 653
653
 0
0
 2024-11-29
2024-11-29
 2024-11-29
2024-11-29

該論文發(fā)表于 IEEE Transactions on Image Processing 2024(CCF A類),,題目為《SelfGCN: Graph Convolution Network with Self-Attention for Skeleton-Based Action Recognition》,。
合肥大學(xué)的吳志澤副教授為論文的第一作者,合肥大學(xué)的湯衛(wèi)思教授為本文通訊作者。
論文鏈接:
https://ieeexplore.ieee.org/document/10618962
當(dāng)前傳統(tǒng)的圖卷積網(wǎng)絡(luò)(GCNS)在基于骨架的動作識別領(lǐng)域取得了顯著的成果,,但它們主要關(guān)注局部節(jié)點(diǎn)依賴關(guān)系,難以捕捉長距離的節(jié)點(diǎn)關(guān)系,。此外,,目前的現(xiàn)有方法通常對所有幀使用相同的骨架拓?fù)洌拗屏藢r空特征的建模能力,。
為了解決這些問題,,本文提出了一種新的圖卷積神經(jīng)網(wǎng)絡(luò)SelfGCN,主要通過兩個核心模塊克服上述局限性,。圖卷積與自注意力混合特征模塊(MFSG),,并行引入圖卷積和自注意力機(jī)制,分別負(fù)責(zé)捕獲局部和全局的節(jié)點(diǎn)依賴,,通過雙向交互機(jī)制,,在通道維度和空間維度進(jìn)行特征互補(bǔ)。時間特定空間自注意力模塊(TSSA),,基于自注意力機(jī)制建模骨架序列中每一幀節(jié)點(diǎn)的空間關(guān)系,,提取每一幀的獨(dú)特空間特征,彌補(bǔ)統(tǒng)一拓?fù)浣Y(jié)構(gòu)的不足,。SelfGCN在NTU RGB+D,,NTU RGB+D120和 Northwestern-UCLA三個主流數(shù)據(jù)集上均達(dá)到或超過了現(xiàn)有最新方法的精度。
人類動作識別作為計(jì)算機(jī)視覺領(lǐng)域的一個重要任務(wù),,基于骨架的動作識別逐漸成為一種非常有效的解決方法,,相較于傳統(tǒng)的RGB視頻數(shù)據(jù),骨架數(shù)據(jù)減少了環(huán)境因素的干擾,,同時能夠更加高效地表示人體運(yùn)動的結(jié)構(gòu)化變化,。
近年來圖卷積網(wǎng)絡(luò)(GCN)在骨架動作識別領(lǐng)域取得了顯著進(jìn)展,相較于循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)或卷積神經(jīng)網(wǎng)絡(luò)(CNN),,圖卷積網(wǎng)絡(luò)可以更加充分地利用關(guān)節(jié)之間的連接信息,。但是現(xiàn)有的GCN方法通常使用預(yù)定義的骨架拓?fù)?,無法有效處理跨越長距離的節(jié)點(diǎn)關(guān)系,同時現(xiàn)有方法大多采用統(tǒng)一的拓?fù)浣Y(jié)構(gòu)對所有時間幀進(jìn)行建模,。因此,,如何克服上述問題成為了待解決的研究需求。
