 40
40
 0
0
 2025-06-13
2025-06-13
 2025-06-13
2025-06-13

該論文發(fā)表于IEEE Transactions on Pattern Analysis and Machine Intelligence(中科院一區(qū),,IF=24.314),題目為《Cross-Modal Hashing Method With Properties of Hamming Space:A New Perspective》,。
香港浸會大學(xué)的胡志凱為此文第一作者,。香港浸會大學(xué)人工智能講席教授及香港研資局高級 研究學(xué)者張曉明為此文的通訊作者。
論文鏈接:https://ieeexplore.ieee.org/document/10506992
跨模態(tài)哈希(Cross-modal hashing, CMH)是一種用于處理不同數(shù)據(jù)類型(如圖像和文本)的技術(shù),,旨在將這些不同類型的數(shù)據(jù)映射到一個共同的二進制碼空間(漢明空間),,以便進行高效的檢索和匹配。現(xiàn)有的CMH方法主要集中在減少模態(tài)差距和語義差距上,,即在漢明空間中對齊多模態(tài)特征及其語義,,而沒有考慮到空間差距,即實數(shù)空間與漢明空間之間的差異,這引發(fā)了兩個問題:解空間壓縮和損失函數(shù)振蕩,。基于上述問題提出了一種新的算法,,即語義通道哈希(Semantic Channel Hashing, SCH),。首先,將樣本對根據(jù)其相似性分類為完全語義相似,、部分語義相似和語義負(fù)相關(guān),,并分別施加不同的約束條件,以確保整個漢明空間得到利用,。然后,,引入一個語義通道來緩解損失函數(shù)振蕩的問題。在三個公共數(shù)據(jù)集MIRFlickr,、NUS-WIDE和IAPR TC-12上的實驗結(jié)果表明,,SCH優(yōu)于經(jīng)典的基于淺層特征的CVH、STMH,、CMSSH,、SCM、SePH等基線方法,,以及幾種最新的端到端跨模態(tài)哈希方法,,如DCMH、ATFH-N,、CHN,、SSAH、EGDH,、AGAH,、MSSPQ、HMAH,、MAFH和MIAN,。
研究背景
