 1034
1034
 0
0
 2024-11-27
2024-11-27
 2024-11-27
2024-11-27

本文的標題為《EEGPT: Pretrained Transformer for Universal and Reliable Representation of EEG Signals》,,作者團隊為哈爾濱工業(yè)大學計算機學院李海峰教授團隊,。該論文提交至NeurIPS 2024并錄用,,探討了通用且可靠的腦電圖(EEG)信號特征表示的預訓練Transformer模型EEGPT(EEG Pretrained Transformer)。
論文鏈接:https://openreview.net/forum?id=lvS2b8CjG5
EEGPT是一種新提出的,、具有1000萬參數的預訓練Transformer模型,旨在為EEG信號的特征提取提供通用而可靠的表示。本文提出用于通用 EEG 特征提取的EEGPT 模型,,設計了雙自監(jiān)督學習方法,,結合時空表示對齊和掩碼重建,提高特征質量和模型收斂性,,為 EEG 信號處理提供有效的創(chuàng)新解決方案,。與其他自監(jiān)督學習方法相比,EEGPT通過引入時空表示對齊技術,,構建了一個自監(jiān)督任務,,專注于高信噪比和豐富語義信息的EEG表示。這種方法有效緩解了從低信噪比的原始信號提取特征時常見的質量問題,。此外,,EEGPT的分層結構能夠分別處理空間和時間信息,從而降低計算復雜性,,提高對腦機接口(BCI)應用的靈活性和適應性,。實驗結果驗證了EEGPT在多種下游任務中的有效性和可擴展性,達到了最先進的性能,。
研究背景
EEG動態(tài)反映大腦功能狀態(tài),,廣泛應用于情緒識別、運動想象分類等多個領域,。目前EEG研究面臨數據層面的多樣性,、模型層面的專業(yè)化和預訓練及遷移學習方法的局限性,面臨的挑戰(zhàn)包括低信噪比,、高個體間變異性以及EEG信號的任務依賴性變化,。這些問題使得從EEG信號中提取穩(wěn)健的通用表示變得復雜,當前EEG研究多針對特定任務或數據集設計,,缺乏通用性和跨任務能力,。
自監(jiān)督學習在自然語言處理、計算機視覺和語音分析等領域展現了顯著優(yōu)勢,,許多最先進的模型通過自監(jiān)督學習在大數據集上進行預訓練,,并針對特定應用進行微調,從而有效降低了對大量標記數據的需求,。盡管近年來在EEG分析中應用自監(jiān)督學習技術取得了良好效果,,但現有的掩碼自編碼器技術難以捕捉EEG數據的時序依賴,限制了遷移學習的效果,,尤其是在處理低SNR信號時的特征提取質量,。
研究方法
EEGPT提出了一種基于時空一致性的雙自監(jiān)督EEG通用表示方法,主要包括以下幾個關鍵技術要點:
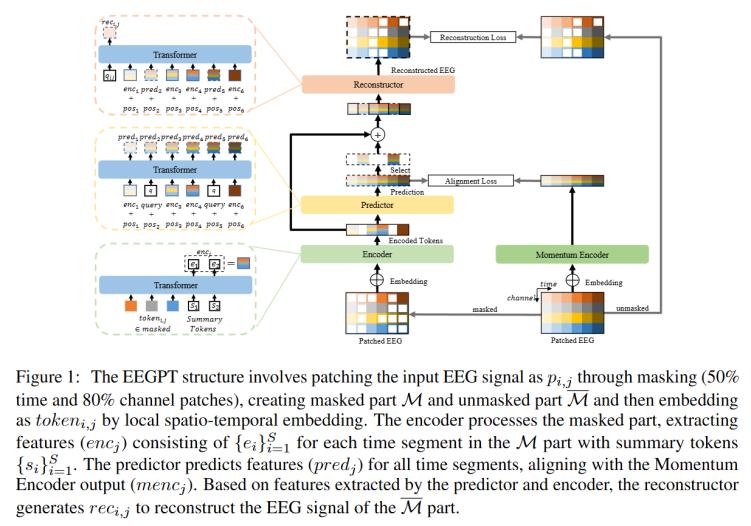
