








轉(zhuǎn)載自微信公眾號(hào):AI前線
近日,清華 KEG 實(shí)驗(yàn)室與智譜 AI 聯(lián)合推出了視覺(jué) GUI Agent——CogAgent,,CogAgent 是一個(gè)通用的視覺(jué)理解大模型,,具備視覺(jué)問(wèn)答、視覺(jué)定位(Grounding),、GUI Agent 等多種能力,,可接受 1120×1120 的高分辨率圖像輸入。在 9 個(gè)經(jīng)典的圖像理解榜單上(含 VQAv2,,STVQA, DocVQA,,TextVQA,MM-VET,,POPE 等)取得了通用能力第一的成績(jī),,并在涵蓋電腦、手機(jī)的 GUI Agent 數(shù)據(jù)集上(含 Mind2Web,,AITW 等),,大幅超過(guò)基于 LLM 的 Agent,取得第一,。
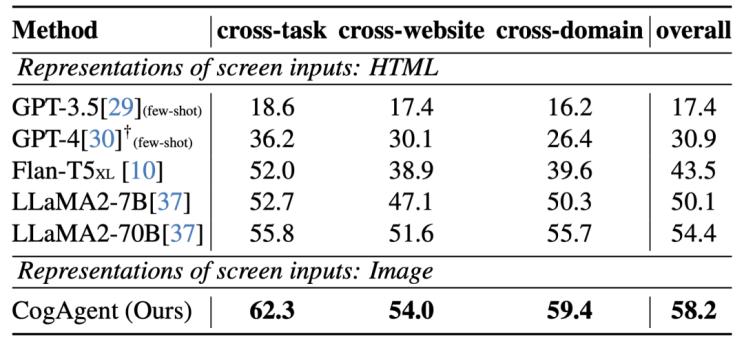 圖1 在網(wǎng)頁(yè) Agent 數(shù)據(jù)集 Mind2Web 上的性能
圖1 在網(wǎng)頁(yè) Agent 數(shù)據(jù)集 Mind2Web 上的性能
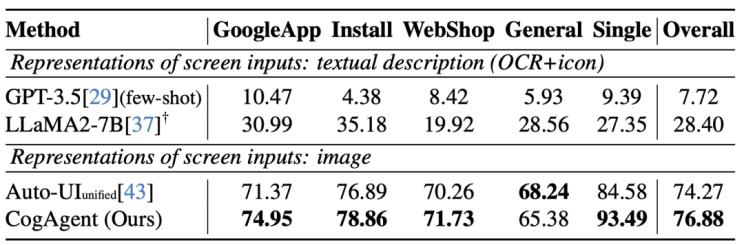
圖2 在手機(jī) Agent 數(shù)據(jù)集 AITW 上的性能
為了更好地促進(jìn)多模態(tài)大模型,、Agent 社區(qū)的發(fā)展,目前團(tuán)隊(duì)已將 CogAgent-18B 開(kāi)源至 GitHub 倉(cāng)庫(kù),,并提供了網(wǎng)頁(yè)版 Demo,。
-
GitHub 項(xiàng)目地址(含開(kāi)源模型、網(wǎng)頁(yè)版 Demo):https://github.com/THUDM/CogVLM
視覺(jué) GUI Agent
基于語(yǔ)言預(yù)訓(xùn)練模型(LLM)的 Agent 是當(dāng)下熱門(mén)的研究話題,其具備良好的應(yīng)用前景,。但受限于 LLM 的模態(tài),,它只能接受語(yǔ)言形式的輸入。拿網(wǎng)頁(yè) Aagent 為例,,WebAgent 等工作將網(wǎng)頁(yè) HTML 連同用戶目標(biāo)(例如“Can you search for CogAgent on google”)作為 LLM 的輸入,,從而獲得 LLM 對(duì)下一步動(dòng)作的預(yù)測(cè)(例如點(diǎn)擊按鈕,輸入文本),。