為了實現(xiàn)低存儲成本下的快速檢索,人們開發(fā)了哈希技術(shù),,形成了跨模態(tài)哈希(Cross-modal hashing, CMH)方法的一個新分支,。然而,由于多模態(tài)數(shù)據(jù)最初存儲在實數(shù)空間中,,但后來映射到漢明空間,,因此需要彌合這兩個空間之間的一個額外的空間差距。現(xiàn)有的CMH方法主要通過聚集語義相似的樣本和分離語義不相似的樣本來解決語義差距問題,。例如使他們正交或者盡可能將它們分開,,這兩種方法都會引發(fā)解空間壓縮的問題,具體來說,距離為k的漢明空間中,,樣本的正交化會導(dǎo)致樣本在對應(yīng)的漢明空間中聚集在距離為0-k的某一位置,,極度相似和非相似的樣本則會在漢明空間中距離為0或k的邊緣聚集,即檢索集中的樣本被迫分布在有限的空間內(nèi),。此外,,在當(dāng)前流行的監(jiān)督式CMH范式中,樣本對標(biāo)簽之間的相似性s通常作為監(jiān)督信息來指導(dǎo)學(xué)習(xí)它們對應(yīng)的哈希碼,,這些哈希碼的相似性記為c,。為此,我們通常定義一個損失函數(shù)f(s, c),,并通過最小化它來學(xué)習(xí)哈希函數(shù)和哈希碼,,由于f通常是連續(xù)的而哈希碼的相似性值是離散的,這意味著即使找到了最優(yōu)解,,相應(yīng)的樣本對仍將繼續(xù)對梯度做出貢獻(xiàn),,并可能在下一個epoch跳出最優(yōu)解,導(dǎo)致?lián)p失函數(shù)振蕩的問題,。
方法
針對上述問題,,本文提出了一種新的CMH方法,即語義通道哈希(SCH),。為了避免解空間壓縮的問題,,我們根據(jù)標(biāo)簽計算的相似性將樣本對分為三類:完全語義正樣本、部分語義正樣本和語義負(fù)樣本,。然后,,對它們對應(yīng)的哈希碼施加不同的約束,確保整個漢明空間得到有效利用,。具體而言,,在距離為k的漢明空間中,完全語義正樣本應(yīng)盡可能靠近彼此,,而部分語義正樣本則以有序的方式分布在相對接近的范圍內(nèi),,語義負(fù)樣本之間的距離需要大于k/2。此外,,為了緩解損失函數(shù)的振蕩問題,,我們將第一步分配給不同樣本的漢明距離擴展到語義通道中,確保在最優(yōu)解處損失函數(shù)的梯度為零,。
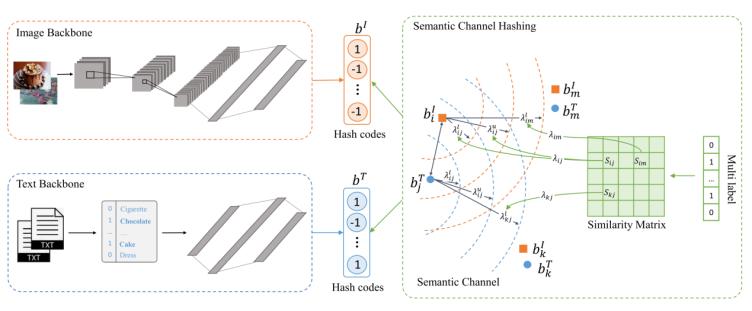
圖1 語義通道架構(gòu)圖
1. 語義通道哈希(SCH)