本文提出了一種新的圖卷積網(wǎng)絡(luò)架構(gòu)SelfGCN,,它結(jié)合了圖卷積和自注意力機(jī)制,,旨在解決現(xiàn)有基于GCN的骨架識別方法中的一些問題,主要包含混合特征,、時間特定空間自注意力,、多尺度時間卷積三個模塊,三個模塊相互串聯(lián),、互補(bǔ)協(xié)作,,共同優(yōu)化骨架序列的時空特征表示,提升動作識別的準(zhǔn)確性,。
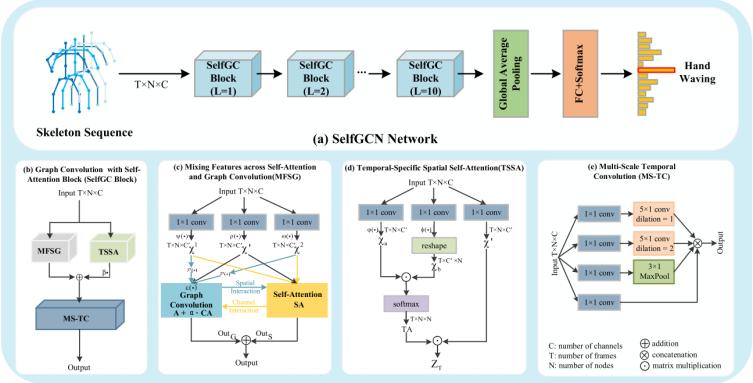
圖1 SelfGCN網(wǎng)絡(luò)的整體架構(gòu) (a) SelfGCN網(wǎng)絡(luò)的流程 (b) SelfGC 塊的組成與結(jié)構(gòu) (c) 圖卷積與自注意力混合特征(MFSG)模塊 (d) 時間特定空間自注意力(TSSA)模塊 (e) 多尺度時間卷積(MS-TC)模塊的結(jié)構(gòu)
圖卷積模塊:SelfGCN采用類似于CTR-GCN的方法,,同時學(xué)習(xí)共享拓?fù)浜屯ǖ捞囟ǖ南嚓P(guān)性。通過相關(guān)性建模函數(shù)
M(⋅)
來模擬兩個頂點(diǎn)之間的拓?fù)潢P(guān)系,,可以表示為: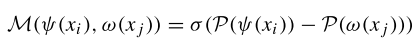
其中 σ(⋅) 表示激活函數(shù),,P(⋅) 是平均池化操作,P(ψ(xi)) 和 P(ω(xj)) 分別表示經(jīng)過線性變換和池化操作后的兩個節(jié)點(diǎn)的特征,。之后再使用線性變化 ?(⋅) 增加通道維度,,獲取通道特定的相關(guān)性 CA :
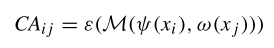
CAij 反映了頂點(diǎn) vi 和 vj 之間的通道特定拓?fù)潢P(guān)系。將通道的特定相關(guān)性 CA 與領(lǐng)接矩陣形式的共享拓?fù)?A 相結(jié)合,,得到特定通道的拓?fù)潢P(guān)系 R :
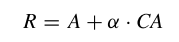
其中 α 是一個可訓(xùn)練的標(biāo)量參數(shù),,用于調(diào)整通道拓?fù)涞母倪M(jìn)強(qiáng)度,。最后通過得到的通道特定拓?fù)銻和高級特征X′,,以通道方式對空間特征進(jìn)行提取:
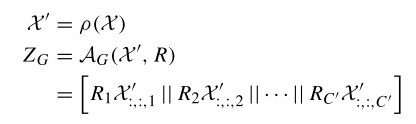
其中,,ρ(⋅) 是用于將輸入特征轉(zhuǎn)換為高級特征的線性變換函數(shù),,AG 是聚合函數(shù),Ri 是通道的拓?fù)浣Y(jié)構(gòu),,X':,:,i 是通道的變換輸入特征,,? 表示連接操作。通過這種方式,,SelfGCN 可以有效地從不同通道聚合關(guān)節(jié)特征,,同時捕捉局部和全局的空間特征。
自注意力模塊:為了彌補(bǔ)圖卷積在建模長距離的關(guān)節(jié)關(guān)系上的缺陷,,引入具有全局感受野的自注意力機(jī)制用于捕獲關(guān)節(jié)間的全局依賴關(guān)系,,補(bǔ)充圖卷積處理的局部關(guān)系,。本文使用圖卷積模塊經(jīng)過線性變化的特征作為 query 和 key ,分別表示為 X1=ψ(X) 和 X2=ω(X) ,。
同時為了與CTR-GCN的通道拓?fù)浣Y(jié)構(gòu)保持一致,,本文為每個通道獨(dú)立地使用自注意力機(jī)制來建模通道內(nèi)關(guān)節(jié)的全局關(guān)系。對于第 i 個通道,,自注意力權(quán)重 SAi 通過以下公式計(jì)算:
