 481
481
 0
0
 2025-04-30
2025-04-30
 2025-04-30
2025-04-30

該論文發(fā)表于Information Fusion(中科院一區(qū),,IF=14.8),,題目為《Multi-view domain-adaptive representation learning for EEG-based emotion recognition》。
天津師范大學(xué)計算機與信息工程學(xué)院的李超副教授為本論文的第一作者,,天津師范大學(xué)計算機與信息工程學(xué)院的趙子平教授為本論文的通訊作者,。
https://www.sciencedirect.com/science/article/pii/S1566253523004724
目前的研究表明,,腦電圖情緒識別存在一定的局限性,包括冗余和無意義的時間框架和通道,,以及來自不同受試者的腦電圖信號的個體內(nèi)差異,。為了解決這些限制,提出了一種基于交叉注意力的帶域判別器的擴張因果卷積神經(jīng)網(wǎng)絡(luò)(CADD-DCCNN),,用于基于多視圖EEG的情緒識別,,以最大限度地減少個體差異并自動學(xué)習(xí)更多判別性情緒相關(guān)特征。首先,,使用短時傅里葉變換(STFT)從原始EEG信號中獲得差分熵(DE)特征,。其次,將DE特征的每個通道視為一個視圖,,并在不同的視圖中利用注意力機制來聚合腦電時間框架水平上的判別性情感信息,。然后,采用擴張的因果卷積神經(jīng)網(wǎng)絡(luò)來提取不同時間框架之間的非線性關(guān)系,。接下來,,采用特征級融合,融合多通道特征,,旨在探索不同視圖之間潛在的互補信息,,增強特征的表示能力。最后,,為了最小化個體差異,,采用域鑒別器來生成域不變特征,將來自兩個不同域的數(shù)據(jù)投影到相同的數(shù)據(jù)表示空間中,。在兩個公共數(shù)據(jù)集SEED和DEAP上的實驗結(jié)果表明,,CADD-DCCNN方法優(yōu)于SOTA方法,為跨被試/跨會話EEG情感識別提供高效解決方案,。
在基于腦電圖的情緒識別方面,,近年來許多研究人員取得了重大進(jìn)展。然而,,基于EEG的情感識別仍面臨兩大核心挑戰(zhàn):個體差異問題與時空特征的有效提取,。首先,不同被試因腦結(jié)構(gòu),、生理狀態(tài)差異,,其EEG信號分布存在顯著偏移;同一被試不同會話的數(shù)據(jù)也因環(huán)境、情緒波動而產(chǎn)生分布差異,。傳統(tǒng)方法依賴被試專屬模型,,需大量標(biāo)注數(shù)據(jù),實際應(yīng)用受限?,F(xiàn)有域適應(yīng)方法(如MEERNet,、TDANN)雖嘗試緩解跨域問題,但多忽視通道間關(guān)聯(lián)與長時序依賴,,導(dǎo)致關(guān)鍵信息丟失,。