如圖1所示,,本文關(guān)注圖像和文本模態(tài)的跨模態(tài)檢索任務(wù),具體來說,,數(shù)據(jù)集由n個圖像-文本對組成 ,,其中、分別代表第i個圖像和文本樣本, 則表示文本或圖像第i個樣本的哈希碼,,SCH的核心思想為基于樣本和計算他們之間的相似性,。在訓(xùn)練階段,首先計算標(biāo)簽以及之間的余弦距離用來表示最初的相似性,,公式如下:
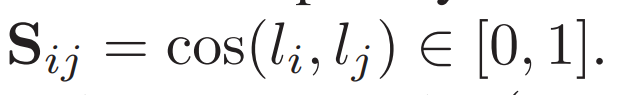
如果樣本和的標(biāo)簽完全不同,,即語義負(fù)樣本,
如果樣本和共享一些標(biāo)簽,,即部分語義正樣本,,
如果樣本和的標(biāo)簽完全相同,,即完全語義正樣本,,
隨后計算哈希碼和的漢明距離,公式如下:
![]()
直觀上,,如果兩個樣本具有相似的語義關(guān)系,,我們期望這兩個哈希碼之間的余弦值較大,反之亦然,。因此哈希碼和之間適當(dāng)?shù)臐h明距離可以表示為:
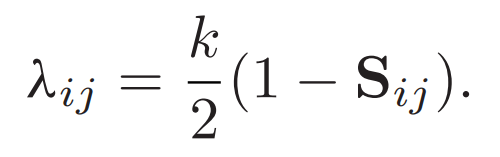
2. 損失函數(shù)
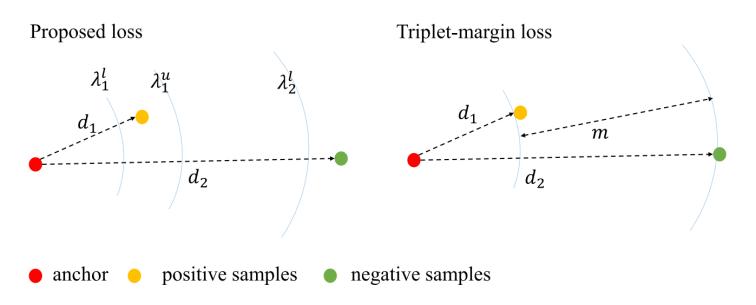
圖2 損失函數(shù)架構(gòu)圖
對于語義負(fù)樣本,,我們希望他們對應(yīng)的哈希碼在漢明空間中相距較遠(yuǎn),因此可以設(shè)置下界為k/2,,確保漢明距離超過下界,,從而保證語義負(fù)性,具體公式如下:

對于部分語義正樣本,,目標(biāo)是使部分語義正樣本的哈希碼在漢明空間中接近但不過于接近,,因此可以使用的上下界來約束哈希碼之間的距離,具體公式如下:
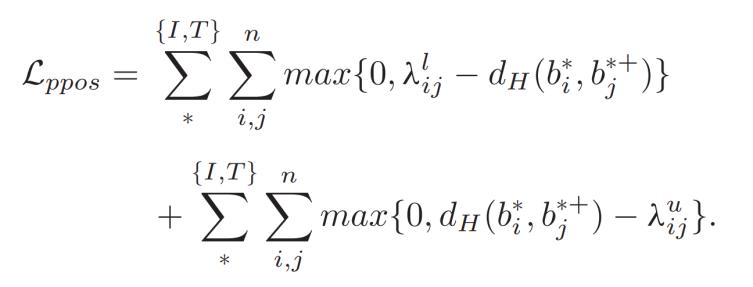
對于完全語義正樣本,,他們之間的相似性,,所以只需要確保其在漢明空間中的距離非常接近,因此可以通過控制的上界來實現(xiàn),,確保哈希碼之間的距離不超過該上界,,具體公式如下:
![]()
總體的損失函數(shù)為三者之和,公式如下:
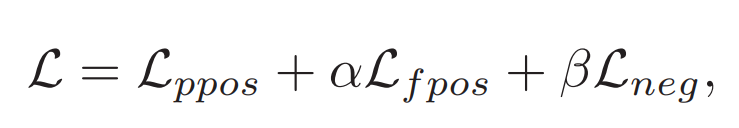
其中的超參數(shù)α和β用于平衡不同類型的損失
實驗和結(jié)果
本文使用了MIRFlickr,、NUS-WIDE和IAPR TC-12三個公共數(shù)據(jù)集
1. MIRFlickr數(shù)據(jù)集
