 1725
1725
 0
0
 2024-11-23
2024-11-23
 2024-11-23
2024-11-23

該論文的標(biāo)題為《EEGPT: Unleashing the Potential of EEG Generalist Foundation Model by Autoregressive Pre-training》,,雖然作者信息未提及,,但它被提交至ICLR 2025 Conference(2025年國(guó)際學(xué)習(xí)表征會(huì)議)。盡管在雙盲評(píng)審過(guò)程中沒(méi)有獲得認(rèn)可,,這篇論文仍然展示了預(yù)訓(xùn)練大型模型在腦電圖(EEG)處理領(lǐng)域的應(yīng)用潛力。
論文鏈接:https://openreview.net/forum?id=wJ6Bx1IYrQ
腦電圖(EEG)信號(hào)在揭示自發(fā)性大腦活動(dòng)方面至關(guān)重要,,對(duì)神經(jīng)科學(xué)研究具有顯著的重要性,。然而,由于數(shù)據(jù)格式的多樣性,、預(yù)訓(xùn)練范式的過(guò)時(shí)以及遷移學(xué)習(xí)方法的局限性,,通用EEG模型的發(fā)展受到了限制,目前僅存在針對(duì)單一數(shù)據(jù)集的專用模型,。本研究提出了首個(gè)通用EEG基礎(chǔ)模型EEGPT,,旨在解決這些挑戰(zhàn)。
首先,,本研究提出了一種電極式建模策略,,將每個(gè)電極作為基本處理單元,從而成功整合源自多達(dá) 138 個(gè)電極的不同 EEG 數(shù)據(jù)集,,為模型預(yù)訓(xùn)練積累了 3750 萬(wàn)樣本,。其次,本研究開(kāi)創(chuàng)性地引入首個(gè)自回歸EEG 預(yù)訓(xùn)練模型,,能夠更有效地捕捉數(shù)據(jù)中的時(shí)序依賴關(guān)系,。此外,本研究提出一種多任務(wù)遷移學(xué)習(xí)范式,,構(gòu)建跨任務(wù)共享的可學(xué)習(xí)電極圖網(wǎng)絡(luò),,且證實(shí)了多任務(wù)間的兼容性和協(xié)同增效作用。
EEGPT 具備廣泛的兼容性,,可適配各種信號(hào)采集設(shè)備,、不同受試者及多種任務(wù),,支持多達(dá) 138 個(gè)電極及其任意組合作為輸入。在性能表現(xiàn)上,,如圖1所示,,通過(guò)在 12 個(gè)基準(zhǔn)的數(shù)據(jù)集上的 5 個(gè)下游任務(wù)中進(jìn)行同步評(píng)估,EEGPT 在所有任務(wù)中的準(zhǔn)確率均超越現(xiàn)有專用模型,。
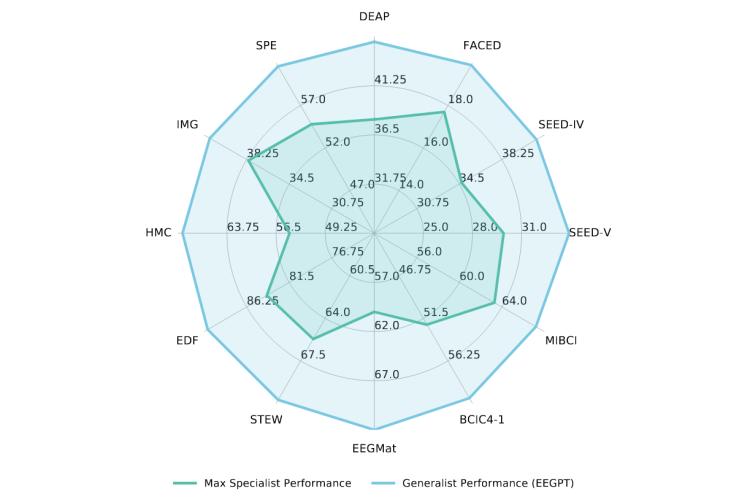
圖1
研究背景
EEG被視為大腦的 “語(yǔ)言”,,被廣泛應(yīng)用于情緒識(shí)別、運(yùn)動(dòng)想象分類等多個(gè)神經(jīng)科學(xué)研究領(lǐng)域,。然而,,當(dāng)前 EEG 研究存在諸多局限。
