 159
159
 0
0
 2024-12-18
2024-12-18
 2024-12-18
2024-12-18

該論文發(fā)表于Applied Soft Computing(中科院1區(qū),IF=7.2),,題目為《A gradual self distillation network with adaptive channel attention for facial Expression recognition》,。
電子科技大學(xué)計算機(jī)學(xué)院的張新為此文第一作者,電子科技大學(xué)計算機(jī)學(xué)院的殷昱煜教授為通訊作者,。
論文鏈接:https://www.sciencedirect.com/science/article/pii/S1568494624005362
面部表情識別(Facial Expression Recognition, FER)在安全、醫(yī)療和智能交互等領(lǐng)域有廣泛應(yīng)用,,但現(xiàn)有方法在應(yīng)對表情的多樣性,、數(shù)據(jù)質(zhì)量問題以及實時應(yīng)用的計算效率方面存在挑戰(zhàn)。傳統(tǒng)知識蒸餾需要教師網(wǎng)絡(luò),,訓(xùn)練復(fù)雜,,而現(xiàn)有自蒸餾方法在淺層特征學(xué)習(xí)中缺乏多樣性,限制了模型性能,。本文提出了一種漸進(jìn)式自蒸餾網(wǎng)絡(luò)(GSDNet)與自適應(yīng)通道注意機(jī)制(ACAM)結(jié)合的新方法,。GSDNet通過逐層知識蒸餾增強(qiáng)淺層特征學(xué)習(xí)的多樣性,ACAM動態(tài)優(yōu)化特征通道權(quán)重,。該方法在RAF-DB,、FERPlus和Affect-Net等數(shù)據(jù)集上實現(xiàn)了精度和效率的提升,為實際應(yīng)用提供了一種輕量化解決方案,。
研究背景
面部表情識別在許多領(lǐng)域具有重要意義,,包括安全監(jiān)控、醫(yī)療健康,、數(shù)字娛樂和人機(jī)交互等,。它通過捕捉面部表情變化來分析個體情緒狀態(tài),支持檢測異常行為,、潛在威脅和情緒動態(tài),。然而,現(xiàn)有FER技術(shù)仍然面臨許多挑戰(zhàn),。傳統(tǒng)方法主要依賴手工特征,,這種方法難以有效區(qū)分高度相似的表情類別;基于深度學(xué)習(xí)的現(xiàn)代方法雖然改進(jìn)了性能,,但固定的特征標(biāo)注區(qū)域和對計算資源的高需求限制了其在實際場景中的應(yīng)用,。數(shù)據(jù)集中的問題進(jìn)一步加劇了FER的困難。例如,,常見的數(shù)據(jù)集受到姿態(tài)變化,、面部遮擋等影響,標(biāo)注區(qū)域與實際關(guān)鍵區(qū)域可能存在錯位,,導(dǎo)致分類效果下降,。