 553
553
 0
0
 2025-02-21
2025-02-21
 2025-02-21
2025-02-21

該論文發(fā)表于《IEEE TRANSACTIONS ON FUZZY SYSTEMS》(中科院一區(qū),IF=10.7),,題目為《A Comprehensive Adaptive Interpretable Takagi–Sugeno–Kang Fuzzy Classifier for Fatigue Driving Detection》,。
成都信息工程大學(xué)計(jì)算機(jī)學(xué)院科研團(tuán)隊(duì)的郜東瑞為此論文的第一作者,。成都信息工程大學(xué)計(jì)算機(jī)學(xué)院科研團(tuán)隊(duì)的張永清教授為此論文的通訊作者,。
論文鏈接:
https://ieeexplore.ieee.org/document/10528899
腦電圖(EEG)信號(hào)作為一種可靠的生物指標(biāo),由于能夠反映駕駛員的認(rèn)知和神經(jīng)反應(yīng)狀態(tài),,已被廣泛用于疲勞駕駛檢測(cè),。然而,EEG信號(hào)存在數(shù)據(jù)分布不平衡,、個(gè)體間差異顯著以及場(chǎng)景復(fù)雜等問(wèn)題,,這些都會(huì)影響檢測(cè)效果。輸入對(duì)象之間的微小共性可以被解釋為整個(gè)樣本的重要信息,。因此,,為了盡可能保留信息,本研究設(shè)計(jì)了一種新的模糊特征整合方法,,即綜合自適應(yīng)可解釋Takagi-Sugeno-Kang模糊分類器(CAI-TSK-FC),,用于整合模糊特征。該方法不僅能夠更高效地捕獲多個(gè)子分類器的特征,,緩解數(shù)據(jù)集不平衡問(wèn)題,,還可以通過(guò)隨機(jī)保留模糊規(guī)則和歸一化減少錯(cuò)誤信息的積累。最終,本研究將多個(gè)子分類器的結(jié)果線性組合,,綜合考慮多個(gè)子分類器的學(xué)習(xí)效果,,以適應(yīng)不同個(gè)體和數(shù)據(jù)集。在自制數(shù)據(jù)集和公共數(shù)據(jù)集上的實(shí)驗(yàn)表明,,CAI-TSK-FC在不同的EEG疲勞駕駛數(shù)據(jù)集上具有良好的性能和可解釋性,。與現(xiàn)有方法相比,其準(zhǔn)確率分別提高了3.15%和1.52%,,特異性分別提高了4.72%和0.91%,。
研究背景
駕駛疲勞是交通事故中最重要的影響因素之一,不僅危及駕駛員的生命,,也危及其他道路使用者的安全,。而開(kāi)發(fā)一種有效的算法來(lái)檢測(cè)駕駛員的疲勞狀態(tài)已成為減少交通事故發(fā)生的一種手段。早期的疲勞檢測(cè)算法可分為主觀檢測(cè)方法和客觀檢測(cè)方法,。主觀檢測(cè)方法受到個(gè)體意愿和判斷的極大影響,,缺乏足夠的說(shuō)服力;客觀檢測(cè)方法包括生理信號(hào),、面部特征和車輛軌跡,。面部特征和車輛軌跡計(jì)算分別受到光照和駕駛員技術(shù)的影響。使用生理信號(hào)進(jìn)行分析可以避免上述問(wèn)題,。在生理信號(hào)中,,腦電圖(EEG)信號(hào)能夠捕捉有關(guān)神經(jīng)生理腦活動(dòng)的信息,并準(zhǔn)確反映駕駛員的心理狀態(tài)?,F(xiàn)有的研究使用深度學(xué)習(xí)方法來(lái)表征疲勞狀態(tài)下的EEG信號(hào),,盡管這些研究取得了令人滿意的結(jié)果,但它們并不能完全解釋所學(xué)習(xí)到的特征,。近年來(lái),,Takagi-Sugeno-Kang(TSK)模糊系統(tǒng)在EEG領(lǐng)域展現(xiàn)了獨(dú)特的能力,但仍存在一些限制,,具體如下:
1)EEG信號(hào)容易受到復(fù)雜環(huán)境的影響,,不同場(chǎng)景下EEG信號(hào)的特征存在差異,這限制了模型的泛化能力,。
2)疲勞駕駛過(guò)程中產(chǎn)生的EEG數(shù)據(jù)存在采樣不平衡,,正負(fù)EEG采樣差異對(duì)模型預(yù)測(cè)精度的影響尚未明確。
3)傳統(tǒng)的堆疊TSK模糊分類器會(huì)持續(xù)積累錯(cuò)誤信息,,從而影響后續(xù)層的特征提取效果,。