在數(shù)據(jù)層面,,不同的研究和數(shù)據(jù)采集使用了不同的系統(tǒng)和設(shè)備進(jìn)行數(shù)據(jù)采集,,使用的電極數(shù)量和組合也不盡相同,導(dǎo)致數(shù)據(jù)格式多樣,。當(dāng)前研究中常采用針對(duì)特定任務(wù)或數(shù)據(jù)集設(shè)計(jì)的數(shù)據(jù)格式和手工特征提取技術(shù),,通用性差,難以推廣到其他任務(wù)或數(shù)據(jù)集,。
在模型層面,,目前大多數(shù) EEG 研究在模型設(shè)計(jì)和訓(xùn)練上高度專業(yè)化,現(xiàn)有模型多針對(duì)特定任務(wù),、數(shù)據(jù)集或個(gè)體設(shè)計(jì),,缺乏通用性和跨任務(wù)能力。
在預(yù)訓(xùn)練與遷移學(xué)習(xí)層面,,當(dāng)前的研究中,,自監(jiān)督預(yù)訓(xùn)練主要采用掩碼自編碼器(MAE)技術(shù),難以捕捉 EEG 數(shù)據(jù)的時(shí)序依賴,。且 EEG 領(lǐng)域的遷移學(xué)習(xí)方法發(fā)展不足,,當(dāng)前預(yù)訓(xùn)練模型多只能在特定數(shù)據(jù)集微調(diào),難以實(shí)現(xiàn)跨任務(wù)的通用與協(xié)同,。
研究方法
1. 自回歸時(shí)間序列建模(Autoregressive Time Series Modeling)
這一階段的目的是開(kāi)發(fā)一個(gè)全面而詳細(xì)的自監(jiān)督學(xué)習(xí)范式,,能夠準(zhǔn)確、高效地捕獲EEG信號(hào)中的內(nèi)在時(shí)間變化,。
在數(shù)據(jù)處理方面,,本研究采用了電極建模策略(Electrode - wise Modeling Strategy)。S首先,,研究人員從多個(gè)來(lái)源收集 EEG 數(shù)據(jù),,每個(gè)樣本xi∈?Ei×T×C對(duì)應(yīng)一個(gè)包含Ei個(gè)電極的集合?i,具有在電極Ei,、T個(gè)時(shí)間間隔和C個(gè)采樣點(diǎn)三個(gè)維度上的信息,。然后,為了深入挖掘 每個(gè)電極所特有的信息,,引入了結(jié)構(gòu)化重組函數(shù)?(·)按電極分割每個(gè)樣本xi為x?i∈?T×C,,使來(lái)自不同數(shù)據(jù)源但具有相同電極的數(shù)據(jù)記錄分組在一起,具體而言:

其中De={x?i |e∈?i , i=1,2,··· ,N},。 最后為了在模型中區(qū)分不同的電極,,進(jìn)一步引入了可訓(xùn)練的電極詞匯表vE,在每個(gè)分組De中的所有元素都共享一個(gè)電極嵌入veE,,這個(gè)電極嵌入作為一種條件信息,,通過(guò)連接操作(用||表示)與分組De中的所有數(shù)據(jù)在序列維度上進(jìn)行合并,得到新的序列,,具體而言:
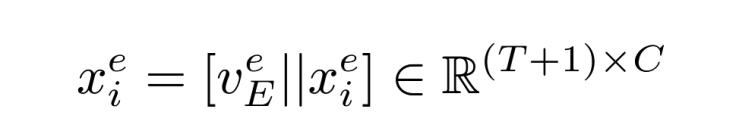
這使得來(lái)自各種不同源和電極的信號(hào)被轉(zhuǎn)換為高度統(tǒng)一且可擴(kuò)展的標(biāo)準(zhǔn)化格式,,包含T+1 個(gè)EEG “標(biāo)記”的數(shù)據(jù)x?i(連接前是T個(gè)標(biāo)記)成為后續(xù)自回歸重構(gòu)的基本處理單元。
數(shù)據(jù)被輸入到共享的電極時(shí)間編碼器( Electrode Temporal Encoder,,ETE )中進(jìn)行自回歸重建,。ETE 由多個(gè)相同結(jié)構(gòu)的層組成,每層有兩個(gè)子層:一是多頭因果注意力機(jī)制子層,,該子層的輸出經(jīng)過(guò)歸一化處理后,,再通過(guò)殘差連接與輸入相加,有助于信息有效傳遞和穩(wěn)定訓(xùn)練,。二是位置全連接前饋網(wǎng)絡(luò)子層,,采用 SwiGLU 激活函數(shù),為網(wǎng)絡(luò)引入非線性,,增強(qiáng)模型表達(dá)能力,,進(jìn)一步處理數(shù)據(jù)以提取更復(fù)雜的特征。ETE 的輸出通過(guò)一個(gè)簡(jiǎn)單多層感知機(jī)(MLP)轉(zhuǎn)換為下一個(gè)標(biāo)記的預(yù)測(cè),。這個(gè)預(yù)測(cè)過(guò)程是自回歸模型的核心,,它基于之前的輸入信號(hào)來(lái)預(yù)測(cè)下一個(gè)時(shí)刻的信號(hào)值,從而逐步構(gòu)建出整個(gè)時(shí)間序列的預(yù)測(cè)結(jié)果,。
2. 任務(wù)共享電極圖(Task-shared Electrode Graph)
這一階段,,提出了一個(gè)任務(wù)共享的電極圖(TEG)網(wǎng)絡(luò)。該網(wǎng)絡(luò)自適應(yīng)地激活各個(gè)電極之間的相互作用,,以同時(shí)支持多個(gè)任務(wù),。
首先進(jìn)行電極表征提取,對(duì)于多任務(wù)數(shù)據(jù)集中的每個(gè)樣本yj,,引入一個(gè)可學(xué)習(xí)的特殊標(biāo)記,,這個(gè)特殊標(biāo)記被廣播到所有電極并添加到時(shí)間序列末尾。這樣的操作使得特殊標(biāo)記能夠在自回歸模型的單向注意力機(jī)制的幫助下,,整合來(lái)自各個(gè)電極的局部信息,,合成更具全局代表性的表示,。經(jīng)過(guò)特殊標(biāo)記處理后的數(shù)據(jù)被輸入到先前訓(xùn)練好的電極時(shí)間編碼器(ETE)中,此時(shí) ETE 的參數(shù)不再更新,,僅作為特征提取的骨干網(wǎng)絡(luò),。每個(gè)樣本yj生成了捕獲了全面時(shí)間信息的電極表征zj。