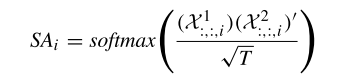
其中 SAi 表示第 i 個通道內(nèi)關(guān)節(jié)間的全局關(guān)系,,Xj:,:,i 表示變換后的輸入特征的第 i 個通道特征,T 是時間幀的數(shù)量,。最后將關(guān)系矩陣 SAi 與相應(yīng)通道的輸入特征相乘,,即可以得到每個通道的全局空間特征。通過自注意力模塊,,SelfGCN能夠有效地捕捉關(guān)節(jié)間的全局依賴關(guān)系,。
混合特征模塊:混合特征模塊將圖卷積和自注意力并行結(jié)合,以擴(kuò)展空間感受野,,這種設(shè)計(jì)允許同時對輸入特征進(jìn)行圖卷積和自注意力建模,,增強(qiáng)了模型對空間特征的捕捉能力。在圖卷積分支和自注意力分支之間實(shí)現(xiàn)了雙向交互,,以實(shí)現(xiàn)通道和空間維度之間的信息互補(bǔ),。
使用自注意力模塊的空間建模結(jié)果進(jìn)行通道注意力計(jì)算,包括平均池化,、兩個連續(xù)的 1x1 卷積,,以及后續(xù)的 GELU 激活函數(shù),最后通過 sigmoid 函數(shù)生成通道注意力結(jié)果 Cf :
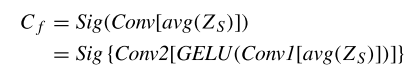
將通道注意力結(jié)果應(yīng)用于通道特定的拓?fù)潢P(guān)系 R,,使用 Rf 和變換后的輸入特征 X′ 聚合每個通道的特征,,并將它們連接起來作為圖卷積模塊的輸出 OutG 。對圖卷積模塊的建模結(jié)果應(yīng)用空間注意力,,包括池化操作,、 1x1 卷積和 sigmoid 函數(shù),再將空間注意力應(yīng)用于自注意力模塊得到建模結(jié)果 OutS :
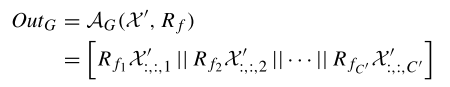
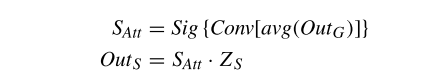
最后,,將兩個模塊的建模結(jié)果 OutG 和 OutS 相加,,即可以得到MFSG模塊的輸出。
TSSA模塊旨在解決傳統(tǒng)的圖卷積網(wǎng)絡(luò)在處理骨架特征序列時,,對所有幀使用相同的拓?fù)浣Y(jié)構(gòu),,忽略了每幀內(nèi)時序特定的空間關(guān)系。TSSA模塊通過捕捉每幀內(nèi)關(guān)節(jié)之間的獨(dú)特空間關(guān)系,,而不是對所有幀使用統(tǒng)一的拓?fù)浣Y(jié)構(gòu),。
首先對輸入的骨架特征 X 通過兩個線性變化 ?(⋅) 和 φ(⋅) 將其轉(zhuǎn)換為高級特征:
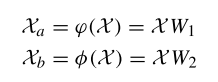
其中 Xa 和 Xb 分別表示經(jīng)過兩個不同線性變化后的特征,W1 和 W2 則是權(quán)重矩陣。然后再通過點(diǎn)積計(jì)算單幀內(nèi)每個節(jié)點(diǎn)之間的相關(guān)性,,得到一個關(guān)系矩陣 TA ,,計(jì)算公式如下:
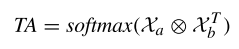
最后在每個通道中計(jì)算輸入矩陣和關(guān)系矩陣之間的點(diǎn)積,再沿著時間維度 T 連接每幀的空間建模結(jié)果,,最后可以獲得最終的時間特定空間建模結(jié)果 ZT :