然而,,一個(gè)有趣的觀察是,人類(lèi)是通過(guò)視覺(jué)與 GUI 交互的,。比如,,面對(duì)一個(gè)網(wǎng)頁(yè),當(dāng)給定一個(gè)操作目標(biāo)時(shí),,人類(lèi)會(huì)先觀察他的 GUI 界面,,然后決定下一步做什么;與此同時(shí),,GUI 天然是為了人機(jī)交互設(shè)計(jì)的,,相比于 HTML 等文本模態(tài)的表征,GUI 更為直接簡(jiǎn)潔,,易于獲取有效信息,。也就是說(shuō),在 GUI 場(chǎng)景下,,視覺(jué)是一種更為直接,、本質(zhì)的交互模態(tài),能更高效完整提供環(huán)境信息,;更進(jìn)一步地,,很多 GUI 界面并沒(méi)有對(duì)應(yīng)的源碼,也難以用語(yǔ)言表示,。因此,若能將大模型改進(jìn)為視覺(jué) Agent,,將 GUI 界面以視覺(jué)的形式直接輸入大模型中用于理解,、規(guī)劃和決策,將是一個(gè)更為直接有效,、具備極大提升空間的方法,。
CogAgent 可以實(shí)現(xiàn)基于視覺(jué)的 GUI Agent,其工作路徑與能力如下:
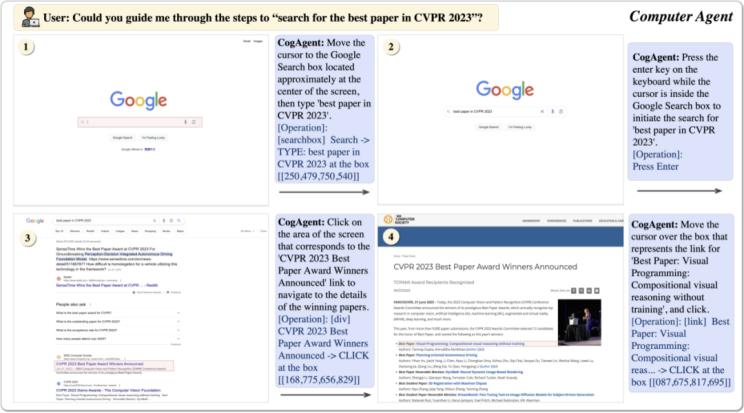
圖4 CogAgent工作路徑與能力
CogAgent 模型同時(shí)接受當(dāng)前 GUI 截圖(圖像形式)和用戶操作目標(biāo)(文本形式,,例如“search for the best paper in CVPR 2023”)作為輸入,,就能預(yù)測(cè)詳細(xì)的動(dòng)作,和對(duì)應(yīng)操作元素的位置坐標(biāo)??梢詰?yīng)用于包括電腦,、手機(jī)的各種場(chǎng)景。受益于 GUI Agent 的可泛化性,,CogAgent 能在各類(lèi)沒(méi)見(jiàn)過(guò)的場(chǎng)景與任務(wù)上都取得良好的性能,。論文中展示了更多示例,覆蓋了 PPT,、手機(jī)系統(tǒng),、社交軟件、游戲等各類(lèi)場(chǎng)景
CogAgent 的模型結(jié)構(gòu)及訓(xùn)練方法
據(jù)介紹,,CogAgent 的模型結(jié)構(gòu)基于 CogVLM,。為了使模型具備對(duì)高分辨率圖片的理解能力,可以看清 720p 的 GUI 屏幕輸入,,團(tuán)隊(duì)將圖像輸入的分辨率大幅提升至 1120×1120(以往的模型通常小于 500×500,,包括 CogVLM,Qwen-VL 等),。然而,,分辨率的提升會(huì)導(dǎo)致圖像序列急劇增長(zhǎng),帶來(lái)難以承受的計(jì)算和顯存開(kāi)銷(xiāo)——這也是現(xiàn)有多模態(tài)預(yù)訓(xùn)練模型通常采用較小分辨率圖像輸入的原因之一,。