包含25,000個圖像-文本對,,涵蓋24個不同的概念,其中圖像使用原始RGB特征表示,,每個文本由一個1,000維的詞袋(BoW)向量表示,。
數(shù)據(jù)預(yù)處理:
排除了文本標(biāo)簽出現(xiàn)少于20次的樣本,最終得到20,015個圖像-文本對,,從中選取2,000對作為測試集,,剩余的18,015對用于檢索,隨機從檢索集中選擇10,000個樣本作為訓(xùn)練集。
2. NUS-WIDE數(shù)據(jù)集
包含260,648個圖像-文本對,,每個對至少有一個來自81個可能概念的標(biāo)簽,,其中圖像使用原始RGB特征表示,每個文本由一個1,000維的詞袋(BoW)向量表示,。
數(shù)據(jù)預(yù)處理:
只選擇了屬于前10個最頻繁概念的樣本,,最終得到186,577對,從這些對中,,選取2,000對作為測試集,,剩余的184,577對用于檢索,隨機從檢索集中選擇10,000個樣本作為訓(xùn)練集,。
3. IAPR TC-12數(shù)據(jù)集
包含20,000個圖像-文本對,,每個對都用一組255個語義類別的多標(biāo)簽標(biāo)注,每個圖像由一個4,096維的向量表示,,該向量是由預(yù)訓(xùn)練的CNN-F 提取的,,每個文本由一個2,912維的詞袋(BoW)向量表示。
數(shù)據(jù)預(yù)處理:
隨機選取2,000對作為測試集,,剩余的對同時用于訓(xùn)練和檢索,。
表1 MIRFlickr數(shù)據(jù)集和NUS-WIDE數(shù)據(jù)集的實驗結(jié)果
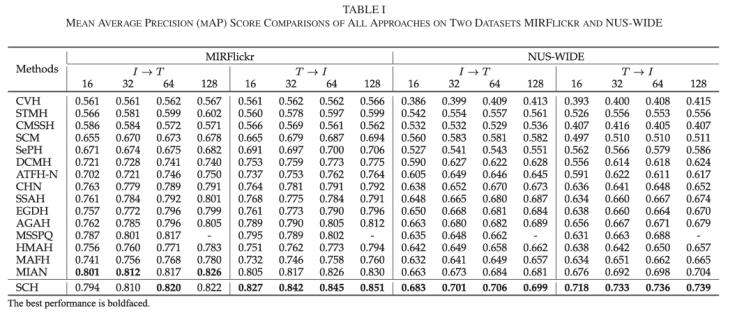
表2 IAPR TC-12數(shù)據(jù)集的實驗結(jié)果
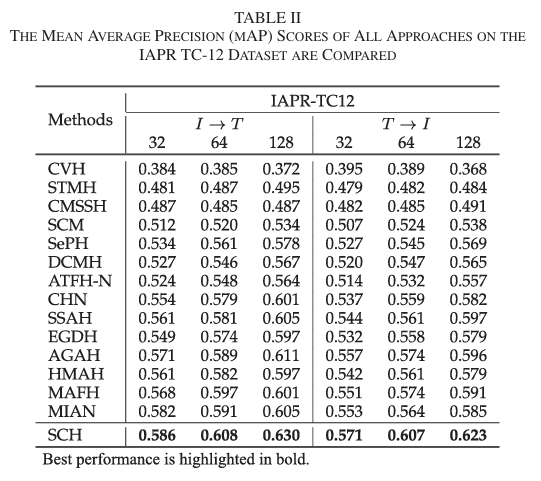
從表1和表2中可以看出,和基于正交約束的經(jīng)典方法(如SePH),、深度學(xué)習(xí)方法(如DCMH,、SSAH和MIAN),以及基于三元組邊緣損失的方法(如AGAH)相比,,SCH在大多數(shù)情況下表現(xiàn)最佳,。