EEGPT的結構如圖1所示。模型將EEG信號(M個通道和T個時間點)分為若干個patch,,并通過局部時空嵌入將每個patch作為token嵌入,,然后分別分為有無掩碼的patch使用時空表示對齊和掩碼重建。最后,,線性探測方法用于應用在下游任務中,。
1. 時空表示對齊
掩碼自動編碼器是一種去噪自動編碼器來學習特征,通過將被隨機patch掩碼遮擋的信號輸入到編碼器中,,解碼器預測掩碼patch的原始嵌入,,如公式1所示:
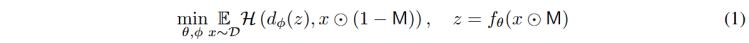
其中⊙表示逐元素乘積,是掩碼塊,,and 分別是編碼器和解碼器,,是學習表示,是相似性度量,。通過最小化損失函數,,模型學習輸入信號的最佳表示。,,在類BERT模型中編碼器和解碼器沒有分割,沒有明確表示,,本文在EEGPT模型中添加了時空表示對齊分支來顯式表達,,這也就是雙自監(jiān)督方法,能夠鼓勵編碼表示具有更大程度的語義,,提高編碼質量和泛化能力,,如公式2所示:

時空表示對齊方法將預測特征和動量編碼器的輸出對齊,增強了編碼器提取魯棒特征的能力,確保編碼器的輸出包含高質量的全局特征,。本文采用編碼器和預測器來解耦空間和時間特征,,能夠降低計算復雜度。
編碼器
編碼器整合了來自掩碼patch的空間信息,,公式3描述了編碼器(ENC)如何處理時間j處的所有掩碼,,并產生相應的輸出特征。
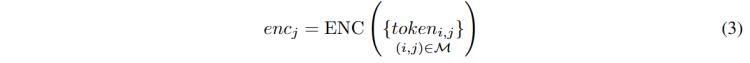
預測器
如公式4所示,,預測器(PRED)利用來自編碼器掩碼部分的特征,,結合時間位置信息,來預測完整的編碼特征,。本文采用了旋轉位置嵌入方法來生成,,引入相對位置和時間信息。為了生成屬于M的預測特征,,使用可學習的向量查詢作為查詢標記,,在自監(jiān)督訓練中鼓勵編碼器提取token之間相關性信息。
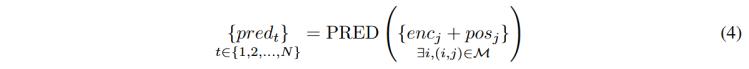
動量編碼器
動量編碼器與編碼器的結構相同,,每次訓練迭代后,,編碼器的參數以的系數累積到動量編碼器中,如公式5所示,。

并使用基于均方誤差(MSE)的對齊損失來實現時空表示對齊,,LN表示層歸一化,有助于減輕極值和協(xié)變量偏移的影響,,如公式6所示,。
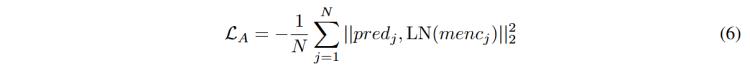
2. 掩碼重構
基于掩碼的重建方法將重建器生成的重建patch與原始的patch進行對齊。
重建器
如公式7所示,,重建器(REC)利用編碼器編碼的M部分的特征和預測器預測的M部分的特征,,以及時間位置,生成重建的patch ,。
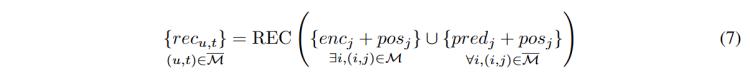
掩碼重建時使用基于均方誤差的重建損失來實現的,,如公式8所示。

最后通過將和相加構建完整的預訓練損失,。
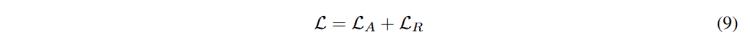
3. 局部時空嵌入
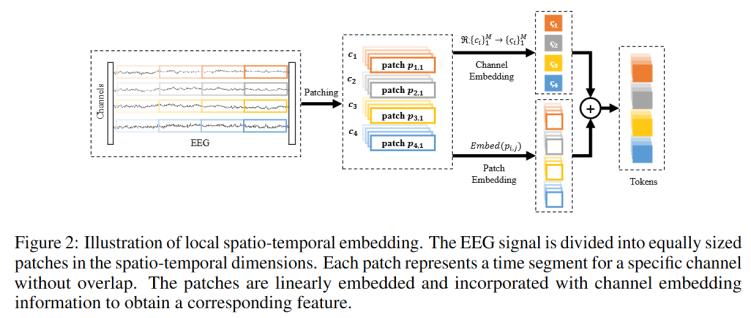