為了解決這些問(wèn)題,本研究提出了一種新的用于檢測(cè)疲勞的方法,,即綜合自適應(yīng)可解釋TSK模糊分類器(CAI-TSK-FC)。CAI-TSK-FC利用一種新的模糊特征整合方法從數(shù)據(jù)集中提取更多信息,以解決不平衡帶來(lái)的學(xué)習(xí)資源不足問(wèn)題,。此外,,為了減少錯(cuò)誤信息的積累,本研究開(kāi)發(fā)了模糊規(guī)則隨機(jī)保留和線性組合方法,,以增強(qiáng)模型的自適應(yīng)性能,,同時(shí)將錯(cuò)誤信息對(duì)結(jié)果的影響降至最低。本研究的模型通過(guò)整合低階TSK模糊系統(tǒng)實(shí)現(xiàn)了與深度學(xué)習(xí)技術(shù)相當(dāng)?shù)男阅?。此外,,本研究利用TSK模糊系統(tǒng)的語(yǔ)言規(guī)則可解釋性來(lái)提高可解釋性,減少深度學(xué)習(xí)“黑箱問(wèn)題”的影響,。
方法
作為一種非平穩(wěn)信號(hào),,EEG對(duì)生理和環(huán)境因素非常敏感,獲取的信息存在許多不確定性,?;谀:侠碚摰哪:诸惼髂軌蚓徑獠淮_定性問(wèn)題,因此本研究將其用于信號(hào)分類,。圖1和圖2共同展示了本文的整體算法框架,。圖1展示了EEG預(yù)處理過(guò)程,圖2展示了CAI-TSK-FC模型的總體結(jié)構(gòu),。
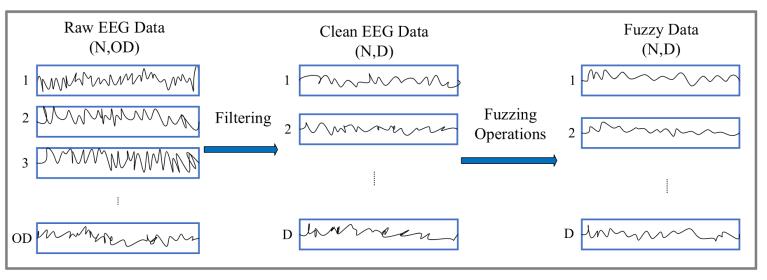
圖1 EEG處理,。預(yù)處理是一個(gè)包含濾波和模糊化兩個(gè)步驟的過(guò)程,目標(biāo)是盡可能去除偽跡并將數(shù)據(jù)轉(zhuǎn)換為模糊屬性,。其中,,N表示輸入樣本的數(shù)量,OD表示原始特征的維度,,D表示處理后的特征維度,,且D≤OD。
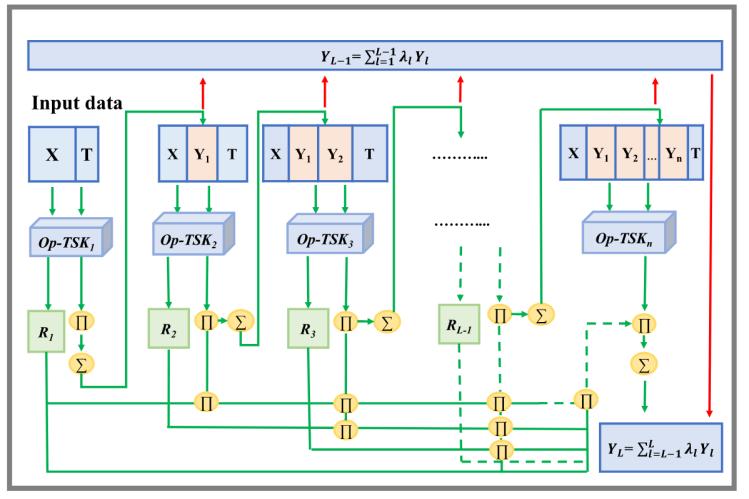
圖2 CAI-TSK-FC結(jié)構(gòu),。 輸入數(shù)據(jù)X和目標(biāo)T進(jìn)入第一個(gè)子分類器OP-TSK1,。保留部分模糊規(guī)則R1及其學(xué)習(xí)結(jié)果Y1,并計(jì)算此時(shí)的分類性能,。如果達(dá)到了預(yù)期結(jié)果,,則訓(xùn)練停止。否則,,將R1,、Y1和原始數(shù)據(jù)X輸入到下一個(gè)子分類器,進(jìn)行多個(gè)子分類器結(jié)果的線性組合,。這一過(guò)程會(huì)不斷循環(huán),,直到模型產(chǎn)生預(yù)期的結(jié)果,。
在預(yù)處理階段,本研究首先對(duì)原始數(shù)據(jù)進(jìn)行濾波以去除偽跡,,然后使用主成分分析(PCA)對(duì)數(shù)據(jù)進(jìn)行降維處理,,最后使用模糊C均值方法(FCM)對(duì)獲得的數(shù)據(jù)進(jìn)行模糊化操作,以得到模糊屬性數(shù)據(jù),。
A. TSK模糊分類器
經(jīng)典的TSK模糊分類器由一組規(guī)則組成,,其中第r條模糊規(guī)則如下:
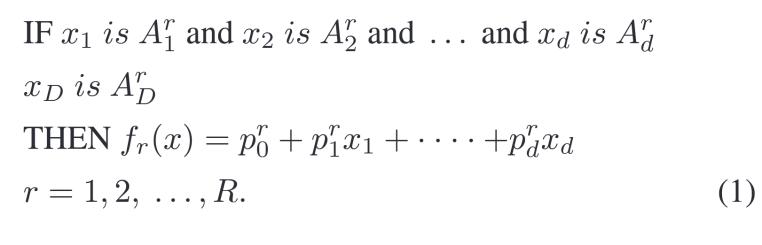
在TSK模糊分類器中,輸入向量![]() ,,
,,![]() 是從輸入向量X映射到輸出空間的模糊集合,。輸入空間的模糊子集Ar通過(guò)TSK模糊分類器轉(zhuǎn)換為輸出空間的模糊集合fr(x)。R是模糊規(guī)則的數(shù)量,,D是樣本的維度數(shù),。
是從輸入向量X映射到輸出空間的模糊集合,。輸入空間的模糊子集Ar通過(guò)TSK模糊分類器轉(zhuǎn)換為輸出空間的模糊集合fr(x)。R是模糊規(guī)則的數(shù)量,,D是樣本的維度數(shù),。![]() 是輸入向量x的第i維對(duì)應(yīng)的第r條規(guī)則的模糊子集。
是輸入向量x的第i維對(duì)應(yīng)的第r條規(guī)則的模糊子集。
如果fr(x)是![]() ,,則TSK模糊分類器為零階,。本研究選擇零階TSK模糊分類器作為構(gòu)建CAI-TSK-FC的基本結(jié)構(gòu)。研究證明,,零階TSK模糊分類器的集成等同于高階TSK模糊分類器,,并且具有更好的可解釋性。本研究采用高斯函數(shù)作為模糊隸屬函數(shù),,使模糊隸屬度計(jì)算更加平滑,,并能更好地適應(yīng)不同數(shù)據(jù)。TSK模糊分類的輸出可以表示為:
,,則TSK模糊分類器為零階,。本研究選擇零階TSK模糊分類器作為構(gòu)建CAI-TSK-FC的基本結(jié)構(gòu)。研究證明,,零階TSK模糊分類器的集成等同于高階TSK模糊分類器,,并且具有更好的可解釋性。本研究采用高斯函數(shù)作為模糊隸屬函數(shù),,使模糊隸屬度計(jì)算更加平滑,,并能更好地適應(yīng)不同數(shù)據(jù)。TSK模糊分類的輸出可以表示為:

其中,,![]() 是通過(guò)高斯隸屬函數(shù)計(jì)算的模糊規(guī)則的結(jié)果,,
是通過(guò)高斯隸屬函數(shù)計(jì)算的模糊規(guī)則的結(jié)果,,![]() 是通過(guò)模糊規(guī)則標(biāo)準(zhǔn)化后的模糊隸屬函數(shù),μr(x)是通過(guò)模糊規(guī)則的前件部分經(jīng)過(guò)模糊化運(yùn)算得到的,,即:
是通過(guò)模糊規(guī)則標(biāo)準(zhǔn)化后的模糊隸屬函數(shù),μr(x)是通過(guò)模糊規(guī)則的前件部分經(jīng)過(guò)模糊化運(yùn)算得到的,,即:
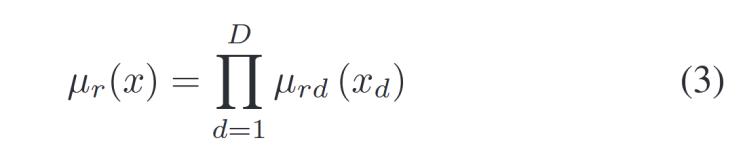
其中,,![]() 可以通過(guò)高斯函數(shù)計(jì)算模糊隸屬函數(shù)表示為:
可以通過(guò)高斯函數(shù)計(jì)算模糊隸屬函數(shù)表示為:
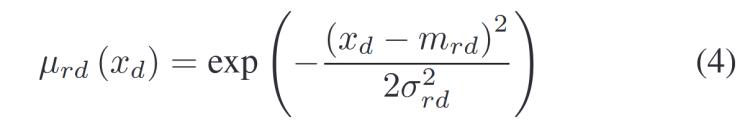
其中,mrd和σrd分別是高斯隸屬函數(shù)的中心和標(biāo)準(zhǔn)差,。
本研究使用五個(gè)高斯隸屬函數(shù)來(lái)表示每條模糊規(guī)則,。這些隸屬函數(shù)的中心(MF1, MF2, MF3, MF4, MF5)分別為0、0.25,、0.5,、0.75和1。因此,,可以從語(yǔ)言學(xué)上解釋模糊規(guī)則,,即(非常低、低,、中等,、高,、非常高)?;谶@些結(jié)果,,可以提高零階TSK模糊分類器的可解釋性。
B. 優(yōu)化TSK模糊分類器
傳統(tǒng)的TSK模糊分類器對(duì)某些不平衡樣本的識(shí)別率較低,。為了解決這一問(wèn)題,本研究提出了一個(gè)優(yōu)化的零階TSK模糊分類器作為CAI-TSK-FC的子分類器,。主要框架如圖3所示,。
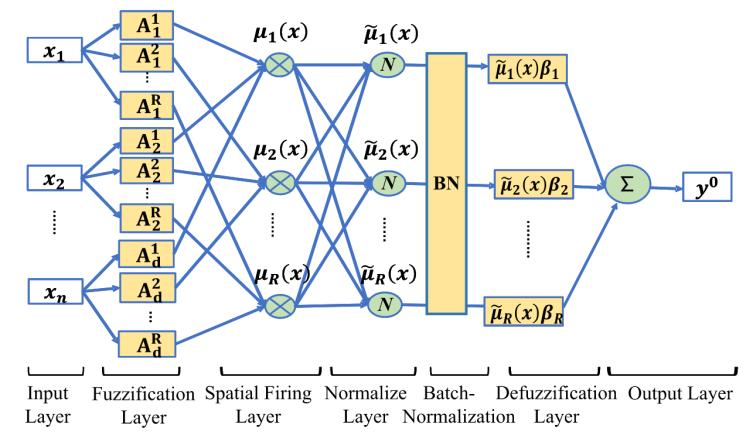
圖3 利用BN和指數(shù)函數(shù)優(yōu)化TSK模糊分類器的計(jì)算過(guò)程。
預(yù)處理后的數(shù)據(jù)將輸入到本研究提出的TSK子模糊分類器中,,接下來(lái)的部分中,,用 表示第l層子分類器的輸出,l = 1, 2, ..., 7,。
表示第l層子分類器的輸出,l = 1, 2, ..., 7,。
1)輸入層:預(yù)處理后的EEG特征數(shù)據(jù)可以表示為X = (x?, x?, ..., xn),,該層的數(shù)據(jù)是輸入數(shù)據(jù),不參與計(jì)算:

其中i = 1, 2, ..., n表示第i個(gè)樣本,。
2)隸屬函數(shù)層:為了提高模型對(duì)數(shù)據(jù)的適應(yīng)能力,,該層將輸入數(shù)據(jù)映射到高斯隸屬函數(shù)。此外,,邏輯關(guān)系建模在模糊規(guī)則構(gòu)建中也起著重要作用,,這一層也實(shí)現(xiàn)了這一功能。對(duì)于EEG信號(hào)而言,,不同數(shù)據(jù)所表示的信息存在差異和相似性,。通過(guò)計(jì)算隸屬函數(shù),可以識(shí)別不同數(shù)據(jù)之間的相似性和差異性,,從而提高模型的分類能力,。在這一層,使用高斯隸屬函數(shù)計(jì)算輸入數(shù)據(jù)的隸屬度值如下:

其中r是第r條模糊規(guī)則,,d是第d個(gè)特征,。
在TSK模糊分類器的模糊規(guī)則生成中,并非所有子分類器的規(guī)則都需要進(jìn)行后續(xù)計(jì)算,。因此,,本研究在CAI-TSK-FC的每個(gè)Op-TSK? (l = 1, 2, ..., L)中添加了一個(gè)特征選擇矩陣![]() 。該矩陣的作用是控制每條模糊規(guī)則的后件計(jì)算,。其格式如下:“如果x?是低的且
。該矩陣的作用是控制每條模糊規(guī)則的后件計(jì)算,。其格式如下:“如果x?是低的且 ![]() ∧ x?是高的且
∧ x?是高的且![]() ∧ x?是中等的且