然后構(gòu)建以預(yù)訓(xùn)練階段使用的電極為節(jié)點(diǎn)的全連通圖網(wǎng)絡(luò)G,,結(jié)點(diǎn)總數(shù)為|?(X)|, 涵蓋多任務(wù)數(shù)據(jù)集中幾乎所有可能使用到的電極,。當(dāng)zj被引入到網(wǎng)絡(luò)中時(shí),它所包含電極對(duì)應(yīng)G中的節(jié)點(diǎn)才會(huì)被激活,。激活更新后的圖G通過(guò)圖注意力機(jī)制促進(jìn)電極間空間信息的流動(dòng)和交互:
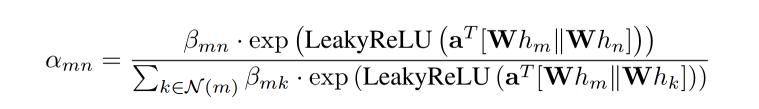
其中αmn為節(jié)點(diǎn)m和n間的注意力系數(shù),,W和α是可學(xué)習(xí)的映射權(quán)重,hm是節(jié)點(diǎn)m在圖中的表示,,N(m)表示節(jié)點(diǎn)m的鄰居,。對(duì)于每個(gè)電極表征zj,引入一個(gè)掩蔽系數(shù)β,,如果m和n都在其中,,則βmn等于1,否則為0,?;诘玫降淖⒁饬ο禂?shù),節(jié)點(diǎn)之間的交互關(guān)系如下:
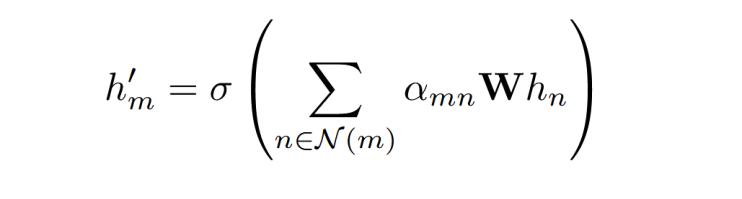
最終,,EEGPT的整體架構(gòu)如圖2所示:
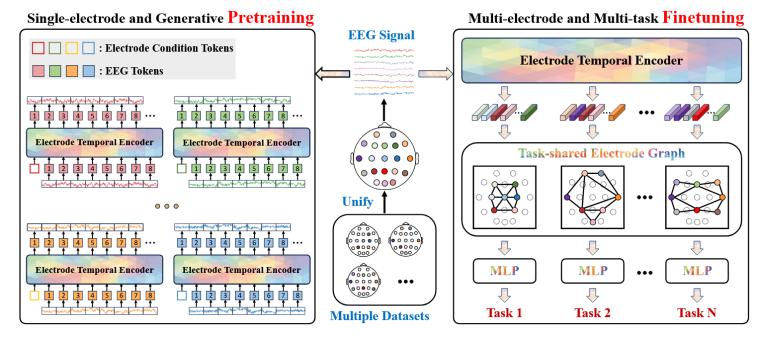
圖2
左側(cè):預(yù)訓(xùn)練目標(biāo)的目標(biāo)是進(jìn)行自回歸重建,,每個(gè)信號(hào)標(biāo)記通過(guò)電極時(shí)序編碼器(ETE )逐一預(yù)測(cè)下一個(gè)標(biāo)記。右側(cè):多任務(wù)中數(shù)據(jù)集的電極通過(guò)預(yù)訓(xùn)練的ETE進(jìn)行處理,,提取最終的電極表示,,然后將其輸入到任務(wù)共享電極圖(TEG )網(wǎng)絡(luò)中,以整合多個(gè)電極之間的空間信息,。ETE和TEG共同構(gòu)成了漸進(jìn)的時(shí)空解耦,。
實(shí)驗(yàn)設(shè)計(jì)
本研究開(kāi)發(fā)了EEGPT的4種架構(gòu)配置:EEGPT - Base、EEGPT - Large,、EEGPT - Huge和EEGPT - Giant,。為了更詳細(xì)地分析標(biāo)度律,請(qǐng)參見(jiàn)表1:
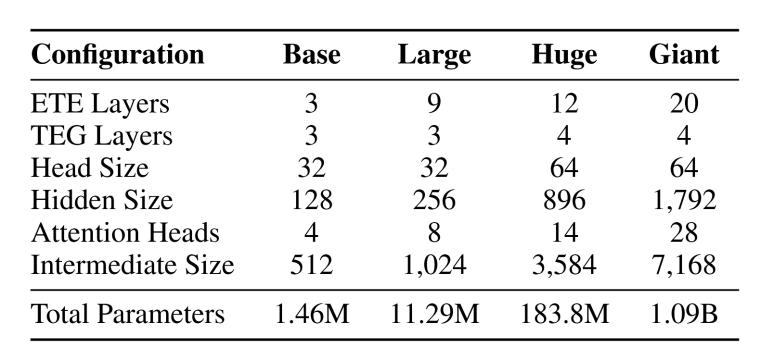
表1 EEGPT模型的配置
本研究選取的比較基準(zhǔn)模型分為兩類:第一類模型在各自的數(shù)據(jù)集上從頭開(kāi)始訓(xùn)練,,不需要任何預(yù)訓(xùn)練,;第二類在各自的數(shù)據(jù)集上使用繼承的預(yù)訓(xùn)練參數(shù)進(jìn)行微調(diào)。如表2所示,,作者在5個(gè)不同的任務(wù)(情感識(shí)別ER,、運(yùn)動(dòng)想象分類MI、腦力負(fù)荷檢測(cè)MW、睡眠分期SS,,跨模態(tài)任務(wù)CM)中使用12個(gè)數(shù)據(jù)集來(lái)評(píng)估EEGPT,。

表2 不同任務(wù)中使用到的數(shù)據(jù)集