局部時空嵌入方法首先在時空維度上對EEG信號進行分塊和嵌入編碼,,然后將其輸入編碼器,如圖2所示,。首先對EEG信號進行分割,,在時空維度上劃分為大小相等的塊,如公式10所示,。
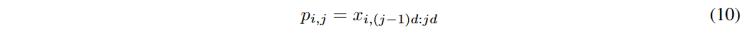
其中d表示patch的時間長度,, 是時間patch的數量,。此后結合嵌入信息線性地嵌入patch,構造一個集合其中包含所有可學習的通道嵌入向量和從通道名稱到通道嵌入向量,,使得模型能夠適應多個數據集,,提高通道適應性。最后得到的token由patch線性嵌入后得到,,如公式11所示,。

基于自監(jiān)督學習任務,提取的patch特征是互相可預測的,,可以忽略較小尺度的噪聲信息,。該方法旨在提取跨越更大尺度的宏觀特征,這些特征更容易識別且認為是有意義的特征,。
4. 線性探測方法
在下游任務中,,使用預訓練的編碼器并連接額外的模塊來進行分類。如圖3所示,,該方法凍結預訓練模型中的參數,,僅更改附加線性模塊中的參數。該模塊包括用于對齊EEG和模型之間通道的自適應空間濾波器(1*1卷積),,以及將特征映射到網絡最后一層的輸出logits的線性層,,連接多分類頭進行多分類任務。

實驗設計
本文進行了多項實驗,,以評估EEGPT在不同EEG任務中的表現,。實驗數據集包括多種EEG信號來源,如PhysioMI,、HGD和M3CV等,,每個數據集涵蓋了不同的任務和主題。實驗評估了EEGPT在運動想象分類,、事件相關電位檢測和睡眠階段檢測等任務上的性能,。
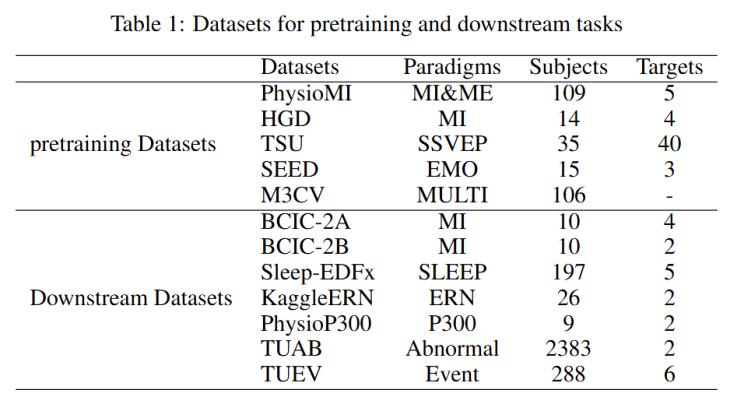
1. 數據集
預訓練數據集包括:
下游任務數據集包括:
2. 實驗設置
模型設置
EEGPT模型的實現采用了vision transformer(VIT)結構,設置了S個可學習的摘要標記(類似于分類標簽[CLS]標記),,使用58個電極,,如圖4所示。采樣率為256Hz,,輸入信號的時間長度為1024,。每個patch的時間長度為64,對應250ms的時間窗口,。訓練時對50%的時間維度和80%的通道維度進行掩碼遮掩,。
預訓練策略
對于每個預訓練數據集隨機抽取10%的樣本作為驗證集。如表6所示,,訓練了8個不同編碼長度,、模型層數、摘要標記的變體,。訓練過程中,,使用AdamW優(yōu)化器,采用OneCycle學習率策略(初始學習率為2.5e-4,,最大學習率為5e-4,,最小學習率為3.13e-5),訓練200輪次,,在8張Nvidia 3090 GPU上進行64和16位混合精度訓練,。
評估策略
對于TUAB和TUEV數據集的分割,遵循于BIOT模型的策略,。其余數據集使用留一法(Leave-One-Subject-Out, LOSO)進行驗證,,其中Sleep-EDFx遵循6:2:2的分割比例并使用十折交叉驗證,KaggleERN使用四折交叉驗證,,并對下游任務使用線性探測方法,。例如在睡眠階段檢測任務中,,使用4層transformer編碼器模型作為分類器,每0.25s輸出一次模型結果,,以處理30s的長任務,。為保證實驗可靠性,將每個實驗重復三次并計算標準偏差,。