其次,EEG信號具有高維度(多通道,、多時間幀)和低信噪比特性,,傳統(tǒng)手工特征(如微分熵)或單一深度學(xué)習(xí)模型(CNN、LSTM)難以有效篩選關(guān)鍵時空信息:冗余時間幀和無關(guān)通道干擾模型性能,,而局部與全局時序關(guān)系的割裂進(jìn)一步削弱特征區(qū)分性,。
針對上述問題,本文提出一種融合多視圖學(xué)習(xí)與域自適應(yīng)的新型框架CADD-DCCNN,,如圖1所示,。CADD-DCCNN由五個部分組成,分別是:輸入特征表示模塊,、多視圖跨注意力機制模塊(MvCA),、擴張因果卷積神經(jīng)網(wǎng)絡(luò)(DCCNN)、域鑒別器(Domain Discriminator)和標(biāo)簽分類器,,分別對應(yīng)圖1中的a,、b、d,、e,、f。其中,,多視圖跨注意力機制模塊又可細(xì)分為多視圖時間幀注意力(MvTFA),、和多視圖注意力(MvA)。該方法的核心在于多視圖跨注意力機制(MoCA)與對抗域適應(yīng)(Adversarial Domain Adaptation)的協(xié)同設(shè)計,,分別解決個體差異與時空特征選擇兩大核心挑戰(zhàn),,其本質(zhì)在于動態(tài)篩選關(guān)鍵特征并對齊跨域分布,從而實現(xiàn)高效,、泛化的情感表征學(xué)習(xí),。
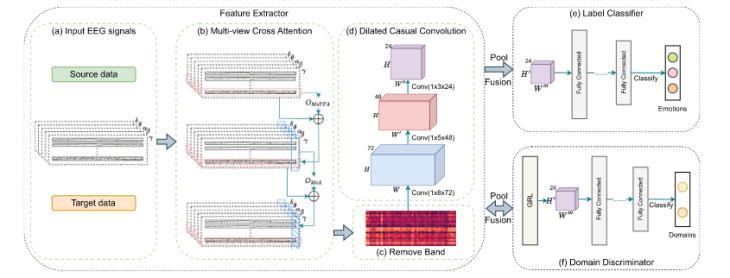
圖 1 模型框架
1、輸入特征表示模塊
由于DE特征在基于多視圖腦電圖的情緒識別中表現(xiàn)出顯著的性能,,因此使用從多視圖腦電圖信號中獲得的DE特征作為輸入,。在本文中,,使用SEED和DEAP數(shù)據(jù)集作為實驗數(shù)據(jù)集。在數(shù)據(jù)集中,,每位被試都有多次試驗,。對于每次試驗,使用STFT從每個通道的五個不同頻帶中提取DE特征,,其非重疊的Hanning窗口為1秒。對于SEED和DEAP數(shù)據(jù)集,,1秒窗口的DE特征大小分別為(62,,5)和(32,5),。接著將所有窗口的DE連接到一個代表一個Trial的特征向量中,,作為下一個模塊的輸入。
2,、多視圖跨注意力機制模塊(MvCA)
文章模型中的MvCA模塊包括兩個模塊:多視圖時間框架注意力(MvTFA)和多視圖注意力(MvA),。在文章中,將每個通道看做一個視圖,,在每個視圖中都使用了一種注意力機制來計算時間維度上的注意力權(quán)重,。最后,我們在多個視圖中采用類似的注意力機制來動態(tài)學(xué)習(xí)每個視圖的權(quán)重,,然后將它們與原始信號相結(jié)合,,以使用多視圖學(xué)習(xí)為EEG試驗構(gòu)建新的向量表示。