此外,SCH使用了一個基本的雙塔模型和直接的網(wǎng)絡(luò)架構(gòu),,并沒有特別強調(diào)不同模態(tài)間哈希碼的對齊,。相比之下,其他方法如SSAH和MIAN采用了專門化的網(wǎng)絡(luò)結(jié)構(gòu)來處理文本數(shù)據(jù),,以提取更具信息量的文本表示,。此外,ATFH-N,、SSAH和AGAH引入了對抗網(wǎng)絡(luò)來對齊哈希碼,,而SSAH還額外引入了一個網(wǎng)絡(luò)來增強標(biāo)簽信息的監(jiān)督信號。盡管如此,,SCH依舊顯示了較好的實驗效果,,這證實了其在彌合空間差距方面的有效性。
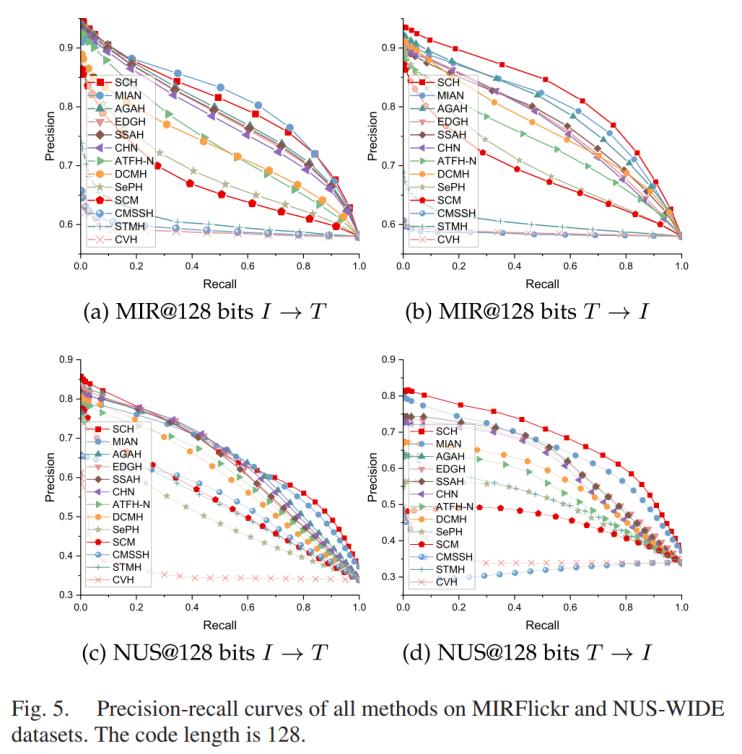
圖3 精度-召回曲線
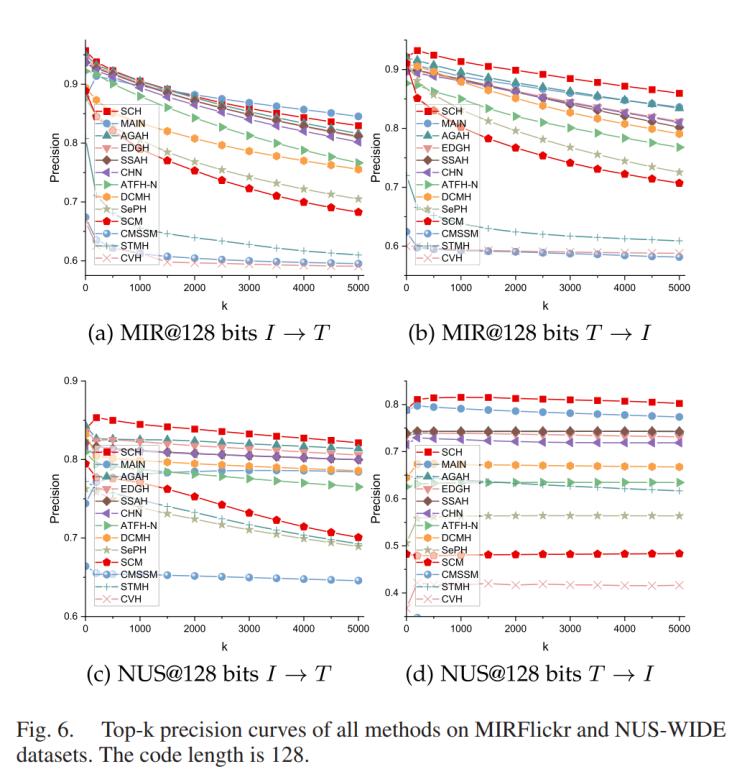
圖4 Top-K精度曲線
如圖3和圖4所示,,在MIRFlickr和NUS-WIDE數(shù)據(jù)集上得出的128位哈希碼長度的精度-召回曲線以及Top-K精度曲線顯示SCH在相同的召回率下始終能夠達(dá)到最佳或次佳的精度結(jié)果,,特別是在T→I任務(wù)中,。這一觀察表明,在檢索集合中哈希碼的分布已經(jīng)顯著優(yōu)化了漢明距離,,從而導(dǎo)致具有相似語義的樣本聚集在一起,。
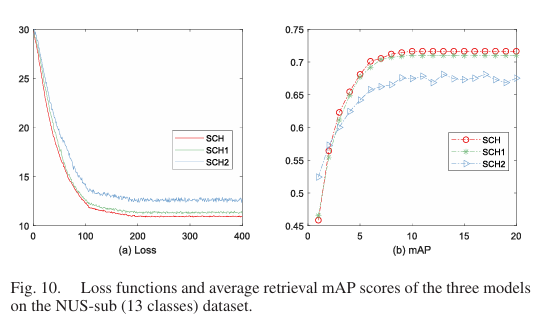
圖5 損失函數(shù)變化圖
此外,本文實現(xiàn)了SCH的兩個變體:SCH1(將語義通道寬度τ設(shè)置為0)和SCH2(用正交約束替換對語義負(fù)樣本的約束,,并且τ=0),。這兩個模型以及SCH在NUS子數(shù)據(jù)集(13個類別)上進行了評估,如圖5所示,,SCH的損失函數(shù)表現(xiàn)出最平滑的行為,,這說明沒有語義通道意味著損失函數(shù)在最優(yōu)解處的梯度不能保證為零。其次,,嚴(yán)格的正交約束導(dǎo)致了解空間的壓縮,,使得某些被擠壓的樣本持續(xù)對梯度做出貢獻(xiàn)。
結(jié)論
本文提出了一種新穎的方法SCH,,通過將樣本對分類為完全語義正樣本,、部分語義正樣本和語義負(fù)樣本,,并賦予它們不同的漢明距離,,解決現(xiàn)有方法中存在的解空間壓縮問題,從而充分利用整個漢明空間,。此外,,通過引入語義通道的概念來緩解損失函數(shù)的振蕩。在三個公共數(shù)據(jù)集上的實驗結(jié)果證明了SCH的有效性,。
撰稿人:馮宇
審稿人:梁瑾
載")








載")