 247
247
 0
0
 2025-05-21
2025-05-21
 2025-05-21
2025-05-21

該論文發(fā)表于NeurIPS 2023(CCF A),題目為《Learning Topology-Agnostic EEG Representations with Geometry-Aware Modeling》,。
華南理工大學(xué)的柯毅為本文第一作者,微軟亞洲研究院首席研究員李東勝為本文的通訊作者,。
論文鏈接:https://papers.nips.cc/paper_files/paper/2023/file/a8c893712cb7858e49631fb03c941f8d-Paper-Conference.pdf
大規(guī)模的預(yù)訓(xùn)練在視覺和語言上的下游任務(wù)上顯示出增強模型的巨大潛力,。由于EEG的未標(biāo)記數(shù)據(jù)非常豐富,開發(fā)類似的頭皮腦電EEG預(yù)訓(xùn)練技術(shù)是合適的,。同時,,多樣的采樣通道選擇以及固有的結(jié)構(gòu)和空間信息為進一步改進現(xiàn)有的預(yù)訓(xùn)練策略帶來了挑戰(zhàn)和途徑。為了打破不同EEG資源之間的界限,,促進跨數(shù)據(jù)集的EEG預(yù)訓(xùn)練,,本文提出將各種通道選擇映射到一個統(tǒng)一的拓撲結(jié)構(gòu)。本文進一步引入了MMM(Multi-level hierarchy learning,Multi-dimensional position encoding,Multi-stage mask strategy),,一個具有多維位置編碼的預(yù)訓(xùn)練框架,,多級信道層次結(jié)構(gòu),建立在統(tǒng)一拓撲上的多階段預(yù)訓(xùn)練策略,,以獲得拓撲無關(guān)性,。MMM整體架構(gòu)如圖1。
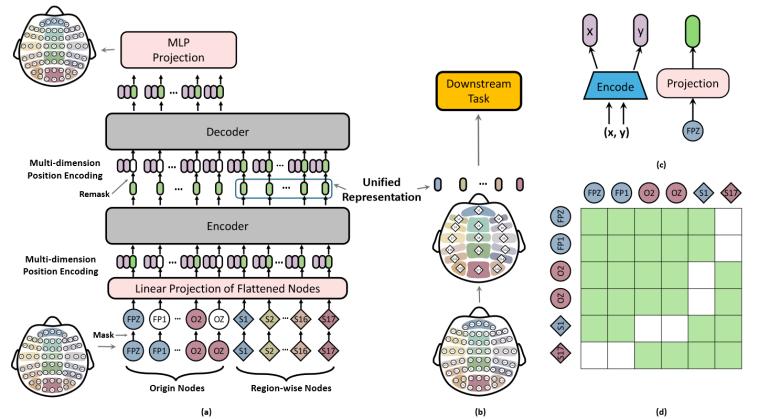
圖1 MMM整體架構(gòu)
研究背景
由于EEG數(shù)據(jù)能夠以非侵入和低成本的方式采集,,但需要大量的人力對其進行標(biāo)注,自監(jiān)督預(yù)訓(xùn)練方法被大量應(yīng)用于EEG片段的學(xué)習(xí)中,。雖然有許多公開可用的EEG數(shù)據(jù)集用于預(yù)訓(xùn)練,,但在它們之間進行遷移是非常具有挑戰(zhàn)性的,因為這些EEG記錄在蒙太奇(頭皮上放置電極的數(shù)量和位置)和采樣率方面可能會有很大的變化,。EEG預(yù)訓(xùn)練的另一個挑戰(zhàn)是對結(jié)構(gòu)進行編碼,,對來自不同位置的EEG信號之間的關(guān)系進行建模。這些信號由放置在頭皮上的電極采集,,可以看作是一個具有空間信息的二維流形,。這種空間信息對于專家提供精確的標(biāo)簽往往是至關(guān)重要的。綜上所述,為了得到一個有能力和強大的EEG預(yù)訓(xùn)練模型,,需要1 )將空間信息很好地編碼到表示中,,2 )使用具有不同傳感器配置的EEG語料預(yù)訓(xùn)練模型。