實(shí)驗(yàn)采用了跨被試范式,將每個(gè)數(shù)據(jù)集按照8:1:1的比例劃分為訓(xùn)練集,、驗(yàn)證集和測(cè)試集,,并且確保這些劃分間沒(méi)有受試者的重疊。
結(jié)果分析
實(shí)驗(yàn)數(shù)據(jù)顯示,,EEGPT - Giant在ER、MI,、MW,、SS、CM任務(wù)上分別取得了5.07 %,、 6.05 %,、 8.50 %、 11.20 %,、 5.10 %的平均準(zhǔn)確率提升,,表明EEGPT雖然是一個(gè)通用模型,但始終優(yōu)于針對(duì)特定任務(wù)進(jìn)行微調(diào)的專用模型,。表3給出了12個(gè)數(shù)據(jù)集的性能比較:
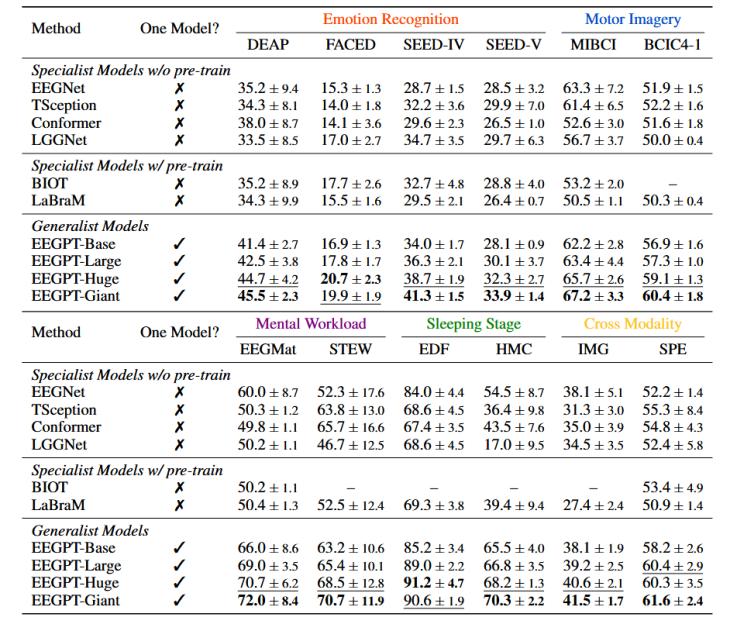
表3 12個(gè)數(shù)據(jù)集的性能比較
列" One Model ? "表示這些基準(zhǔn)的結(jié)果是否來(lái)自同一模型,。實(shí)驗(yàn)結(jié)果表明,隨著模型規(guī)模的擴(kuò)大,,性能存在明顯且一致的上升趨勢(shì),。有趣的是,經(jīng)過(guò)預(yù)訓(xùn)練的專用模型似乎比從零開(kāi)始訓(xùn)練的專業(yè)模型表現(xiàn)略差,,可能是由于預(yù)訓(xùn)練采用的數(shù)據(jù)和下游任務(wù)采用的數(shù)據(jù)存在較大領(lǐng)域差異,,妨礙了遷移學(xué)習(xí)的效果。
在消融實(shí)驗(yàn)部分,,得到結(jié)論:隨著模型參數(shù)增加,,對(duì)預(yù)訓(xùn)練數(shù)據(jù)的擬合更好,性能提升,;增加預(yù)訓(xùn)練數(shù)據(jù)量可提升性能,,但提升幅度逐漸減小,;聯(lián)合多任務(wù)訓(xùn)練優(yōu)于單獨(dú)訓(xùn)練,,共享節(jié)點(diǎn)(電極)提供了數(shù)據(jù)增強(qiáng);在未見(jiàn)過(guò)的 DREAMER 數(shù)據(jù)集上,,EEGPT 的表現(xiàn)出強(qiáng)可轉(zhuǎn)移性,,能有效聚類不同模式的信號(hào),具有較強(qiáng)的泛化能力,。
結(jié)論
本文提出了首個(gè)通用EEG基礎(chǔ)模型EEGPT,。通過(guò)引入電極建模策略,、開(kāi)發(fā)自回歸預(yù)訓(xùn)練方法以及實(shí)施帶有可學(xué)習(xí)電極圖網(wǎng)絡(luò)的多任務(wù)遷移學(xué)習(xí)范式,EEGPT統(tǒng)一了多樣的EEG數(shù)據(jù)集,,并捕捉了EEG信號(hào)中固有的順序和時(shí)間依賴關(guān)系,。模型在基準(zhǔn)測(cè)試中表現(xiàn)出色,展示了其多功能性和可擴(kuò)展性,。EEGPT將激發(fā)通用型EEG模型的進(jìn)一步研究和開(kāi)發(fā),。
附錄:近2年腦電信號(hào)大模型的相關(guān)論文對(duì)比
《Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI》:受大語(yǔ)言模型的啟發(fā),提出了一個(gè)名為大腦大模型(LaBraM)的統(tǒng)一 EEG 基礎(chǔ)模型 ,。模型通過(guò)分割 EEG 信號(hào)為通道補(bǔ)丁和向量量化神經(jīng)頻譜預(yù)測(cè),,在來(lái)自約 20 個(gè)數(shù)據(jù)集的大約 2500 小時(shí)的各種類型的 EEG 信號(hào)上進(jìn)行預(yù)訓(xùn)練,能處理不同電極配置和長(zhǎng)度的 EEG 數(shù)據(jù),。
《NEUROLM: A UNIVERSAL MULTI-TASK FOUNDATION MODEL FOR BRIDGING THE GAP BETWEEN LANGUAGE AND EEG SIGNALS》:提出多任務(wù)基礎(chǔ)模型NeuroLM ,,將 EEG 信號(hào)視為外語(yǔ),融入大語(yǔ)言模型框架,。通過(guò)文本對(duì)齊的神經(jīng)標(biāo)記器編碼EEG信號(hào),、多通道自回歸預(yù)訓(xùn)練和多任務(wù)指令調(diào)整,實(shí)現(xiàn)多任務(wù)學(xué)習(xí)和推理,。
《FoME: A Foundation Model for EEG using Adaptive Temporal-Lateral Attention Scaling》:提出 FoME (腦電圖基礎(chǔ)模型),,開(kāi)創(chuàng)性地采用時(shí)間 - 頻率融合嵌入技術(shù)和自適應(yīng)時(shí)間 - 橫向注意力縮放(ATLAS)機(jī)制處理EEG信號(hào),捕捉其復(fù)雜的時(shí)空動(dòng)態(tài),,適應(yīng)不同數(shù)據(jù)集,,促進(jìn)穩(wěn)健的多通道建模。
《Brant - X: A Unified Physiological Signal Alignment Framework》:提出 Brant - X 模型,,用于對(duì) EEG 與其他生理信號(hào)之間的相關(guān)性進(jìn)行建模,。利用 EEG 基礎(chǔ)模型,通過(guò)兩級(jí)對(duì)齊策略(補(bǔ)丁級(jí)和序列級(jí)),,有效對(duì)齊 EEG 與其他信號(hào)(EOG,、ECG、EMG)的語(yǔ)義,。
《EEGPT: Pretrained Transformer for Universal and Reliable Representation of EEG Signals》:提出用于通用 EEG 特征提取的EEGPT 模型,,設(shè)計(jì)了雙自監(jiān)督學(xué)習(xí)方法,結(jié)合時(shí)空表示對(duì)齊和掩碼重建,,提高特征質(zhì)量和模型收斂性,,為 EEG 信號(hào)處理提供有效的創(chuàng)新解決方案。
撰稿人:陳浩
審稿人:李景聰
載")
贊")







載")