∧ x?是中等的且![]() ∧ x?是非常低的且
∧ x?是非常低的且![]() ∧ x?是低的且
∧ x?是低的且![]() ,,則
,,則![]() 屬于類別c。r = 1, 2, ..., R,。”當(dāng)
屬于類別c。r = 1, 2, ..., R,。”當(dāng)![]() 時(shí),,忽略第r條模糊規(guī)則的貢獻(xiàn),;只有當(dāng)
時(shí),,忽略第r條模糊規(guī)則的貢獻(xiàn),;只有當(dāng)![]() 時(shí)才應(yīng)用該規(guī)則。此外,,本研究還添加了一個(gè)模糊規(guī)則矩陣
時(shí)才應(yīng)用該規(guī)則。此外,,本研究還添加了一個(gè)模糊規(guī)則矩陣![]() ,。在這個(gè)矩陣中,每個(gè)元素的值隨機(jī)分配為0或1,,以決定每條模糊規(guī)則使用哪個(gè)高斯隸屬函數(shù),。例如,F(xiàn)RM[4, 2, 3] = 1表示第三條模糊規(guī)則中的第四個(gè)輸入特征使用“低”隸屬函數(shù),。
,。在這個(gè)矩陣中,每個(gè)元素的值隨機(jī)分配為0或1,,以決定每條模糊規(guī)則使用哪個(gè)高斯隸屬函數(shù),。例如,F(xiàn)RM[4, 2, 3] = 1表示第三條模糊規(guī)則中的第四個(gè)輸入特征使用“低”隸屬函數(shù),。
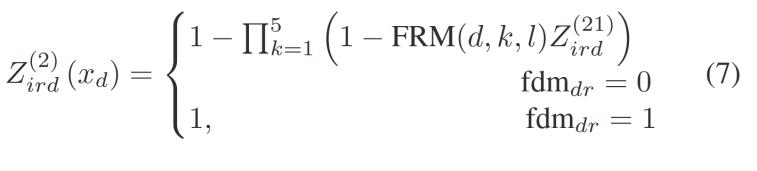
其中k是第k個(gè)高斯隸屬函數(shù)的中心值[0, 0.25, 0.5, 0.75, 1],。l表示第l層子分類器。
3)空間激發(fā)層:這一層的主要功能是計(jì)算空間激發(fā)強(qiáng)度,?;谇耙粚拥暮瘮?shù)計(jì)算,可以獲得輸入數(shù)據(jù)每個(gè)特征的隸屬度值,。傳統(tǒng)的空間激發(fā)強(qiáng)度是通過(guò)連續(xù)累積乘法方法計(jì)算的,。這種方法受到維度詛咒的影響,無(wú)法適應(yīng)高維數(shù)據(jù),,公式如下:
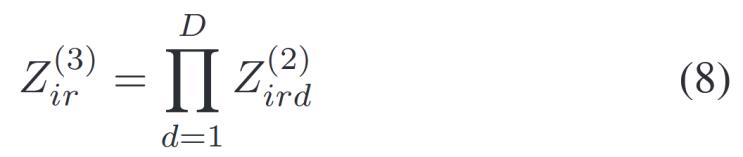
其中,,當(dāng)![]() 的差異較小時(shí),
的差異較小時(shí),![]() 會(huì)收斂到0,,此時(shí)
會(huì)收斂到0,,此時(shí)![]() ,。同樣,當(dāng)
,。同樣,當(dāng)![]() 時(shí),,即數(shù)據(jù)是高維的情況下,,
時(shí),,即數(shù)據(jù)是高維的情況下,,![]() 的值會(huì)非常大,導(dǎo)致溢出,。
的值會(huì)非常大,導(dǎo)致溢出,。
在EEG信號(hào)分類任務(wù)中,,更多的數(shù)據(jù)可能會(huì)帶來(lái)更好的分類性能。為了解決這一問(wèn)題,,本研究修改了這一層的函數(shù),。公式如下:
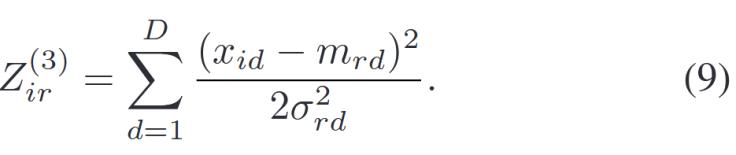
為了使計(jì)算結(jié)果更加平滑,本研究將連續(xù)累積乘法方法改為求和公式,。這種方法仍然能夠很好地辨別各種數(shù)據(jù)差異,,同時(shí)保持原有功能。
4)歸一化層:在這一層中,,本研究對(duì)前一層的激發(fā)水平進(jìn)行歸一化處理,。由于![]() 的結(jié)果始終為正,連續(xù)求和可能會(huì)產(chǎn)生飽和問(wèn)題,,因此進(jìn)行歸一化處理,。在后續(xù)計(jì)算中使用平均值,,并且在計(jì)算中,平均值的計(jì)算會(huì)是指數(shù)形式,。具體公式如下:
的結(jié)果始終為正,連續(xù)求和可能會(huì)產(chǎn)生飽和問(wèn)題,,因此進(jìn)行歸一化處理,。在后續(xù)計(jì)算中使用平均值,,并且在計(jì)算中,平均值的計(jì)算會(huì)是指數(shù)形式,。具體公式如下:
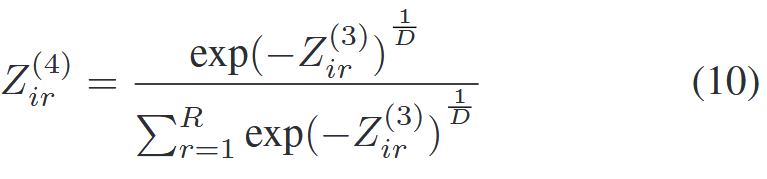
其中D是特征的數(shù)量,,R是模糊規(guī)則的數(shù)量。
5)批量歸一化(BN)層:BN是一種在深度學(xué)習(xí)中廣泛使用的優(yōu)化技術(shù),,被引入到TSK模糊分類優(yōu)化中,。它可以加快模型的收斂速度,并提高其泛化能力,。對(duì)于獲得的模糊規(guī)則樣本![]() 的BN結(jié)果如下:
的BN結(jié)果如下:
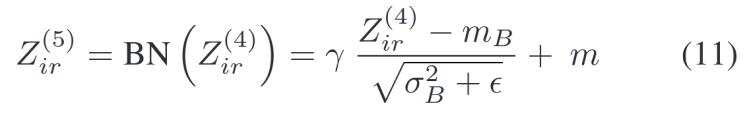
其中mB是樣本的均值,,σB是其標(biāo)準(zhǔn)差。γ和m是學(xué)習(xí)參數(shù),,?是一個(gè)小常數(shù),用于防止分母為零,。
可以使用BN操作來(lái)優(yōu)化TSK模糊系統(tǒng),,因?yàn)椴煌瑢?shí)驗(yàn)對(duì)象之間的數(shù)據(jù)分布問(wèn)題。本研究通過(guò)對(duì)不同規(guī)則的激發(fā)水平計(jì)算均值和標(biāo)準(zhǔn)差,,使用BN操作獲得新的規(guī)則水平,。最后,使用新的規(guī)則水平計(jì)算分類結(jié)果,。
6)去模糊化層:這一層實(shí)現(xiàn)了使用最小學(xué)習(xí)機(jī)(LLM)計(jì)算后驗(yàn)參數(shù),。LLM是用于加速單層或多層前饋神經(jīng)網(wǎng)絡(luò)的訓(xùn)練速度的一種算法。假設(shè)R?, R?, ..., RL表示第l層子層隨機(jī)選擇的模糊規(guī)則,,β?, β?, ..., βL表示第l層的輸出權(quán)重,。對(duì)于訓(xùn)練集D = {X, T},T是二分類問(wèn)題對(duì)應(yīng)的分類標(biāo)簽,。后驗(yàn)參數(shù)![]() ,。
,。
為了快速求解后驗(yàn)參數(shù)![]() ,本研究提前確定子層的數(shù)量,,獲得前一層的輸出,,然后計(jì)算當(dāng)前層的參數(shù)。最后求解帶有給定常數(shù)C的嶺回歸問(wèn)題,,使用LLM算法快速求解:
,本研究提前確定子層的數(shù)量,,獲得前一層的輸出,,然后計(jì)算當(dāng)前層的參數(shù)。最后求解帶有給定常數(shù)C的嶺回歸問(wèn)題,,使用LLM算法快速求解:
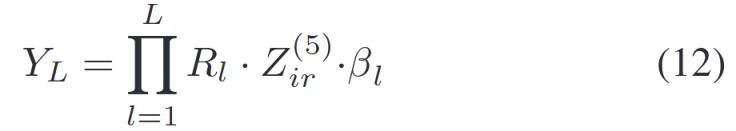
如果用矩陣形式表示:
![]()
其中![]() ,。因此,得到βL的解析公式為:
,。因此,得到βL的解析公式為:
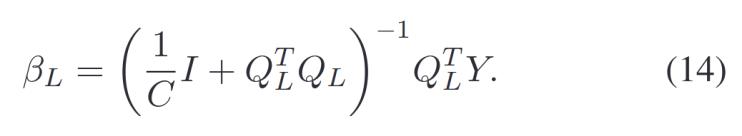
研究證明證明,,使用LLM算法的優(yōu)點(diǎn)是學(xué)習(xí)可以通過(guò)輸出層進(jìn)行,,而無(wú)需更多耗時(shí)的迭代操作。同時(shí),,本研究的重點(diǎn)是EEG,,即高維數(shù)據(jù),。如公式(14)所示,這種形式可以減少由于大量樣本數(shù)據(jù)而導(dǎo)致的許多復(fù)雜操作,。
C. 所有子分類器的線性組合
疲勞駕駛是一個(gè)連續(xù)的過(guò)程,,它會(huì)影響駕駛員的EEG信號(hào)。隨著時(shí)間序列的增加,,這些不確定性所導(dǎo)致的特征重要性會(huì)發(fā)生變化,。為了解決這一問(wèn)題,每個(gè)子分類器的輸入是由原始輸入空間的隨機(jī)投影和前一個(gè)子分類器生成的,。然而,,每個(gè)子分類器所學(xué)習(xí)到的特征仍然存在不確定性。因此,,為了確保更好的整體分類結(jié)果,,建議對(duì)多個(gè)子分類器進(jìn)行線性組合。
在CAI-TSK-FC中,,訓(xùn)練從零階子分類器Op-TSK?開(kāi)始,,它以原始數(shù)據(jù)作為輸入。初始假設(shè)是Op-TSK?僅包含五條模糊規(guī)則,,其輸出為Y?,,這與后續(xù)高層子分類器不同。接下來(lái),,CAI-TSK-FC將輸入提供給下一個(gè)TSK子分類器,。當(dāng)?shù)谝粚拥腡SK子分類器未能達(dá)到預(yù)期結(jié)果時(shí),CAI-TSK-FC將使用當(dāng)前層的輸入和輸出來(lái)形成下一層的輸入,,并隨機(jī)選擇當(dāng)前層的一條模糊規(guī)則來(lái)計(jì)算下一層的模糊規(guī)則,。此時(shí),輸入為![]() ,。如果第l層的TSK子分類器未能達(dá)到所需的性能,,則CAI-TSK-FC將繼續(xù)訓(xùn)練第l + 1層的數(shù)據(jù),并重復(fù)該過(guò)程,,直到在第L層獲得預(yù)期結(jié)果,。
,。如果第l層的TSK子分類器未能達(dá)到所需的性能,,則CAI-TSK-FC將繼續(xù)訓(xùn)練第l + 1層的數(shù)據(jù),并重復(fù)該過(guò)程,,直到在第L層獲得預(yù)期結(jié)果,。