對(duì)此,,團(tuán)隊(duì)設(shè)計(jì)了輕量級(jí)的“高分辨率交叉注意力模塊”,在原有低分辨率大圖像編碼器(4.4 B)的基礎(chǔ)上,,增加了高分辨率的小圖像編碼器 (0.3 B),,并使用交叉注意力機(jī)制與原有的 VLM 交互。在交叉注意力中,,團(tuán)隊(duì)也使用了較小的 hidden size,,從而進(jìn)一步降低顯存與計(jì)算開(kāi)銷(xiāo)。
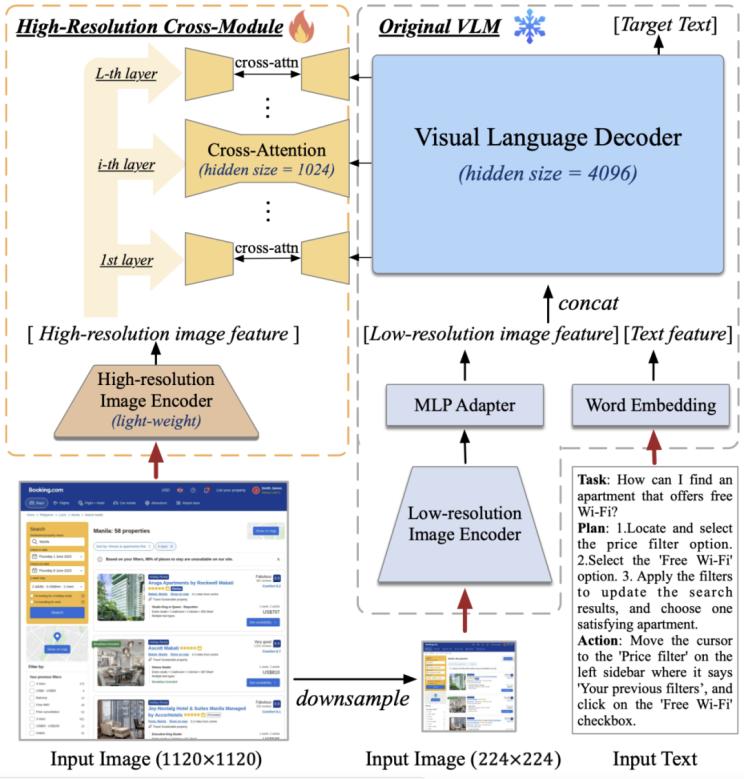
圖5 高分辨率交叉注意力模塊設(shè)計(jì)
結(jié)果表明,,該方法可以使模型成功理解高分辨率的圖片,,并有效降低了顯存與計(jì)算開(kāi)銷(xiāo)。在消融實(shí)驗(yàn)中,,團(tuán)隊(duì)還比較了該結(jié)構(gòu)與 CogVLM 原始方法的計(jì)算量,。結(jié)果表明,當(dāng)分辨率提升時(shí),,使用文中提出的方案(with cross-module,,橙色)將會(huì)帶來(lái)極少量的計(jì)算量增加,并與圖像序列的增長(zhǎng)成線性關(guān)系,。特別的,,1120×1120 分辨率的 CogAgent 的計(jì)算開(kāi)銷(xiāo)(FLOPs),,甚至比 490×490 分辨率的 CogVLM 的 1/2 還要小。在 INT4 單卡推理測(cè)試中,,1120×1120 分辨率的 CogAgent 模型占用約 12.6GB 的顯存,,相較于 224×224 分辨率的 CogVLM 僅高出不到 2GB。
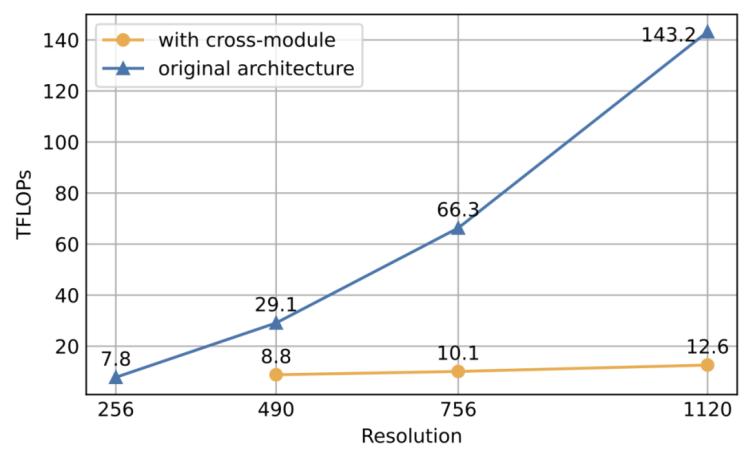
圖5 CogAgent 模型理解高分辨率圖片結(jié)果圖
在數(shù)據(jù)方面,,除了 CogVLM 用到的 image caption 數(shù)據(jù)集之外,,團(tuán)隊(duì)在文本識(shí)別、視覺(jué)定位,、GUI 圖像理解方面進(jìn)行了數(shù)據(jù)擴(kuò)充與增強(qiáng),,從而有效提升了 GUI Agent 場(chǎng)景下的性能。(CogAgent 的預(yù)訓(xùn)練和微調(diào)數(shù)據(jù)的采集,、生成方法詳細(xì)介紹于論文的 2.2 和 2.3 部分,。)
來(lái)源:AI前線(編輯:凌敏 )
載")

評(píng)論 0