),并且具有更好的訓(xùn)練穩(wěn)定性和更快的收斂速度,。
期刊簡(jiǎn)介

EMNLP 2024(The 2024 Conference on Empirical Methods in Natural Language Processing)是全球自然語言處理領(lǐng)域的頂級(jí)學(xué)術(shù)會(huì)議之一,,該會(huì)議由計(jì)算語言學(xué)協(xié)會(huì)(Association for Computational Linguistics,ACL)主辦,,主要集中于自然語言處理(NLP)的實(shí)證研究和方法,,享有很高的學(xué)術(shù)影響力。該會(huì)議計(jì)劃于2024年11月12日至11月16日在美國佛羅里達(dá)州邁阿密召開,。
論文簡(jiǎn)介
Negating Negatives: 通過分布級(jí)優(yōu)化利用人類標(biāo)注負(fù)樣本實(shí)現(xiàn)大語言模型對(duì)齊

論文鏈接:
https://arxiv.org/pdf/2403.03419
問題引入
大型語言模型(LLMs)在展示出強(qiáng)大的能力的同時(shí),,也帶來了潛在的社會(huì)風(fēng)險(xiǎn)。為了確保LLMs的安全性,,研究者們引入了對(duì)齊技術(shù),,以使其符合人類價(jià)值觀,代其中代表的技術(shù)為基于人類反饋的強(qiáng)化學(xué)習(xí)(Reinforcement Learning from Human Feedback,,RLHF)以及直接偏好優(yōu)化(Direct Preference Optimization,,DPO)。其中強(qiáng)化學(xué)習(xí)利用偏好模型建模人類偏好,,通過強(qiáng)化學(xué)習(xí)來對(duì)齊大語言模型,。DPO算法利用Bradley-Terry模型建模人類偏好,在不用外部顯示偏好模型的情況下,,利用語言模型隱式建模偏好,。
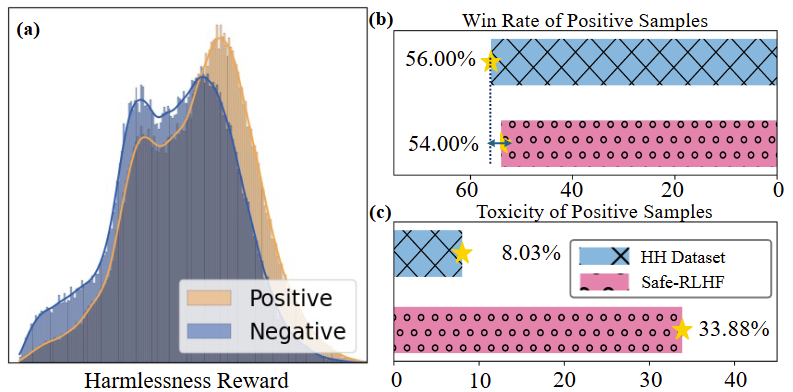
圖 1 (a) HH數(shù)據(jù)集中正樣本和負(fù)樣本之間的差異很小。(b)利用GPT-4進(jìn)行判斷,,正例的勝率較低,。(c)數(shù)據(jù)集正例中存在一定比例的毒性樣本
然而,現(xiàn)有的方法常常依賴于高質(zhì)量的正負(fù)樣本對(duì),。而這些樣本通常是難以獲得的,,一方面,人工標(biāo)注成本較高難以進(jìn)行大規(guī)模標(biāo)注,;另一方面,圖1中展示了我們對(duì)當(dāng)前主流數(shù)據(jù)集進(jìn)行的質(zhì)量分析,,結(jié)果顯示人工標(biāo)注的一致性較低,,訓(xùn)練樣本通常含有噪聲。因此在本工作中,我們提出了一個(gè)新的對(duì)齊任務(wù),,即:僅僅通過人類標(biāo)注的負(fù)樣本,,能否高效地實(shí)現(xiàn)對(duì)齊,在盡量減少模型有用性損失的情況下,,盡可能降低模型的有害性,。