如果用Y?, Y?, Y?, ..., YL表示所有子分類器基于輸入數(shù)據(jù)的輸出,則最后一層的輸出為:
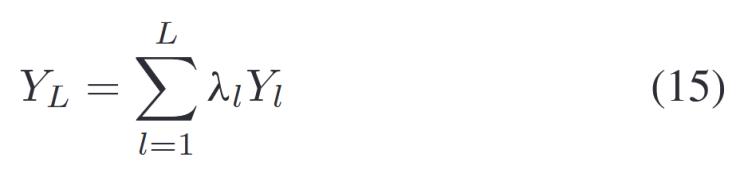
其中![]() 是每層的組合系數(shù),??紤]以下因素:
是每層的組合系數(shù),??紤]以下因素:
1)![]() 應(yīng)盡可能接近真實(shí)標(biāo)簽;
應(yīng)盡可能接近真實(shí)標(biāo)簽;
2)第一層的輸出應(yīng)與真實(shí)標(biāo)簽進(jìn)行正則化,;
3)第二層及后續(xù)子分類器的輸出應(yīng)盡可能接近前一層的最大輸出,。
公式如下:
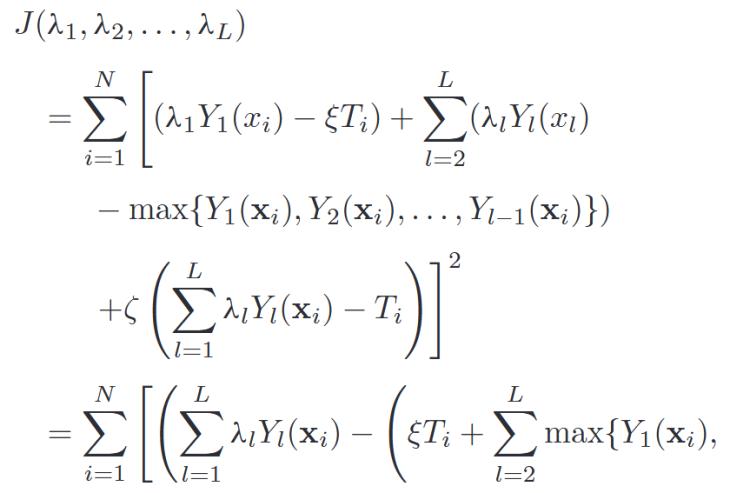
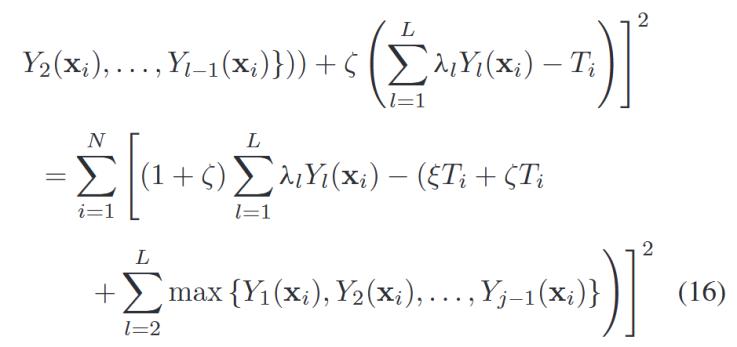
其中ε和ξ是兩個(gè)正則化系數(shù)。它們可以手動(dòng)設(shè)置并自動(dòng)調(diào)整。上述公式等價(jià)于:
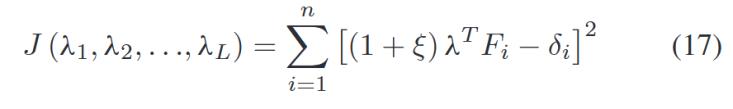
其中![]() ,,
,,![]() ,,
,,![]() 。
。
對(duì)λ求導(dǎo)并令其導(dǎo)數(shù)為零,,可以得到λ的解析解:
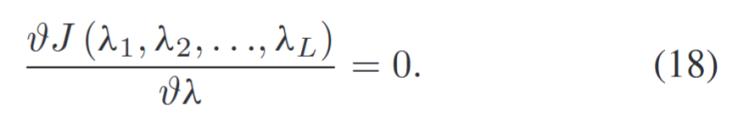
可以得到λ的解析解如下:
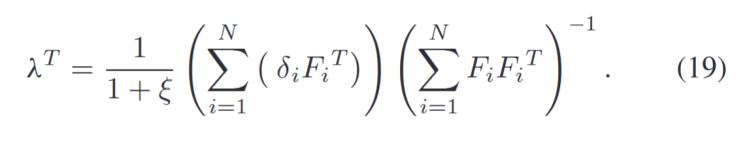
實(shí)驗(yàn)結(jié)果
本文的實(shí)驗(yàn)基于SEED-VIG公開(kāi)數(shù)據(jù)集和自制數(shù)據(jù)集,。本研究將CAI-TSK-FC與其他五種基于EEG的TSK模糊系統(tǒng)分類器進(jìn)行了比較,包括FS-FCSVM,、MV-TSKFC,、MV-TSK-FS-HSIC、TSK-JDA-FLS和TSK-TL,。在所有TSK模糊系統(tǒng)模型中將模糊規(guī)則的數(shù)量設(shè)置為5,,并將層數(shù)的初始值設(shè)置為3。
本研究將數(shù)據(jù)集隨機(jī)劃分為20%的測(cè)試集和80%的訓(xùn)練集,,并進(jìn)行了五折交叉驗(yàn)證,,使用平均結(jié)果來(lái)評(píng)估性能。準(zhǔn)確率,、召回率,、特異性、精確率和F1分?jǐn)?shù)被用作分類性能指標(biāo),。
A.分類結(jié)果
表1和表2分別展示了上述方法在自制數(shù)據(jù)集和SEED-VIG公開(kāi)數(shù)據(jù)集上的分類結(jié)果。
表1 自制數(shù)據(jù)集上不同方法的檢測(cè)結(jié)果對(duì)比
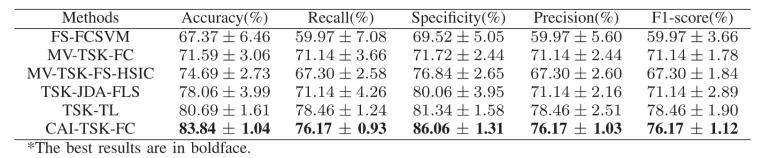
表2 SEED-VIG數(shù)據(jù)集上不同方法的檢測(cè)結(jié)果對(duì)比
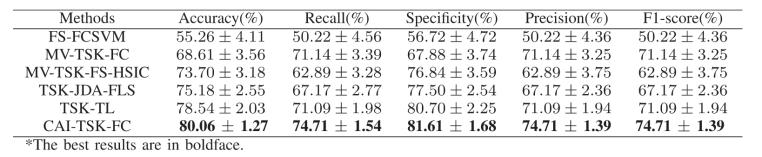
可以看出,,CAI-TSK-FC模型具有優(yōu)越的分類性能,。與次優(yōu)方法相比,CAI-TSK-FC在自制數(shù)據(jù)集和SEED-VIG公開(kāi)數(shù)據(jù)集上的準(zhǔn)確率分別提高了3.15%和1.52%,。這表明CAI-TSK-FC具有較高的識(shí)別性能,,主要原因如下:
1)CAI-TSK-FC采用深度集成框架,能夠獲取更多的數(shù)據(jù)特征信息,,從而更全面地區(qū)分不同的疲勞狀態(tài),。此外,CAI-TSK-FC在每一層中保留了一份模糊規(guī)則,,并將其添加到下一層,。
2)提出的CAI-TSK-FC優(yōu)化了每個(gè)子分類器中的原始TSK模糊系統(tǒng),并引入了批量歸一化(BN)和最小學(xué)習(xí)機(jī)(LLM),,以提高模型的計(jì)算能力,。
為了全面評(píng)估模型的分類性能,圖4和圖5中分別展示了兩個(gè)數(shù)據(jù)集中每個(gè)受試者的分類準(zhǔn)確率,。
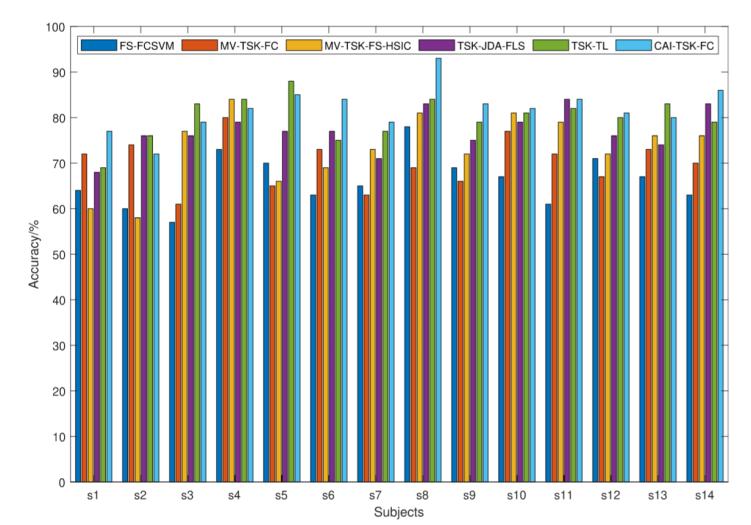
圖4 自制數(shù)據(jù)集中14名受試者的準(zhǔn)確率對(duì)比
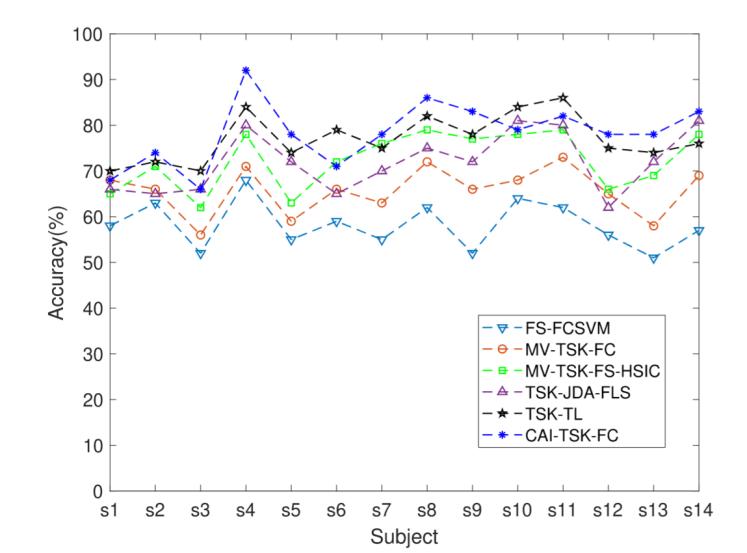
