








通過噪聲遮掩實(shí)現(xiàn)可擴(kuò)展的深度圖神經(jīng)網(wǎng)絡(luò)
Yuxuan Liang, Wentao Zhang, Zeang Sheng, Ling Yang, Quanqing Xu, Jiawei Jiang, Yunhai Tong, Bin Cui
論文鏈接:https://arxiv.org/abs/2412.14602
背景和挑戰(zhàn):
圖神經(jīng)網(wǎng)絡(luò) (GNN) 在圖表示學(xué)習(xí)方面取得了巨大成功,。但由于訓(xùn)練期間重復(fù)特征傳播的計(jì)算和存儲成本很高,,因此將其擴(kuò)展到大型圖具有挑戰(zhàn)性。
為了解決可擴(kuò)展性問題,,模型簡化GNN作為可擴(kuò)展性能的一個有前途的方向,,最近引起了人們的極大興趣。最具代表性的工作是SGC,,并以此衍生一系列模型簡化GNN比如SIGN,,S2GC, GBP, GAMLP等。
盡管現(xiàn)有的模型簡化 GNN 具有較好的可擴(kuò)展性和預(yù)測性能,,但它們?nèi)匀幻媾R以下兩個限制:(1)帶有噪聲信息的傳播,;(2)具有高預(yù)處理開銷的傳播。這兩個限制阻礙了模型簡化 GNN進(jìn)一步加深,。
研究動機(jī):
在本節(jié)中,,我們將深入分析模型簡化 GNN 中存在的兩個局限性,然后提供我們的見解來幫助我們設(shè)計(jì) RMask 的架構(gòu),。
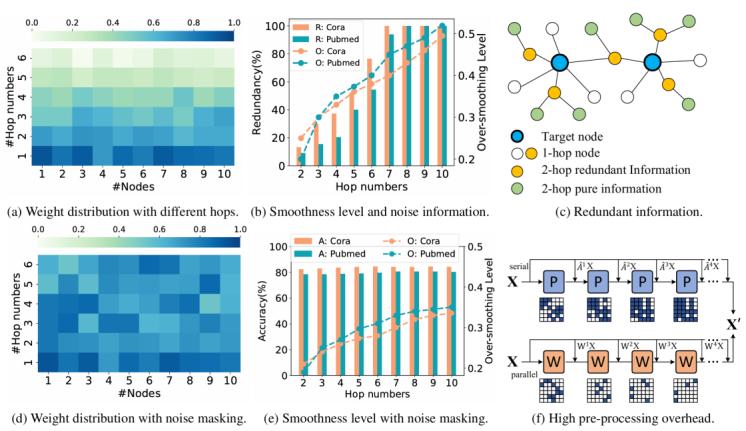
圖1. 實(shí)驗(yàn)觀察和見解
(1)帶有噪聲信息的傳播:
我們在Cora數(shù)據(jù)集上隨機(jī)選擇 10 個節(jié)點(diǎn),,并通過 L2 歸一化P傳播觀察每跳的平均權(quán)重。
如圖1a所示,,權(quán)重較高的節(jié)點(diǎn)經(jīng)常在較低的跳數(shù)內(nèi)被捕獲,,而有價值信息的較高跳數(shù)的節(jié)點(diǎn)表現(xiàn)出相當(dāng)?shù)偷臋?quán)重。這種現(xiàn)象阻礙了對高跳信息的捕獲,。
為了進(jìn)一步解釋,,我們從目標(biāo)節(jié)點(diǎn)開始進(jìn)行 2 跳傳播。如圖1c所示,,2跳捕獲的信息不僅包括當(dāng)前跳,,還包括2跳冗余信息,由于這些信息在1跳內(nèi)已經(jīng)可以捕獲,,我們將其稱為噪聲信息,。隨著傳播深度的增加,高跳捕獲的節(jié)點(diǎn)包含大量低跳噪聲信息,,難以區(qū)分高跳和低跳信息,,加劇了過平滑問題。為了進(jìn)一步研究噪聲信息對過平滑的影響,,我們增加跳數(shù),,并使用SIGN模型測量噪聲信息和圖平滑度GSL的比例。如圖1b所示,,隨著跳數(shù)的增加,,GSL呈爆炸式增長,,噪聲信息也不斷增長。7跳后捕獲的信息完全是冗余的,。
基于此,,我們重新實(shí)現(xiàn)了帶噪聲掩蔽的SIGN。如圖1d所示,,節(jié)點(diǎn)不僅可以捕獲高跳的有效信息,,還可以消除過度平滑問題,如圖1e所示,。隨著跳數(shù)的增加,,準(zhǔn)確率和平滑度趨于平穩(wěn)。
(2) 具有高預(yù)處理開銷的傳播:
此外,,這種傳播方法會導(dǎo)致顯著的預(yù)處理開銷,。圖1f 的上部說明了當(dāng)前模型簡化 GNN 采用的統(tǒng)一預(yù)處理過程。首先,,預(yù)處理的時間復(fù)雜度與邊的數(shù)量線性相關(guān),。每一跳都會從所有先前的跳數(shù)中捕獲大量的圖結(jié)構(gòu)信息,從而產(chǎn)生高密集計(jì)算開銷,。其次,,這種方法依賴于不同跳躍之間信息的相互依賴性,只能串行執(zhí)行,。與昂貴的預(yù)處理開銷相比,,模型簡化 GNN 通常使用簡單的模型進(jìn)行快速訓(xùn)練。由于上述原因,,預(yù)處理開銷構(gòu)成了端到端訓(xùn)練時間的大部分,。如圖1f下半部分所示,為了減少預(yù)處理的高開銷,,我們需要一種稀疏和并行的方法來有效地捕獲每一跳的重要信息,。
方法:
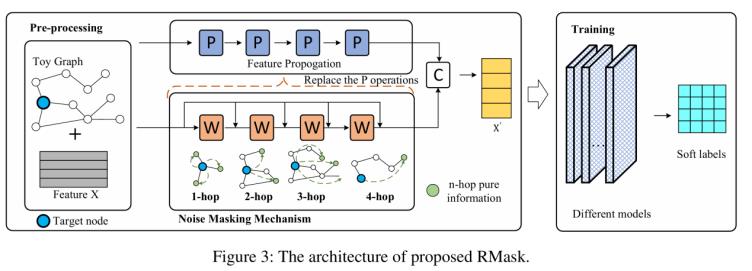
圖2. Rmask架構(gòu)
RMask執(zhí)行流程:
給定指定的跳躍數(shù)和圖結(jié)構(gòu),我們首先根據(jù)圖結(jié)構(gòu)對每個節(jié)點(diǎn)執(zhí)行帶有屏蔽機(jī)制的隨機(jī)游走,。然后聚合捕獲的圖結(jié)構(gòu)信息和特征以獲得不同跳躍的結(jié)果。
此外,,通過這種方式得到的特征傳播結(jié)果可以直接替代其他模型簡化GNN(如 S2GC,、GBP、SIGN,、GAMLP 等)中的P操作,。同時,我們保留了現(xiàn)有模型簡化 GNN 在特征組合和模型選擇方面的優(yōu)勢,。
噪聲掩碼機(jī)制:
噪聲掩碼機(jī)制由兩個部分組成:噪聲信息識別和鄰居節(jié)點(diǎn)重要性分配,。
第一個組件識別每一跳中的噪聲信息,,并使用隨機(jī)游走有效地捕獲非冗余的圖結(jié)構(gòu)信息。第二個組件為每個鄰居節(jié)點(diǎn)分配重要性權(quán)重,,以幫助隨機(jī)游走捕獲更重要的信息,。
(1)噪聲信息識別:
考慮到噪聲的影響,高跳數(shù)通常包含來自低跳數(shù)的冗余信息,。因此,,我們需要遍歷整個圖來識別每一跳的噪聲信息?;趯Ω遠(yuǎn)op噪聲信息的觀察,,我們使用去噪矩陣來記錄噪聲信息:
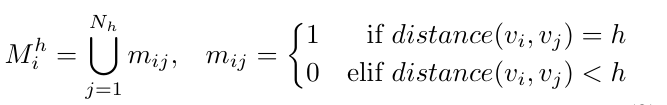
采用去噪矩陣使我們能夠在確保低過平滑度級別的同時,從每一跳中提取有用信息,。然后,,對于每一跳,我們使用隨機(jī)游走函數(shù)(RW)來捕獲當(dāng)前跳的圖結(jié)構(gòu)信息,,然后結(jié)合去噪矩陣從每一跳中提取有用的信息:
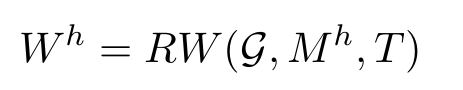
其中T是隨機(jī)游走的次數(shù),。通過控制T,我們在準(zhǔn)確性和效率之間取得了良好的平衡,,使其可以支持大規(guī)模圖的處理,。
(2)鄰居節(jié)點(diǎn)重要性分配:
為了進(jìn)一步提升預(yù)測精度,我們采用基于相鄰節(jié)點(diǎn)重要性的偏置隨機(jī)游走,。使用PageRank來獲取相鄰節(jié)點(diǎn)重要性:
![]()
其中S是重要性矩陣,。通過為圖中的每個邊分配重要性權(quán)重,可以引導(dǎo)隨機(jī)游動的方向,,從而捕獲更重要的去噪信息,。具體算法如表1所示:

表1. Rmask算法概述
實(shí)驗(yàn)效果:
實(shí)驗(yàn)主要包含以下四個方面:(1)與最先進(jìn)的模型簡化方法進(jìn)行端到端比較 ;(2)分析更深層架構(gòu)的能力 ,;(3)分析效率和準(zhǔn)確性之間的權(quán)衡 ,;(4)分析效率。
(1)與最先進(jìn)的模型簡化方法進(jìn)行端到端比較:如表2所示,,集成RMask 后,,SIGN、S2GC,、GBP 和 GAMLP 在所有六個數(shù)據(jù)集上均實(shí)現(xiàn)了比其各自原始版本更好的性能,。
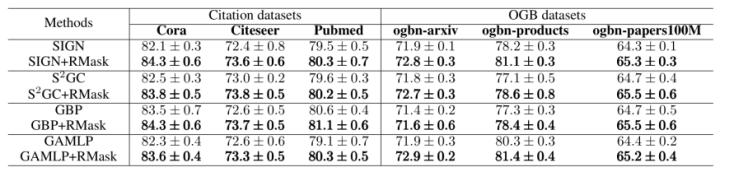
表2. 節(jié)點(diǎn)分類預(yù)測任務(wù)的實(shí)驗(yàn)結(jié)果
(2)更深層架構(gòu)的能力:如圖3所示,集成Rmask的模型簡化方法可以更有效地利用深層信息,,從而提高準(zhǔn)確性,。
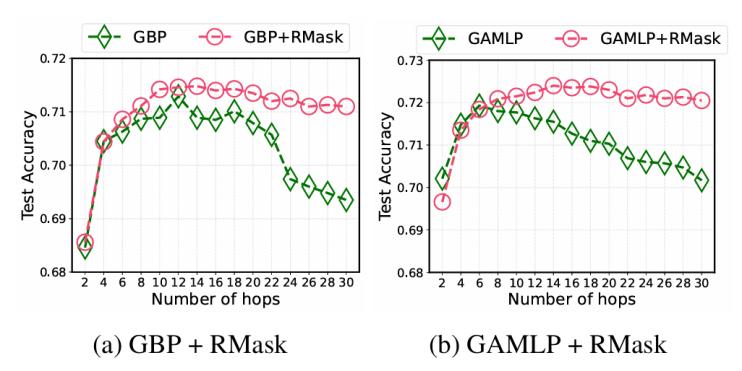
圖3. 隨著跳數(shù)增加,性能變化的趨勢
(3)分析效率和準(zhǔn)確性之間的權(quán)衡:如圖4(a)所示,,使用 RMaska 插件模塊可以在效率和準(zhǔn)確性之間進(jìn)行良好的權(quán)衡,。
(4)效率實(shí)驗(yàn):如圖4(b)(c)所示,,在所有數(shù)據(jù)集中,我們的方法成功地減少了端到端訓(xùn)練中預(yù)處理開銷的比例,,并且獲得了2.9X以上的提速,。
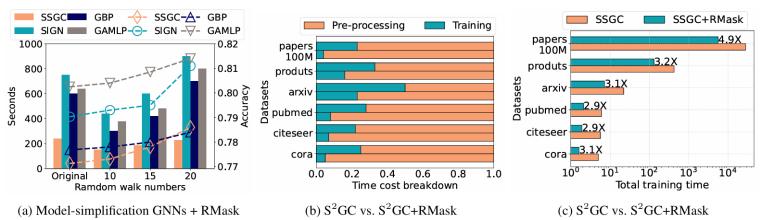
圖4. (a)ogbn-product上效率和準(zhǔn)確性之間的權(quán)衡。(b)時間開銷分析,。(c)加速分析,。
總結(jié):
本文介紹了 RMask,這是一個即插即用的模塊,,旨在增強(qiáng)現(xiàn)有的模型簡化 GNN 在更高速度下探索更深層次的圖形結(jié)構(gòu)的能力,。作為插件方法, RMask可以與大多數(shù)模型簡化GNN無縫集成,。實(shí)驗(yàn)結(jié)果表明,,RMask有效地提高了模型簡化GNN的準(zhǔn)確性和效率。
實(shí)驗(yàn)室簡介
北京大學(xué)數(shù)據(jù)與智能實(shí)驗(yàn)室(Data And Intelligence Research Lab at Peking Univeristy,,PKU-DAIR實(shí)驗(yàn)室)由北京大學(xué)計(jì)算機(jī)學(xué)院崔斌教授領(lǐng)導(dǎo),,長期從事數(shù)據(jù)庫系統(tǒng)、大數(shù)據(jù)管理與分析,、人工智能等領(lǐng)域的前沿研究,,在理論和技術(shù)創(chuàng)新以及系統(tǒng)研發(fā)上取得多項(xiàng)成果,已在國際頂級學(xué)術(shù)會議和期刊發(fā)表學(xué)術(shù)論文100余篇,,發(fā)布多個開源項(xiàng)目,。課題組同學(xué)曾數(shù)十次獲得包括CCF優(yōu)博、ACM中國優(yōu)博,、北大優(yōu)博,、微軟學(xué)者、蘋果獎學(xué)金,、谷歌獎學(xué)金等榮譽(yù),。PKU-DAIR實(shí)驗(yàn)室持續(xù)與工業(yè)界展開卓有成效的合作,與騰訊,、阿里巴巴,、蘋果、微軟,、百度,、快手、中興通訊等多家知名企業(yè)開展項(xiàng)目合作和前沿探索,,解決實(shí)際問題,進(jìn)行科研成果的轉(zhuǎn)化落地,。
載")

評論 3