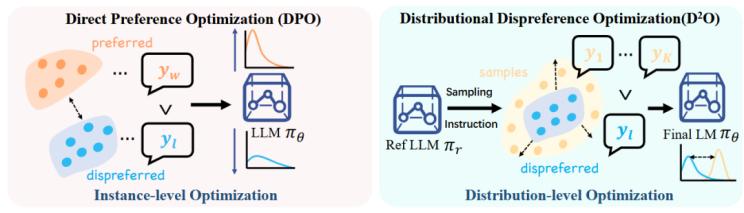
圖2 DPO和D2O對(duì)齊流程對(duì)比
方法
實(shí)現(xiàn)上述目的一種方法是直接降低負(fù)樣本輸出的概率,但這樣往往會(huì)導(dǎo)致模型的災(zāi)難性遺忘,。
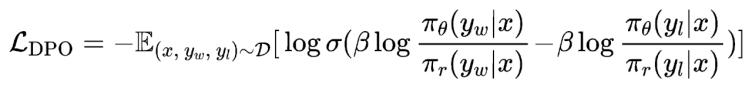
DPO成正負(fù)樣本對(duì)優(yōu)化的形式很好地避免了這個(gè)問題,,然而這種從實(shí)例級(jí)別優(yōu)化方式往往容易收到標(biāo)注數(shù)據(jù)中噪聲的影響。因此,,本文首先引入了可控文本生成中的分布控制(Generation with Distributional Control,,GDC)問題,它旨在從分布的角度控制模型的輸出,,如:要求模型輸出內(nèi)容中50%的內(nèi)容涉及女性,。基于此,,我們定義了分布級(jí)別的偏好建模,,并且推導(dǎo)出其建模出來的最優(yōu)獎(jiǎng)勵(lì)函數(shù)和DPO中的是完全等價(jià)的,進(jìn)而可以設(shè)計(jì)出以下的D2O損失函數(shù):
![]()
其中是待對(duì)齊的語言模型,,為參考模型,,相較于更加的有害。在具體操作過程中,,我們先用初始模型針對(duì)每個(gè)負(fù)樣本,,生成多個(gè)合成的正樣本。然后,,利用上述損失函數(shù)進(jìn)行優(yōu)化,,其中和以不同頻率進(jìn)行更新,每次更新以指數(shù)移動(dòng)平均的形式進(jìn)行,。此外,,我們?cè)谟?xùn)練過程中,引入在線采樣的合成正樣本,,進(jìn)一步提升對(duì)齊效果,。
實(shí)驗(yàn)
實(shí)驗(yàn)部分使用了PKU-SafeRLHF數(shù)據(jù)集進(jìn)行評(píng)估,采用Alpaca-7b,、Phi-3-4k-mini-instruct,、Qwen2-1.5B三個(gè)不同大小的開源模型進(jìn)行訓(xùn)練。對(duì)比方法方面,,選取了主流的6種基于有監(jiān)督微調(diào)的方法進(jìn)行對(duì)比,。在評(píng)估的指標(biāo)方面,,我們從多角度采用了多種評(píng)估的方法,首先,,我們從無害性,、有用性兩個(gè)維度選取了4個(gè)主流的獎(jiǎng)勵(lì)模型給模型輸出內(nèi)容進(jìn)行打分;使用了GPT-4評(píng)判模型生成內(nèi)容相較于原始生成內(nèi)容的勝率,;以及采用MMLU評(píng)估對(duì)齊稅的大小,。

表1 Alpaca-7B實(shí)驗(yàn)結(jié)果
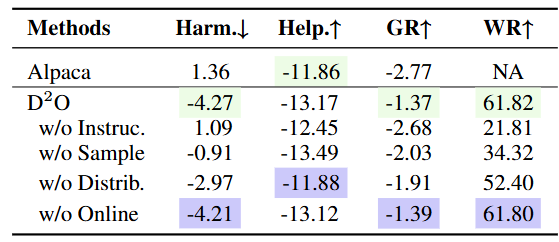
表2 消融實(shí)驗(yàn)結(jié)果