一些方法嘗試使用注意力機(jī)制捕捉重要區(qū)域,盡管能提升性能,,但顯著增加了計算復(fù)雜度,,使得在實時安全場景中難以部署。因此,,如何設(shè)計高效且輕量化的FER模型,,成為當(dāng)前研究的關(guān)鍵課題,。知識蒸餾技術(shù)被提出以解決部分計算復(fù)雜性問題,通過學(xué)生網(wǎng)絡(luò)學(xué)習(xí)經(jīng)過優(yōu)化的教師網(wǎng)絡(luò)的知識來實現(xiàn)模型壓縮,。然而,,傳統(tǒng)知識蒸餾需要訓(xùn)練一個獨立的教師網(wǎng)絡(luò),過程復(fù)雜且耗時,。而自蒸餾則通過網(wǎng)絡(luò)自身的深層模塊作為教師,,向淺層模塊傳遞知識,這種方法更加高效,,但仍存在學(xué)生模塊學(xué)習(xí)的特征單一化問題,。此外,F(xiàn)ER技術(shù)在實際應(yīng)用中還需應(yīng)對三大挑戰(zhàn):個體和文化差異導(dǎo)致的表情變化多樣性,;低質(zhì)量圖像,、遮擋和標(biāo)注主觀性引起的不確定性;深度學(xué)習(xí)模型的高復(fù)雜度限制其在資源有限設(shè)備中的應(yīng)用,。
研究方法
文章提出了一種基于新穎的漸進(jìn)式自蒸餾和即插即用的自適應(yīng)通道注意機(jī)制的輕量級且有效的 FER 網(wǎng)絡(luò),。該模型具有強(qiáng)大的特征學(xué)習(xí)能力,在FER任務(wù)上取得了優(yōu)異的性能,,是探索和研究自蒸餾對于 FER 重要性的首次嘗試,。下面是網(wǎng)絡(luò)的總體架構(gòu)。
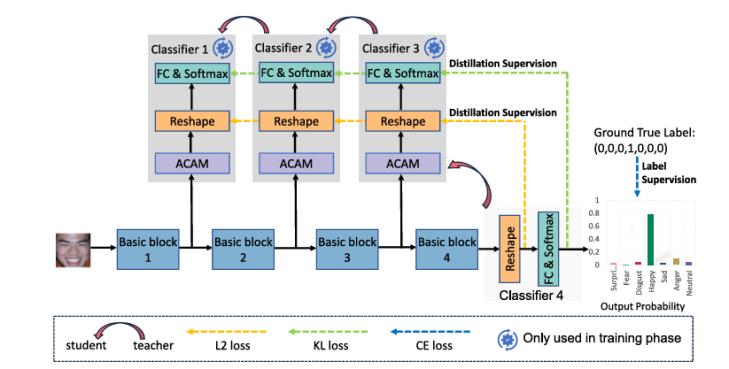
圖1 GSDNet的總體架構(gòu)
漸進(jìn)式自蒸餾策略
漸進(jìn)式自蒸餾策略是該論文的核心創(chuàng)新點,。傳統(tǒng)的知識蒸餾方法需要訓(xùn)練一個單獨的教師網(wǎng)絡(luò),,并將其知識傳遞給學(xué)生網(wǎng)絡(luò)。然而,,這種方式需要預(yù)訓(xùn)練教師網(wǎng)絡(luò),,耗時且復(fù)雜。相比之下,,現(xiàn)有自蒸餾方法盡管消除了對單獨教師網(wǎng)絡(luò)的依賴,,但大多采用單一教師(通常為最后一層)為所有學(xué)生提供知識指導(dǎo),導(dǎo)致淺層網(wǎng)絡(luò)學(xué)習(xí)結(jié)果單一化,。本文所提出的漸進(jìn)式自蒸餾策略,,通過將知識從深塊逐漸蒸餾到淺塊來保證知識的多樣性學(xué)習(xí)。漸進(jìn)式自蒸餾過程僅應(yīng)用于訓(xùn)練階段,,可以輕松應(yīng)用于任何網(wǎng)絡(luò)以增強(qiáng)特征提取能力,。