在多視圖時間幀注意力MvTFA(見圖2)中,,首先將輸入EEG信號(每個通道視為一個視圖)通過線性變換生成查詢(Q),、鍵(K)、值(V)三個矩陣,,實現(xiàn)將S轉(zhuǎn)化為三個不同的特征域:
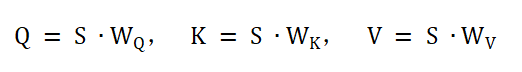
其中S為輸入序列(時間幀×特征維度),,,,為可學(xué)習(xí)權(quán)重矩陣, 分別表示查詢空間、鍵空間和值空間,。
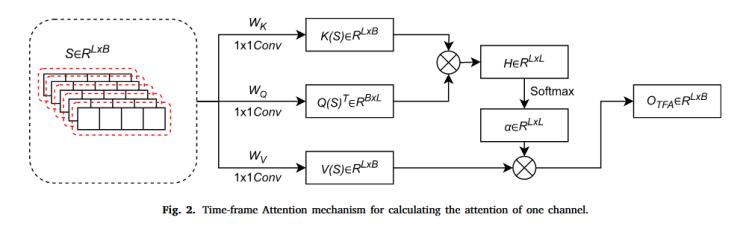
圖 2 多視圖時間幀注意力架構(gòu)
接著,,生成單個視圖的時間框架注意力,由下面描述的兩個方程計算獲得:
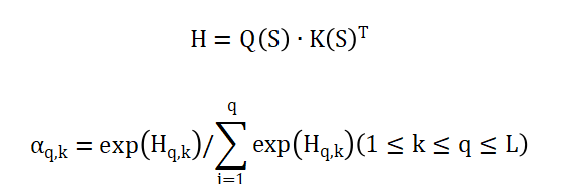
其中記錄了從前一個時間步k到當(dāng)前時間步q的特征的注意力,。為確保Hq,,k僅在k ≤ q時適用,當(dāng)m < n時,,通過將設(shè)置為零,,將H更新為H′。因此,,H′可以直接吸引長期和短期過去值的注意力,。通過對注意力進(jìn)行歸一化,得到了注意力矩陣,并與值矩陣V計算注意力:
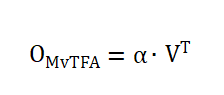
最終輸出:
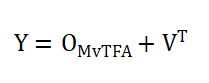
MvA的輸入是C視圖中時間步t的特征序列,,表示為=(, , ... , ),。使用與MvTFA模塊中用于計算α類似的過程,計算標(biāo)準(zhǔn)化的視圖注意力,。然后,,將視圖注意力應(yīng)用于,并將輸出表示為,。最后,,再次與Y合并,相加獲得隱藏狀態(tài)Z,。
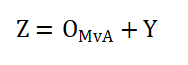
通過對MvCA的特征進(jìn)行1 × 1 × 1的卷積,,來壓縮頻段方向的維度并減少后續(xù)計算量。
3,、擴張因果卷積神經(jīng)網(wǎng)絡(luò)(DCCNN)
DCCNN是由擴張卷積和因果卷積相結(jié)合形成的,,如圖3所示。因果卷積確保時序建模的因果性,,即當(dāng)前時刻輸出僅依賴歷史輸入,,避免未來信息泄漏。擴張卷積擴大了感受野,,當(dāng)膨脹因子為1時,,擴張卷積等效于標(biāo)準(zhǔn)卷積神經(jīng)網(wǎng)絡(luò)。
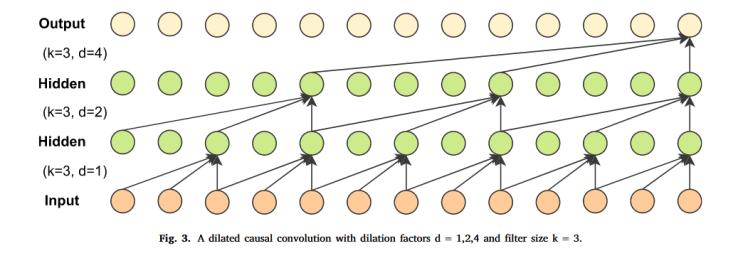
圖 3 DCCNN
其中其內(nèi)核大小k為3,,三個擴張層的膨脹因子d分別為1,、2和4。
對于輸入序列h(s),,擴張卷積輸出p(s)計算為:
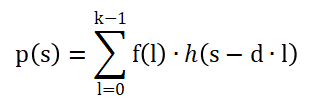
其中,,為卷積核權(quán)重,d為擴張因子,,k為核大小,。簡單來說,擴張卷積在不增加參數(shù)數(shù)量的情況下,,通過在不同的層設(shè)置不同的膨脹因子來合并不同大小的局部信息,。可以進(jìn)一步提取特征,,同時減少后續(xù)計算的參數(shù)數(shù)量,,從而提高計算速度。
4,、域鑒別器(DD)
通過對抗訓(xùn)練,,特征提取器被訓(xùn)練以生成混淆域鑒別器的特征,,域鑒別器被訓(xùn)練以區(qū)分特征來自源域還是目標(biāo)域,從而迫使特征提取器對齊分布,。使用平均池化來融合來自多視圖特征的深度表示,,并將輸入轉(zhuǎn)換為向量dm。引入梯度反轉(zhuǎn)層(GRL),,公式為:
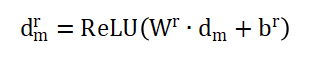
最后使用softmax函數(shù)推斷來自源域或目標(biāo)域輸入的概率:
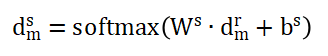
5,、標(biāo)簽分類器
先使用平均池化來融合多視圖特征,然后使用三個FC層和一個softmax函數(shù)進(jìn)行情緒預(yù)測,,函數(shù)為:
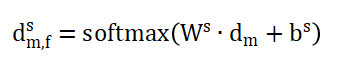
其中,,和是可學(xué)習(xí)的權(quán)重矩陣和偏置向量。
在論文中,,使用了SEED數(shù)據(jù)集和DEAP數(shù)據(jù)集作為驗證數(shù)據(jù)集。
1,、SEED數(shù)據(jù)集
在SEED數(shù)據(jù)集分別進(jìn)行了跨被試(SI)實驗和跨會話(SD)實驗,,并與其他方法比較,實驗結(jié)果見圖4,??梢钥吹剑疚牡腃ADD-DCCNN在SI任務(wù)上,,達(dá)到92.44%的平均準(zhǔn)確率,,顯著優(yōu)于現(xiàn)有方法(如MEERNet的87.10%、MS-MDA的89.63%),,表明其跨被試泛化能力突出,。而在跨會話場景中取得87.41%的準(zhǔn)確率,驗證了對同一被試不同時間數(shù)據(jù)的魯棒性,。
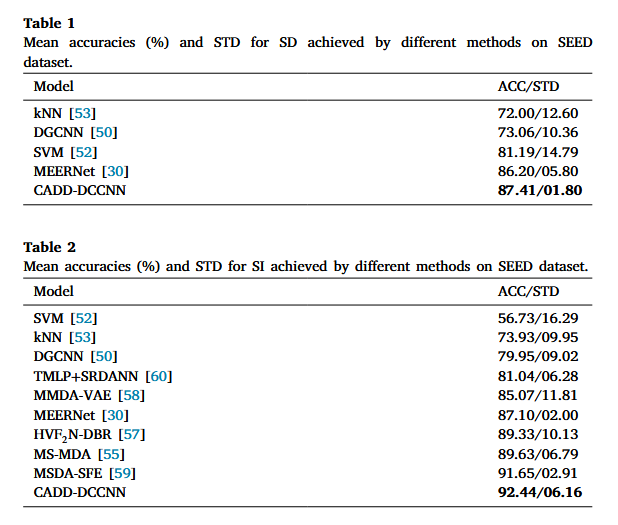
圖 4 SEED數(shù)據(jù)集的實驗數(shù)據(jù)結(jié)果
2,、DEAP數(shù)據(jù)集