基線指標
對于TUAB和TUEV數據集,,使用來自BIOT模型的相同基線。在其它任務中,,使用預訓練的BENDR,、BIOT和LaBraM作為基線。以下指標用于比較:平衡準確率(Balanced Accuracy, BAC),、AUC-ROC曲線下面積(AUROC),、加權F1、科恩卡帕系數(Cohen’s Kappa),,其中AUROC用于二分類任務,,加權F1僅用于多分類任務。
結果分析
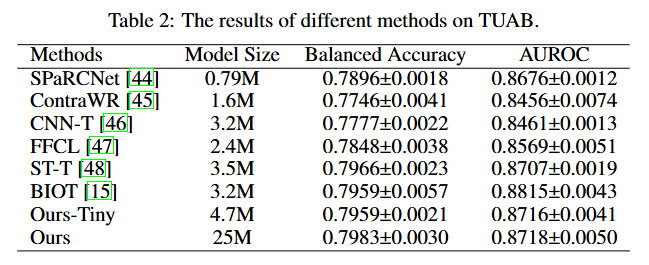
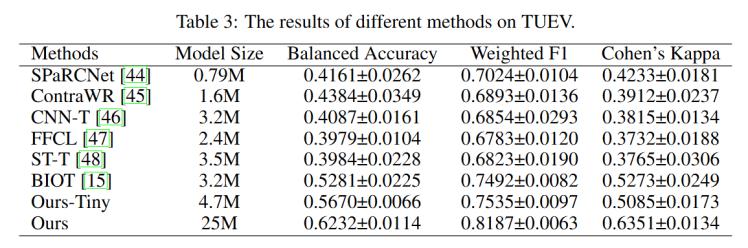
實驗結果表明,,EEGPT在多個數據集上的表現均優(yōu)于現有基線模型,。結果如表2、表3所示,,在TUAB數據集上,,EEGPT的性能與BIOT模型相當,在TUEV數據集上,,EEGPT比BIOT模型提高了9.5%的平衡準確率,,加權F1提高了6.9%。
同時也在其他下游任務數據集上與BENDR,、LaBraM進行了比較實驗,,結果如表4所示,EEGPT的性能也顯著優(yōu)于其他模型,,證明了其在多任務EEG信號處理中的有效性,。在所有任務上,EEGPT模型與BENDR,、BIOT和LaBraM相比都取得了具有競爭力的結果,。這表明EEGPT在時空維度上學習了一致的表征特征,使得該模型能夠更廣泛地應用于多種范式任務,,實現更好的分類性能,。

結論
EEGPT通過創(chuàng)新的雙自監(jiān)督學習方法和時空表示對齊技術,顯著提升了EEG信號的特征提取能力。該模型是具有1000多萬個參數的自監(jiān)督EEG預訓練Transformer模型,,能夠用于學習通用的EEG特征,,通過采用雙自監(jiān)督方法進行預訓練(包括時空表示對齊和基于掩碼的重建)。時空表示對齊將是否使用掩碼的特征patch進行對齊,,提高了EEG表征的質量,。基于掩碼的重建是利用EEG信號所表現出的空間和時間一致性,,在兩個維度上提取互補特征,通過層次結構首先從短期EEG信號中提取穩(wěn)定的空間表示,,再捕獲長期EEG信號之間的時間相關性,。實驗結果驗證了其在運動想象、睡眠階段檢測和ERP類型分類等多種下游任務中的優(yōu)越表現,,展示了其廣泛的應用前景和潛力,,為生物信號處理和人工智能應用提供了新的解決方案。未來的研究可以進一步探索EEGPT在更復雜的腦機接口和神經科學研究中的潛在應用,。
附錄:近2年腦電信號大模型的相關論文對比
(需要的話可以在下方對應論文,,加上我們的往期推文鏈接)
《Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI》:受大語言模型的啟發(fā),提出了一個名為大腦大模型(LaBraM)的統(tǒng)一 EEG 基礎模型,,旨在從大量EEG數據中學習通用特征表示,。模型通過分割 EEG 信號為通道補丁和向量量化神經頻譜預測,能夠有效處理不同電極配置和信號長度,。在來自約 20 個數據集的大約 2500 小時的各種類型的 EEG 信號上進行預訓練,,能處理不同電極配置和長度的 EEG 數據。