GSDNet提出的漸進(jìn)式自蒸餾策略通過以下方式優(yōu)化知識傳遞過程:首先將整個網(wǎng)絡(luò)劃分為多個層級結(jié)構(gòu)的基本塊,每兩個相鄰塊之間形成“教師-學(xué)生”對,。深層塊作為教師,,淺層塊作為學(xué)生,;然后通過逐層的蒸餾學(xué)習(xí),,使得深層塊逐步將高語義特征傳遞給淺層塊,,避免淺層塊從單一深層塊中學(xué)習(xí)導(dǎo)致的特征單一化問題;在訓(xùn)練階段,,采用KL散度損失和L2損失對特征分布和概率分布進(jìn)行優(yōu)化,,確保淺層塊學(xué)習(xí)到的知識與深層塊相符。下面是漸進(jìn)式自蒸餾策略展示圖,。
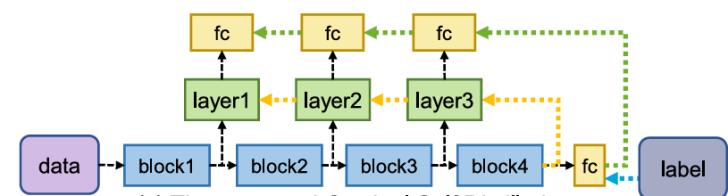
圖2 漸進(jìn)式自蒸餾策略
自適應(yīng)通道注意模塊
自適應(yīng)通道注意模塊(Adaptive Channel Attention Module, ACAM)是一種輕量化,、高效的注意機(jī)制,專注于優(yōu)化圖像特征的表達(dá)能力,,提升模型對關(guān)鍵區(qū)域的關(guān)注,。模塊通過動態(tài)調(diào)整不同通道的權(quán)重,將最大池化和平均池化相結(jié)合,,分別提取局部和全局特征信息,。最大池化捕獲局部激活值,強(qiáng)調(diào)細(xì)節(jié)特征,,而平均池化則關(guān)注全局趨勢,,體現(xiàn)整體信息。兩種特征經(jīng)過全連接網(wǎng)絡(luò)(MLP)計算權(quán)重比例,,動態(tài)融合生成最終特征向量,,用以更新特征圖的通道權(quán)重。這一機(jī)制能夠突出重要區(qū)域(如眼睛,、嘴角等),,抑制冗余信息,顯著增強(qiáng)模型在復(fù)雜場景中的適應(yīng)性和魯棒性,。與傳統(tǒng)注意力機(jī)制不同,,ACAM通過動態(tài)權(quán)重分配實現(xiàn)了針對性優(yōu)化,同時保持了輕量化的設(shè)計,,適用于各類深度學(xué)習(xí)網(wǎng)絡(luò),。實驗驗證顯示,ACAM在遮擋,、模糊等復(fù)雜環(huán)境下表現(xiàn)優(yōu)異,,顯著提升表情識別的準(zhǔn)確性和泛化能力,是優(yōu)化網(wǎng)絡(luò)特征提取的重要工具,。下面是ACAM的詳細(xì)結(jié)構(gòu)圖,。
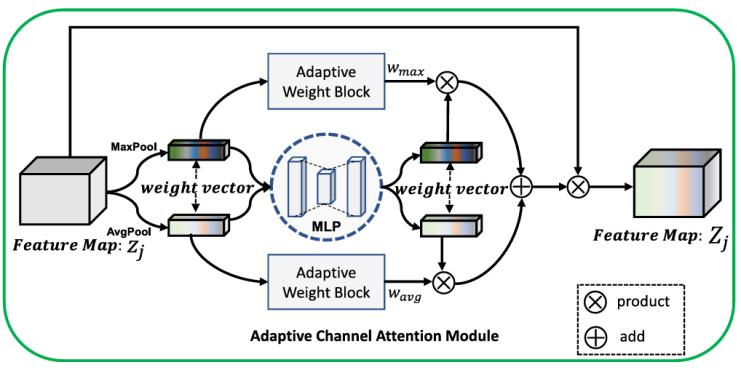
圖3 ACAM的詳細(xì)結(jié)構(gòu)圖
損失函數(shù)優(yōu)化
論文中通過引入多種損失函數(shù)的組合設(shè)計,優(yōu)化了模型的訓(xùn)練過程,,從而提升了面部表情識別的準(zhǔn)確性和魯棒性,。
交叉熵?fù)p失(CE Loss)是模型的核心損失函數(shù),用于主分類器,保證了模型對輸入表情的準(zhǔn)確預(yù)測,。交叉熵?fù)p失的計算公式:
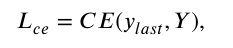
其中ylast表示最后一個分類器得到的預(yù)測概率分布,,Y表示對應(yīng)的標(biāo)簽。