研究方法
本文提出了一種基于掩碼自動編碼器的自監(jiān)督學(xué)習(xí)框架MMM,,其使用DE特征聚合時間信息,,而MMM框架本身則用于探索EEG表示在空間結(jié)構(gòu)方面的學(xué)習(xí)。該框架主要包括以下幾個技術(shù)要點,。
(1)不同傳感器配置的統(tǒng)一拓撲
現(xiàn)有的來自不同機構(gòu)的EEG數(shù)據(jù)集大多使用不同的傳感器配置(32通道,、62通道等)。而同時,,最近的神經(jīng)科學(xué)研究表明,,大腦可以劃分為數(shù)個大腦功能組織。據(jù)此,,本文將大腦劃分為17個區(qū)域,,如圖1 ( b )所示。因此,,處理各種傳感器配置的挑戰(zhàn)可以看作是將具有不同傳感器配置Ex的數(shù)據(jù)x∈X映射到統(tǒng)一拓撲Z = Encoder ( x )的表示中,。
(2)MMM:基于統(tǒng)一拓撲的EEG預(yù)訓(xùn)練框架
本文介紹了一種基于統(tǒng)一拓撲結(jié)構(gòu)的EEG預(yù)訓(xùn)練框架MMM,該框架遵循掩蔽自編碼器( MAE ) 的訓(xùn)練模式(如圖1(a)所示),,即在預(yù)訓(xùn)練期間,,模型首先用編碼器將部分掩蔽的不規(guī)則輸入token( DE特征)編碼為統(tǒng)一表示,然后用解碼器從統(tǒng)一表示中重建掩蔽token,。
為了更好地支持EEG預(yù)訓(xùn)練,,本文設(shè)計了3種MMM:1 )多維位置編碼,它將幾何信息注入到tokens中,;2 )多級通道層次結(jié)構(gòu),,即在原始通道集合中添加代表區(qū)域的額外tokens;3 )多階段預(yù)訓(xùn)練,,交替使用全局隨機掩蔽和區(qū)域掩蔽兩種不同的掩蔽策略,,以有效地學(xué)習(xí)層次化表示。
(3)多維位置編碼
傳統(tǒng)的位置編碼只考慮加入通道間的順序信息,,這丟失了通道間的空間信息,。本文借助二維流形的思想,將多維位置編碼定義為:
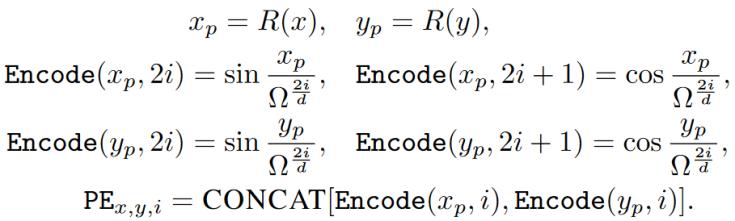
其中,,( x , y)為來自頭皮的二維坐標(biāo),,d為傳感器個數(shù),10 - 10系統(tǒng)網(wǎng)格對應(yīng)的( x , y)的d對構(gòu)成一個空間,。函數(shù)R將x,,y投影到其原始空間中的秩值,。i為編碼中特征維度的索引,?為一個大的常數(shù)(一般設(shè)置為10000),。最終的編碼是通過將x和y坐標(biāo)的編碼串接在一起生成的,。