《NEUROLM: A UNIVERSAL MULTI-TASK FOUNDATION MODEL FOR BRIDGING THE GAP BETWEEN LANGUAGE AND EEG SIGNALS》:提出多任務基礎模型NeuroLM,,旨在整合語言和EEG信號,,以提高情感識別和認知狀態(tài)分析的準確性,將 EEG 信號視為外語,,融入大語言模型框架,。通過文本對齊的神經標記器編碼EEG信號、多通道自回歸預訓練和多任務指令調整,,實現多任務學習和推理,。
《FoME: A Foundation Model for EEG using Adaptive Temporal-Lateral Attention Scaling》:提出 FoME (腦電圖基礎模型),開創(chuàng)性地采用時間-頻率融合嵌入技術和自適應時間-橫向注意力縮放(ATLAS)機制處理EEG信號,,捕捉其復雜的時空動態(tài),,適應不同數據集,并結合CNN和Transformer增強了對局部和全局特征的學習能力,,促進穩(wěn)健的多通道建模,。
《Brant - X: A Unified Physiological Signal Alignment Framework》:提出Brant - X模型,用于對 EEG 與其他生理信號之間的相關性進行建模,,解決了多種生理信號間對齊的問題,。利用 EEG 基礎模型,,通過兩級對齊策略(補丁級和序列級)分別處理局部和整體特征,并引入特征提取和對齊算法,,有效對齊 EEG 與其他信號(EOG,、ECG、EMG)的語義,,以及適應多任務學習的方法同時處理多個生理信號任務以提高性能,。
《EEGPT: Pretrained Transformer for Universal and Reliable Representation of EEG Signals》:提出用于通用 EEG 特征提取的EEGPT 模型,設計了雙自監(jiān)督學習方法,,結合時空表示對齊和掩碼重建,,提高特征質量和模型收斂性,為 EEG 信號處理提供有效的創(chuàng)新解決方案,。
《EEGPT: Unleashing the Potential of EEG Generalist Foundation Model by Autoregressive Pre-training》:提出自回歸EEG 預訓練模型,,通過引入電極建模策略、開發(fā)自回歸預訓練方法以及實施帶有可學習電極圖網絡的多任務遷移學習范式,,捕捉了EEG信號中固有的順序和時間依賴關系,。
相關鏈接
論文鏈接:https://openreview.net/forum?id=lvS2b8CjG5
PPT匯報鏈接:
https://nips.cc/media/neurips-2024/Slides/93793.pdf
撰稿人:陳宗楠
審稿人:潘家輝