自動(dòng)化評(píng)估的實(shí)驗(yàn)結(jié)果表明,D2O在減少有害性,、保持有幫助性,、提高訓(xùn)練穩(wěn)定性和加快收斂速度方面均優(yōu)于其他基線方法。此外,,我們還進(jìn)行了人工評(píng)估,,以評(píng)估Alpaca、DPO和D2O生成的響應(yīng)的無害性和有幫助性,,結(jié)果進(jìn)一步驗(yàn)證了D2O的有效性,。在消融實(shí)驗(yàn)中,我們對(duì)于D2O的多個(gè)變體進(jìn)行了對(duì)比,,結(jié)果顯示使用self-correction,、分布級(jí)別優(yōu)化和在線采樣,有利于性能的提升,。
分析
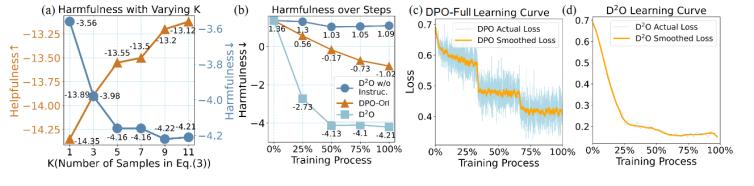
圖3 (a):在采用不同數(shù)量合成正樣本是有害性和有用性的變化,。(b): 隨著訓(xùn)練進(jìn)行模型有害性的變化。(c)和(d): 訓(xùn)練過程中損失函數(shù)的變化,。
我們進(jìn)一步探究了訓(xùn)練中采用的正樣本的數(shù)量的影響和以及訓(xùn)練過程中體現(xiàn)的性質(zhì),。在引入更多的合成正樣本時(shí),模型的有害性不斷下降,,同時(shí)模型的有用性不斷提升,,說明引入更多的正樣本能夠減輕對(duì)齊稅。同時(shí),,我們還可以觀察到,,在訓(xùn)練過程中,D2O的有害性下降將對(duì)于DPO更快,,同時(shí)損失函數(shù)的下降更加的平滑,,這體現(xiàn)了采用分布級(jí)別優(yōu)化的優(yōu)點(diǎn)。
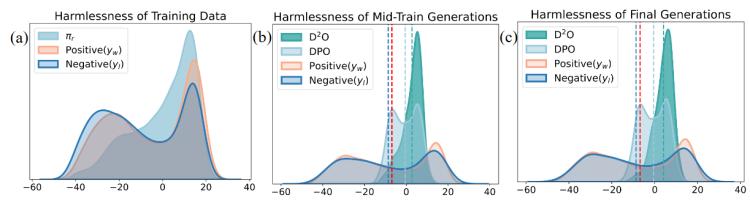
圖4 訓(xùn)練不同階段模型生成文本獎(jiǎng)勵(lì)分?jǐn)?shù)的分布變化
此外,,我們還進(jìn)一步分析了訓(xùn)練的不同階段,,模型生成內(nèi)容的獎(jiǎng)勵(lì)分布變化??梢杂^察到,,相比于D2O, DPO對(duì)應(yīng)的獎(jiǎng)勵(lì)分布具有明顯的雙峰特性,,說明其在優(yōu)化過程中受到了數(shù)據(jù)中噪聲的影響,而D2O具有明顯的單峰特性,,且平均獎(jiǎng)勵(lì)有著明顯的提升。
總結(jié)
本工作提出了使用人類標(biāo)注的負(fù)面樣本來實(shí)現(xiàn)對(duì)齊的任務(wù),,并據(jù)此導(dǎo)出了分布級(jí)偏好優(yōu)化的損失函數(shù)D2O,,有效地減少了有害性,同時(shí)保持了有用性,。實(shí)驗(yàn)結(jié)果表明,,D2O在減少有害性、保持有用性,、提高訓(xùn)練穩(wěn)定性和加快收斂速度方面均優(yōu)于其他基線方法,。未來的工作將探索將D2O方法擴(kuò)展到顯式獎(jiǎng)勵(lì)建模和RLHF,并進(jìn)一步減少大語言模型的對(duì)齊稅,。
作者信息
如果您對(duì)本文內(nèi)容感興趣的話,,可以與作者聯(lián)系:
段士童 復(fù)旦大學(xué)計(jì)算機(jī)學(xué)院協(xié)同信息與系統(tǒng)實(shí)驗(yàn)室 碩士研究生
研究方向:大語言模型價(jià)值觀對(duì)齊
聯(lián)系方式:[email protected]
載")

評(píng)論 0