多維位置編碼在兩個地方使用。首先將來自不同通道的DE特征經(jīng)過線性層處理后加入,,從而為數(shù)據(jù)注入幾何信息,。其次,在獲得表示后重新應(yīng)用編碼,。對重掩碼表示進行位置編碼,,告知解碼器如何區(qū)分重掩碼token。
(4)多級通道層次結(jié)構(gòu)
本文的模型骨干部分訓(xùn)練和基于Transformer的編碼器-解碼器作為掩碼自動編碼器模式相似,。但相較于傳統(tǒng)的直接將各原始通道節(jié)點直接放入transformer不同,,本文還引入了區(qū)域節(jié)點/區(qū)域標(biāo)記s∈R17 × D,并將其追加到序列末尾,,如圖1(a)下方所示,。同時為了避免區(qū)域節(jié)點之間的交互冗余,本文為為編/解碼器分配了一個固定的注意力掩碼,,圖1(d)為其中一個例子,。通過掩蔽建模的方式,該訓(xùn)練方式迫使模型能對EEG的統(tǒng)一拓撲結(jié)構(gòu)進行良好的建模,。
(5)不同掩蔽方式
為了讓MMM更好的學(xué)習(xí)到全局信號知識和區(qū)域信號知識,,本文相應(yīng)地引入兩種掩蔽策略,并在預(yù)訓(xùn)練過程中輪流使用,。其中全局隨機策略掩蔽通道的掩蔽信道數(shù)量固定,,區(qū)域掩蔽策略對同一區(qū)域內(nèi)的通道全部掩蔽或全部不掩蔽,如圖2所示,。
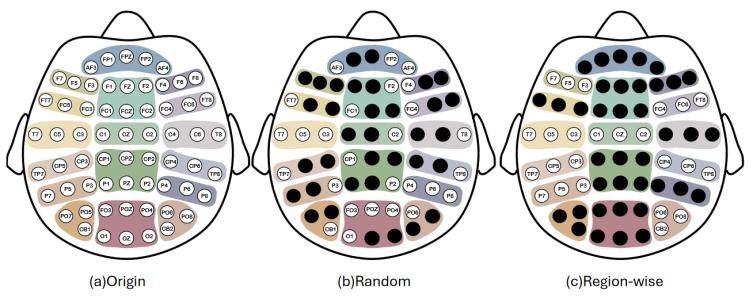
圖2 掩蔽策略
實驗結(jié)果
(1)被試相關(guān)分類任務(wù)
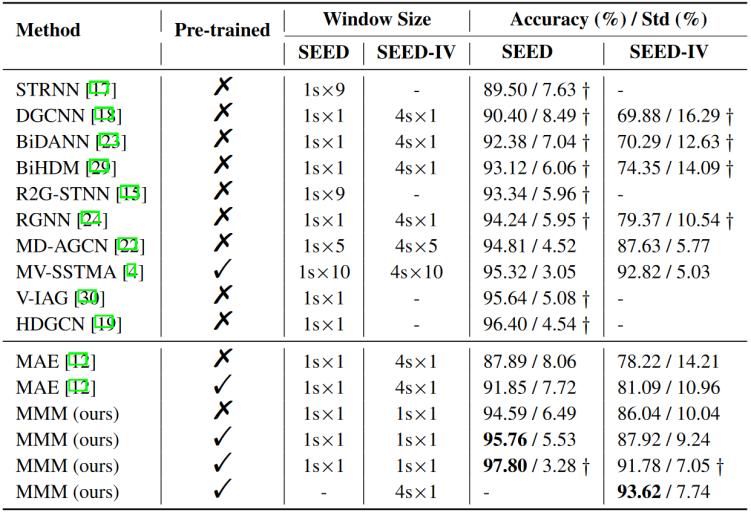
本文在SEED和SEED - IV的被試相關(guān)情況下的不同設(shè)置下與既定的基線進行了比較,,結(jié)果如表1所示。窗口大小是構(gòu)建輸入的特征長度,。例如,,4s × 5表示每個DE特征聚合4秒的原始EEG信號,五個連續(xù)的DE特征被用作模型輸入,。匕首符號代表在計算最終的平均準(zhǔn)確率時,,每個受試者排除3個中表現(xiàn)最差的會話。
表1 MMM方法與其他方法在SEED和SEED - IV上的實驗結(jié)果
(2)不同數(shù)據(jù)集間的知識遷移
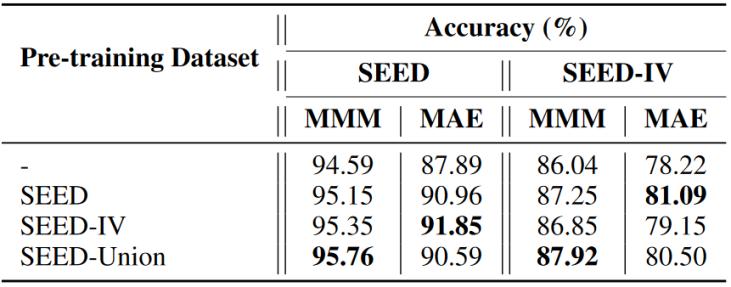
在這一部分中,,本文研究了模型在具有相同傳感器配置的數(shù)據(jù)集上的可遷移性。本文在原始數(shù)據(jù)集上預(yù)訓(xùn)練模型,,包括SEED,、SEED - IV以及它們的組合,。隨后,在目標(biāo)數(shù)據(jù)集SEED和SEED - IV上評估這些預(yù)訓(xùn)練模型的微調(diào)性能,。