圖5 SEED-VIG數(shù)據(jù)集中14名受試者的準(zhǔn)確率對(duì)比
可以看出,,CAI-TSK-FC分類器在不同受試者之間具有顯著優(yōu)勢(shì)。基線模型FS-FCSVM的分類效果最低,。對(duì)于自制數(shù)據(jù)集,,第二名受試者的分類性能低于其他受試者,而第八名受試者的分類效果較高,。對(duì)于SEED-VIG公開(kāi)數(shù)據(jù)集,,第三名受試者的分類效果低于其他受試者,而第四名受試者的分類效果優(yōu)于其他受試者,。這表明不同模型在個(gè)體受試者之間存在差異,。上述結(jié)果表明,基于EEG的駕駛疲勞分類在不同受試者之間具有良好的效果,。
B.不平衡數(shù)據(jù)集的評(píng)估結(jié)果
接收者操作特征(ROC)曲線可以直觀地反映分類器的性能,,并提供在不同閾值下的性能比較,因此可以用來(lái)評(píng)估分類器在不平衡數(shù)據(jù)集上的性能,。本研究使用測(cè)試集的預(yù)測(cè)結(jié)果計(jì)算真正例(TP),、假正例(FP)、真負(fù)例(TN)和假負(fù)例(FN),,然后繪制ROC曲線,,并計(jì)算G均值和曲線下面積(AUC)值。
圖6和表3顯示了本研究的方法在ROC曲線上的表現(xiàn)良好,。
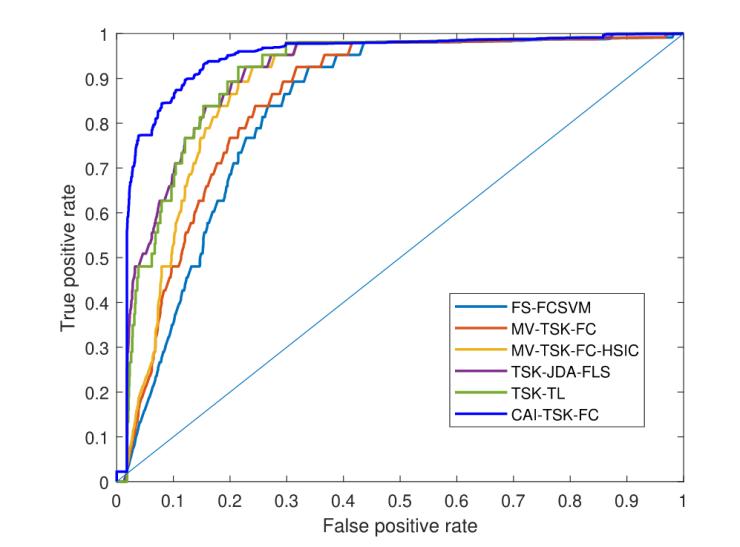
圖6 自制數(shù)據(jù)集上不同方法的ROC曲線
表3 自制數(shù)據(jù)集上不同方法的AUC和G均值

此外,,AUC值和G均值分別為0.9046和0.8197,也高于其他方法,。同時(shí),,本研究的模型在公開(kāi)數(shù)據(jù)集上的表現(xiàn)更好。不平衡數(shù)據(jù)集對(duì)模型效果的影響主要是由于學(xué)習(xí)資源不足以及正負(fù)樣本之間的差異較大,。為了解決這一問(wèn)題,,本研究利用改進(jìn)的零階TSK模糊系統(tǒng)提取關(guān)鍵特征,并積累多層模糊規(guī)則,,增強(qiáng)模型的學(xué)習(xí)資源,。此外,在訓(xùn)練過(guò)程中使用BN來(lái)壓縮錯(cuò)誤信息的積累,。最后,,通過(guò)線性組合減少每個(gè)模塊提取的錯(cuò)誤信息的權(quán)重,從而實(shí)現(xiàn)更有效的分類,。這種方法導(dǎo)致AUC和G均值得分的提高,。同樣,圖7和表4也驗(yàn)證了本研究的結(jié)果,。
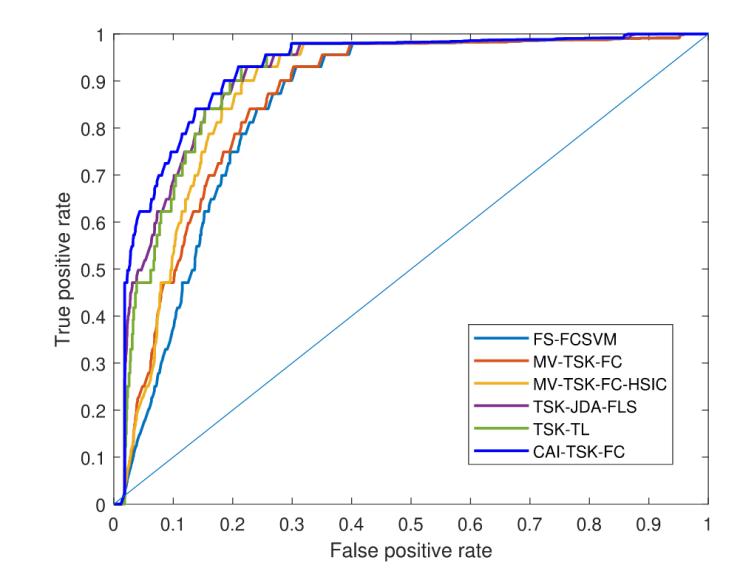
圖7 SEED-VIG數(shù)據(jù)集上不同方法的ROC曲線
表4 SEED-VIG數(shù)據(jù)集上不同方法的AUC和G均值

總之,,本研究的方法在解決不平衡問(wèn)題方面優(yōu)于其他比較方法,。
C.不同場(chǎng)景下的實(shí)驗(yàn)效果
根據(jù)受試者的實(shí)驗(yàn)結(jié)果,不同場(chǎng)景下的數(shù)據(jù)不平衡程度存在差異,。表5顯示了14名受試者的正負(fù)樣本數(shù)量,。表5表明,三種場(chǎng)景下的正負(fù)樣本數(shù)量存在顯著差異,,同時(shí)也表明不同場(chǎng)景下不平衡問(wèn)題的嚴(yán)重程度不同,。
表5 不同場(chǎng)景下正負(fù)樣本的數(shù)量

在本實(shí)驗(yàn)中,每種比較方法均進(jìn)行了十折交叉驗(yàn)證,,并計(jì)算平均準(zhǔn)確率以評(píng)估其分類效果,。圖8中的柱狀圖顯示了六種比較方法在三種不同場(chǎng)景下的分類效果。
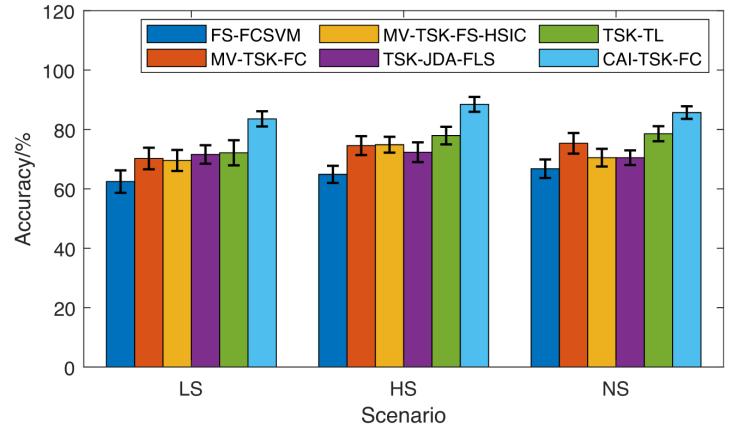
圖8 不同場(chǎng)景下六種方法的分類準(zhǔn)確率
本研究的方法的分類效果優(yōu)于其他任何方法,。根據(jù)圖8可以看到,,在LS場(chǎng)景下的準(zhǔn)確率略低于其他兩種場(chǎng)景。這可能是由于受試者在開(kāi)放道路場(chǎng)景下的疲勞程度較低,,且其數(shù)據(jù)集的不平衡性較為明顯,,導(dǎo)致模型學(xué)習(xí)資源不足。然而,,本研究提出的CAI-TSK-FC仍然表現(xiàn)良好,,這表明本研究采用的深度集成結(jié)構(gòu)能夠緩解這一問(wèn)題。
D.可解釋性
為了更好地展示CAI-TSK-FC的可解釋性,,在表6中列出了自制數(shù)據(jù)集第二層中每個(gè)子分類器的兩條可解釋規(guī)則,。