在DEAP數(shù)據(jù)集上,進(jìn)行了效價分類的跨被試和跨會話實驗,,實驗結(jié)果如圖5所示,。在跨會話實驗中,與其他非域自適應(yīng)方法相比,,喚醒度的平均精度達(dá)到了92.42%,,優(yōu)于其他方法,而效價的平均精度也處于較高水平,,僅次于sparseD,。而在跨被試場景中,效價和喚醒度的平均精度分別為69.45%和70.50%,,盡管模型性能在SI場景遠(yuǎn)低于SD場景,,但仍優(yōu)于同在SI場景下的其他模型,。這些結(jié)果表明,文章提出的CADD-DCCNN方法在最小化個體內(nèi)和個體內(nèi)差異方面具有優(yōu)勢,。
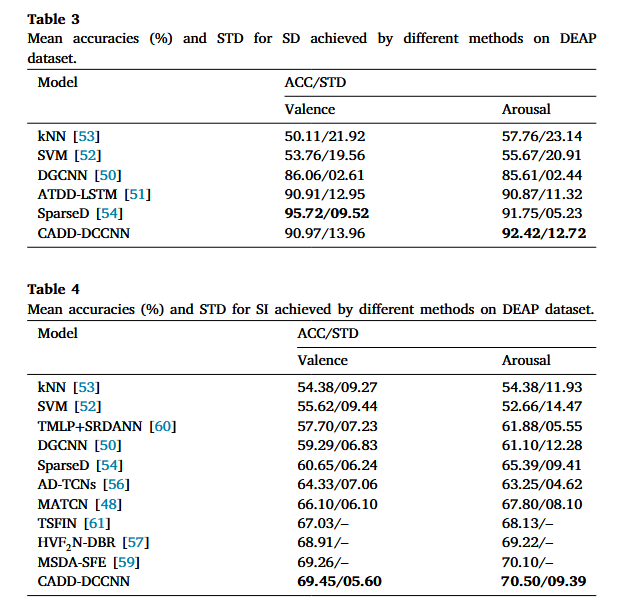
圖 5 DEAP數(shù)據(jù)集上的實驗數(shù)據(jù)結(jié)果
3,、消融實驗
文章在DEAP和SEED數(shù)據(jù)集上進(jìn)行消融實驗,從而驗證各個模塊對于模型提升的效果,,實驗結(jié)果如圖6所示,。圖中表格從上到下的模型分別表示:DANN:移除了多視圖交叉注意機制模塊和DCCNN的DANN模型;DCCNN-DANN:只有 DCCNN的DANN模型,;TFA-DANN:只有時間框架注意力機制的DANN模型,;MvCA-DANN:僅具有多視圖交叉注意機制的DANN模型。從實驗結(jié)果可以得到,,完整模型達(dá)到了最優(yōu)結(jié)果,,與DANN模型相比,準(zhǔn)確率提升了2.5%,,MvCA-DANN的準(zhǔn)確率比TFA-DANN高1.86%,,表明多個通道之間的信息是互補的。學(xué)習(xí)多渠道之間的互補信息可以有效提高模型的性能,,進(jìn)一步驗證多視圖學(xué)習(xí)的有效性,。
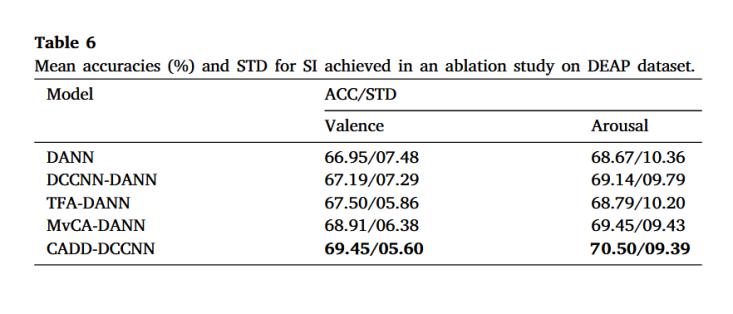
圖 6 消融實驗結(jié)果
本文提出了一種基于腦電信號的情緒識別方法CADD-DCCNN,在SEED和DEAP兩大基準(zhǔn)數(shù)據(jù)集上取得了最先進(jìn)(SOTA)的性能,。該方法的成功主要源于以下創(chuàng)新設(shè)計:首先,,通過多視角學(xué)習(xí)與注意力機制的結(jié)合,實現(xiàn)了對情緒相關(guān)通道和時間幀的有效篩選,;其次,,利用擴張因果卷積神經(jīng)網(wǎng)絡(luò)從多視角特征中提取時序信息;此外,,對多視角特征進(jìn)行特征級融合,,充分挖掘不同視角間的互補性信息。為進(jìn)一步提升跨被試場景下的模型泛化能力,,模型引入領(lǐng)域判別器,,通過統(tǒng)一特征分布覆蓋和保持?jǐn)?shù)據(jù)表征不變性,有效緩解數(shù)據(jù)分布偏移問題,。實驗通過消融研究驗證了各模塊的獨立貢獻(xiàn),,結(jié)果證明了其有效性。未來工作將重點驗證該方法在真實世界自然場景中的適用性,。
撰稿人:鄧杰超
審稿人:游琪
載")








載")