表2 基于SEED和SEED-IV的數(shù)據(jù)遷移實驗結(jié)果
(3)不同通道設(shè)置數(shù)據(jù)集間的知識遷移
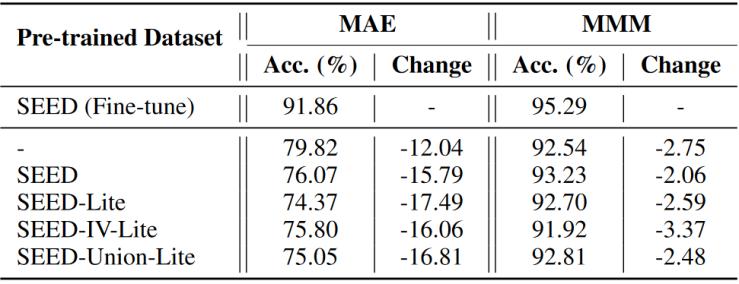
在這一部分中,,本文進一步研究了本文的方法在不同傳感器配置下的可遷移性。本文使用Lite系列數(shù)據(jù)集預(yù)訓(xùn)練模型,,然后在完整的SEED數(shù)據(jù)集上進行部分微調(diào),,即凍結(jié)編碼器的參數(shù),只調(diào)整最后一個MLP,,如表3所示,。MMM在SEED - Lite和SEED - Union - Lite數(shù)據(jù)集上預(yù)訓(xùn)練的模型均優(yōu)于從頭訓(xùn)練的模型。
表3 在SEED數(shù)據(jù)集上的部分微調(diào)結(jié)果
(4)從大規(guī)模腦電語料中進行知識遷移
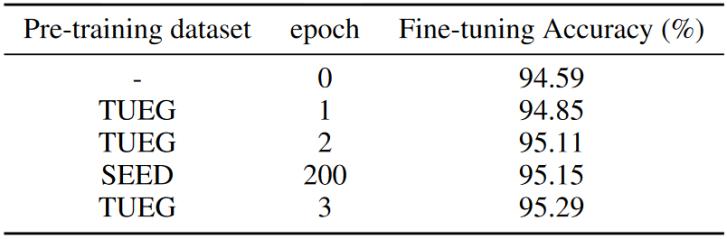
模型在TUEG數(shù)據(jù)集上進行預(yù)訓(xùn)練,,( - )表示從頭開始訓(xùn)練得到的模型,。然后,在SEED數(shù)據(jù)集上對模型進行微調(diào)和測試,。鑒于之前的研究發(fā)現(xiàn)了本文的方法在不同數(shù)據(jù)集和蒙太奇中的有效性,,接著將方法部署在TUEG數(shù)據(jù)集上。值得注意的是,,盡管TUEG數(shù)據(jù)集收集了10 - 20系統(tǒng)中涉及21個通道的不同通道配置的數(shù)據(jù),,但其在預(yù)訓(xùn)練中的應(yīng)用仍然是有益的,如表4所示,。
表4 大規(guī)模預(yù)訓(xùn)練
(5)區(qū)域劃分的影響
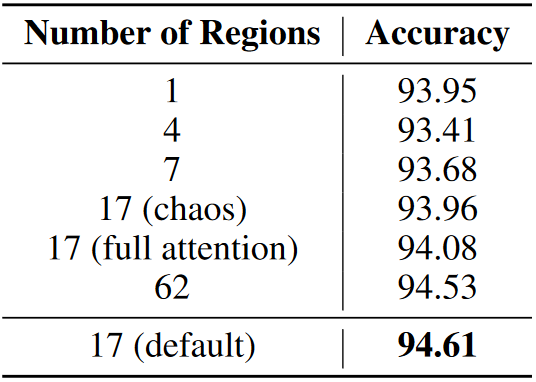
在這一部分,,本文深入分析了MMM中不同的統(tǒng)一拓撲對SEED數(shù)據(jù)集的影響。本文將默認(rèn)的17區(qū)域設(shè)置與幾種變體進行了比較:
表5 不同區(qū)域劃分選擇的變體結(jié)果
結(jié)論
在這項研究中,,本文提出了一種用于EEG預(yù)訓(xùn)練的創(chuàng)新框架MMM,,它有效地導(dǎo)航了EEG數(shù)據(jù)中與各種傳感器配置相關(guān)的復(fù)雜性,并很好地編碼了EEG的空間信息,。本文的模型采用了基于掩碼自動編碼器的自監(jiān)督學(xué)習(xí)方法,,使其能夠從大量的跨數(shù)據(jù)集語料庫中獲益,并提高下游任務(wù)的性能,。本文的框架在情緒識別任務(wù)中展示了最先進的性能,,進一步的評估證實了其方法的有效性。
撰稿人:肖睿
審稿人:李景聰
載")








載")