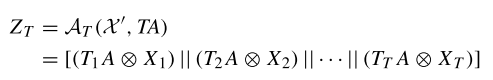
SelfGCN網(wǎng)絡(luò)通過結(jié)合MFSG模塊和TSSA模塊以及MS-TC模塊,,形成了具有自注意力的圖卷積網(wǎng)絡(luò)塊(SelfGC block)。這種網(wǎng)絡(luò)塊被堆疊L層,,以構(gòu)建基于骨架的人體動作識別網(wǎng)絡(luò),。TSSA模塊的輸出特征乘以一個可學(xué)習(xí)的系數(shù) β ,其中 β 用于調(diào)整時序特定空間特征的重要性,,然后加到MFSG模塊的輸出特征上:
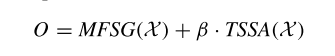
經(jīng)過L層的空間和時序建模后,,最終的輸出特征通過全局平均池化層和全連接層,以獲得動作分類的分?jǐn)?shù),。
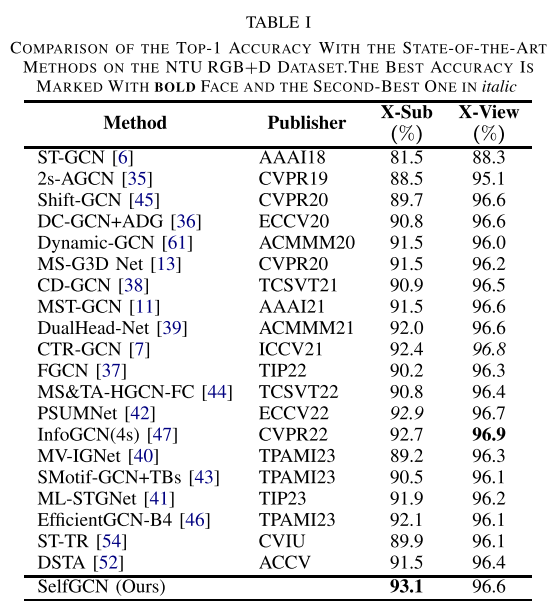
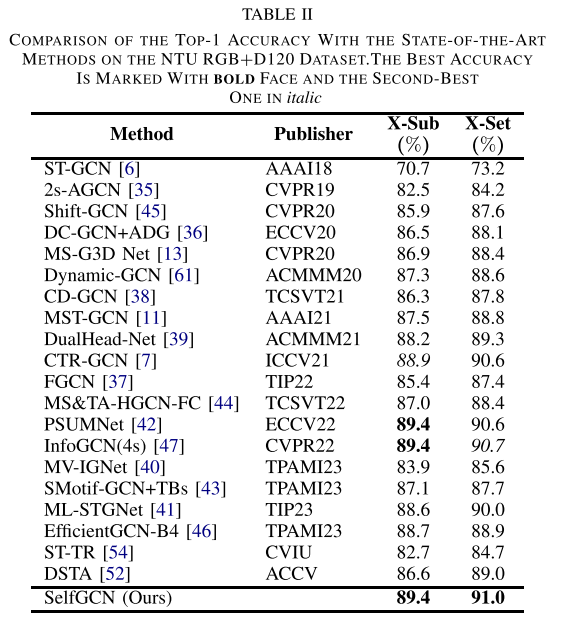
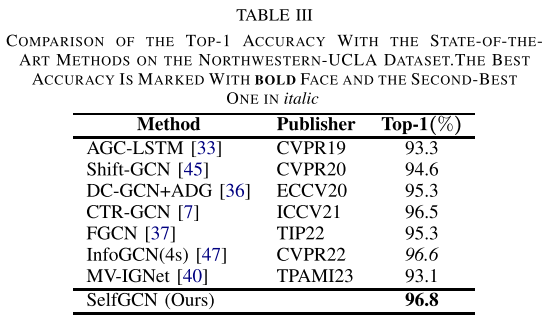
作者主要將SelfGCN在NTU RGB+D,、NTU RGB+D120和Northwestern-UCLA三個主流的基準(zhǔn)數(shù)據(jù)集上進(jìn)行了評估。如表1,、表2,、表3所示,在NTU RGB+D數(shù)據(jù)集的X-Sub標(biāo)準(zhǔn)上達(dá)到了93.1%的Top-1準(zhǔn)確率,,是目前最好的結(jié)果,。在NTU RGB+D120數(shù)據(jù)集的X-Sub標(biāo)準(zhǔn)上與PSUMNet和InfoGCN(4s)并列第一,而在X-Set標(biāo)準(zhǔn)上,,SelfGCN以91%的Top-1準(zhǔn)確率單獨(dú)排名第一,。在Northwestern-UCLA數(shù)據(jù)集上,SelfGCN達(dá)到了96.8%的Top-1準(zhǔn)確率,,超過了排名第二的InfoGCN(96.6%),。
此外,通過圖2中展示的在基線模型中加入TSSA模塊和MFSG模塊之后混淆矩陣的變化,,也可以直觀地看到TSSA和MFSG模塊對模型性能的影響,,在減少特定類型錯誤和提高特定動作識別準(zhǔn)確度方面提升較為明顯。
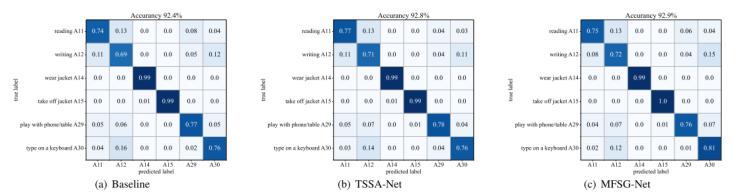
圖2 混淆矩陣對比 (a) 基線模型 (b) 加入TSSA模塊后的模型 (c) 使用MFSG模塊作為空間建模方法的模型
本文提出了SelfGCN,,一種結(jié)合圖卷積和自注意力機(jī)制的骨架動作識別模型,。通過引入混合特征模塊(MFSG)和時間特定空間自注意力模塊(TSSA),,SelfGCN 能同時建模局部和全局依賴,,并通過多尺度時間卷積(MS-TC)增強(qiáng)時序特征學(xué)習(xí)。實(shí)驗(yàn)結(jié)果表明,,SelfGCN 在多個骨架數(shù)據(jù)集上優(yōu)于現(xiàn)有方法,,展示了其強(qiáng)大的性能和可擴(kuò)展性。該模型為骨架動作識別領(lǐng)域提供了新的思路,,并推動了圖卷積與自注意力機(jī)制的結(jié)合應(yīng)用,。
撰稿人:徐煜濤
審稿人:周成菊
載")
贊")






載")