表6 CAI-TSK-FC在自制數(shù)據(jù)集第二層的模糊規(guī)則可解釋性結(jié)果
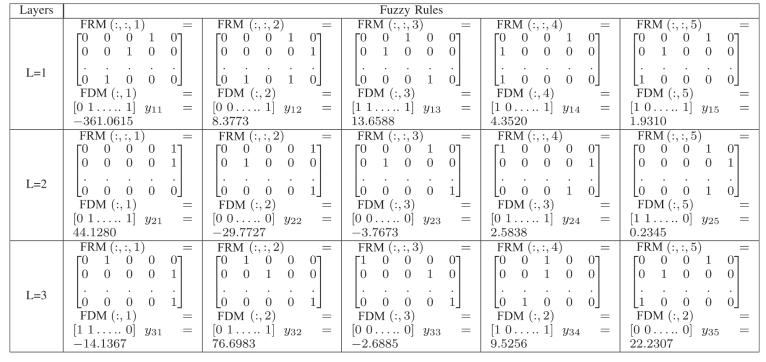
其中,F(xiàn)1,、F2和F25表示原始數(shù)據(jù)集的特征,,F(xiàn)26表示前一層的輸出特征。當(dāng)把輸入特征劃分為五個(gè)模糊子集時(shí),,它們的語(yǔ)義可以解釋為非常低(VL)、低(L),、中等(M),、高(H)和非常高(VH)。每一行都可以轉(zhuǎn)換為具有非線性部分的模糊規(guī)則,。例如,,根據(jù)公式(7),第二層的五條模糊規(guī)則如表6所示,。
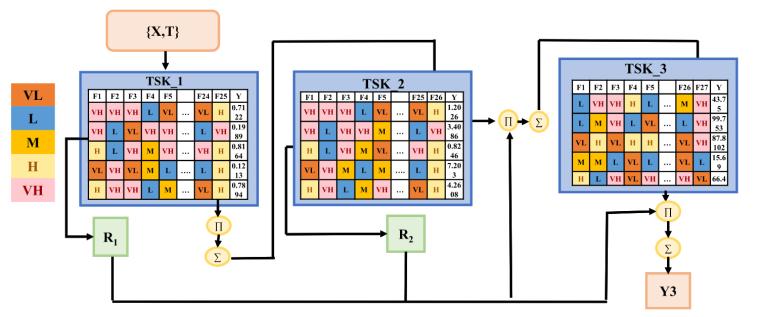
圖9 當(dāng)層數(shù)為3時(shí),,模型的模糊規(guī)則可解釋性結(jié)果展示
如圖9所示,經(jīng)過(guò)預(yù)處理后,,EEG信號(hào)數(shù)據(jù)在第二層有25個(gè)特征,。在第一層輸出后,增加了1-D特征,特征數(shù)量增加到26個(gè),。同時(shí),,本研究使用前一層的模糊規(guī)則對(duì)當(dāng)前層進(jìn)行累積計(jì)算,并使用公式(13)得到當(dāng)前層的分類結(jié)果,。為了在每個(gè)TSK子分類器中展示易于理解的輸出表達(dá)式,,在表VI中詳細(xì)列出了CAI-TSK-FC結(jié)構(gòu)的前三層的前五條模糊規(guī)則。隨機(jī)生成的模糊規(guī)則是所涉及特征的總和,,包括特征空間中的模糊劃分,。FRM和FDM分別表示規(guī)則生成矩陣和特征選擇矩陣。以L=1的第一條FRM為例,,F(xiàn)RM[1,4,1]=1表示第一條模糊規(guī)則中第一個(gè)特征的高斯隸屬函數(shù)中心為非常高(VH),,而FDM[5,1]=1表示第一條模糊規(guī)則中第五個(gè)輸入特征被選中進(jìn)入下一步計(jì)算,否則跳過(guò)該特征的計(jì)算,。其他層的模糊規(guī)則具有類似的含義,。
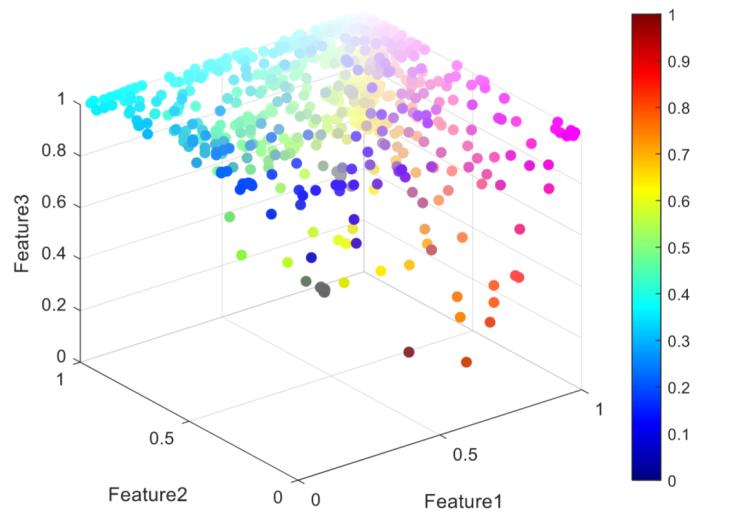
圖10 模糊隸屬矩陣特征的可視化
此外,本研究還可視化了模糊隸屬矩陣特征的前三個(gè)特征,,如圖10所示,。在模糊隸屬矩陣特征的可視化中,三個(gè)特征分別表示為x軸,、y軸和z軸,。根據(jù)這三個(gè)特征的值,確定每個(gè)樣本在3-D空間中的位置,。例如,,如果一個(gè)樣本在特征1上值較高,在特征2上值較低,,在特征3上值中等,,則其在3-D圖中的位置可能更靠近x軸的頂部、y軸的底部和z軸的中部,。這個(gè)3-D圖解釋了基于這三個(gè)特征的樣本分布,。還可以根據(jù)點(diǎn)的顏色和大小確定樣本在模糊集合中的隸屬度,紅色表示值為1,,藍(lán)色表示值為0,。樣本點(diǎn)在特征上的值越大,其對(duì)結(jié)果的影響就越大,。
例如,,在圖9中,第二層的FRM第一條模糊規(guī)則顯示,,第一條模糊規(guī)則中的第一個(gè)和第二個(gè)特征采用高斯隸屬函數(shù)中的非常高(VH),。第26個(gè)特征采用高斯隸屬函數(shù)中的高(H),。同樣,第二條,、第三條,、第四條和第五條模糊規(guī)則也可以進(jìn)行解釋。根據(jù)上述內(nèi)容,,可以看到CAI-TSK-FC具有良好的可解釋性,。
上述實(shí)驗(yàn)結(jié)果證實(shí),本研究提出的CAI-TSK-FC在預(yù)測(cè)駕駛疲勞方面具有良好的分類效果,、泛化能力和高可解釋性,,能夠應(yīng)對(duì)不同場(chǎng)景下的問(wèn)題。
總結(jié)
本研究提出了一種基于腦電信號(hào)的綜合自適應(yīng)可解釋Takagi-Sugeno-Kang模糊分類器(CAI-TSK-FC),,用于疲勞駕駛檢測(cè),。該方法通過(guò)以下策略實(shí)現(xiàn)顯著的效果檢測(cè):
盡管該方法在跨受試者和場(chǎng)景分類中表現(xiàn)良好,,但在噪聲數(shù)據(jù)處理和模型性能方面仍有改進(jìn)空間,。未來(lái)研究將探索如何適應(yīng)原始數(shù)據(jù)集,以提升實(shí)時(shí)分類能力,。
撰稿人:陳天健
審稿人:邱麗娜
載")
贊")







載")