KL散度損失(KL Loss)在漸進(jìn)式自蒸餾過程中發(fā)揮重要作用,,用于約束教師塊和學(xué)生塊之間預(yù)測概率分布的一致性,,從而實現(xiàn)教師塊對學(xué)生塊的有效知識傳遞。KL散度損失的計算公式:
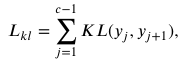
其中 yj 是第 j 個分類器的預(yù)測概率分布,。
L2特征損失(L2 Loss)通過最小化教師塊與學(xué)生塊之間的特征表達(dá)差異,,進(jìn)一步強(qiáng)化了學(xué)生塊的特征學(xué)習(xí)能力。L2損失的計算公式:
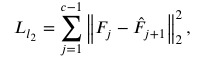
其中Fj表示第j個基本塊得到的特征圖,。
上述損失函數(shù)的聯(lián)合使用,,充分挖掘了模型不同模塊的潛力,確保了淺層塊在漸進(jìn)式蒸餾過程中的有效學(xué)習(xí),,同時提高了模型在多樣化和復(fù)雜場景下的表現(xiàn)能力,。這種設(shè)計不僅提升了模型的分類精度,也顯著增強(qiáng)了其對低質(zhì)量圖像或表情細(xì)微變化的適應(yīng)能力,,為輕量化網(wǎng)絡(luò)的優(yōu)化提供了重要支持,。
實驗結(jié)果
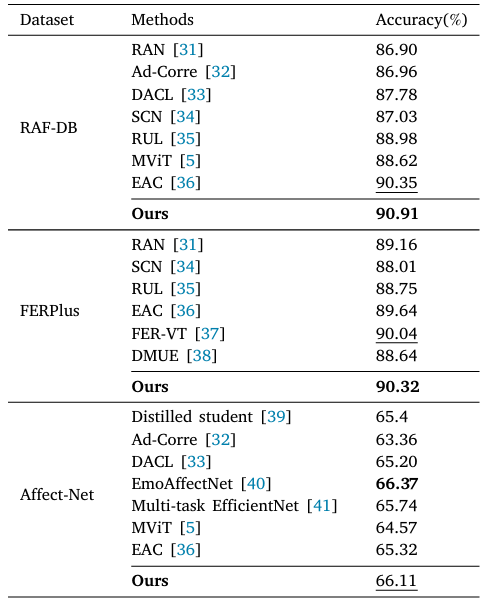
與現(xiàn)有的最先進(jìn)方法相比,GSDNet在面部表情識別任務(wù)中表現(xiàn)出色,。具體來說,,在RAF-DB數(shù)據(jù)集上,GSDNet的準(zhǔn)確率為90.91%,,比第二名高出0.62%,。在FERPlus數(shù)據(jù)集上,GSDNet也取得了最好的成績,,提升了0.31%,。盡管在AffectNet數(shù)據(jù)集上的準(zhǔn)確率為66.11%,略低于最好的基線方法(66.37%),,但整體表現(xiàn)仍然優(yōu)于現(xiàn)有方法,。下表是模型的表現(xiàn)。
表1 模型在RAF-DB,、FERPlus 和 Affect-Net 數(shù)據(jù)集的性能比較,。粗體表示最好的結(jié)果。下劃線表示第二好的結(jié)果,。
下圖是GSDNet 與基線 Resnet50比較的混淆矩陣,,混淆矩陣展示了ResNet50和GSDNet在RAF-DB和Affect-Net數(shù)據(jù)集上的表現(xiàn)。盡管Affect-Net數(shù)據(jù)集存在標(biāo)注質(zhì)量差和類別不平衡問題,,GSDNet在RAF-DB上表現(xiàn)優(yōu)于ResNet50,,尤其在識別“恐懼”和“厭惡”表情時,,精度分別提高了2.23%和6.32%。在Affect-Net數(shù)據(jù)集上,,GSDNet在識別“驚訝”,、“恐懼”和“中性”表情時,精度分別提高了3.84%,、2.99%和8.68%,。這表明GSDNet在表情識別任務(wù)中具有更強(qiáng)的能力和更好的性能,。
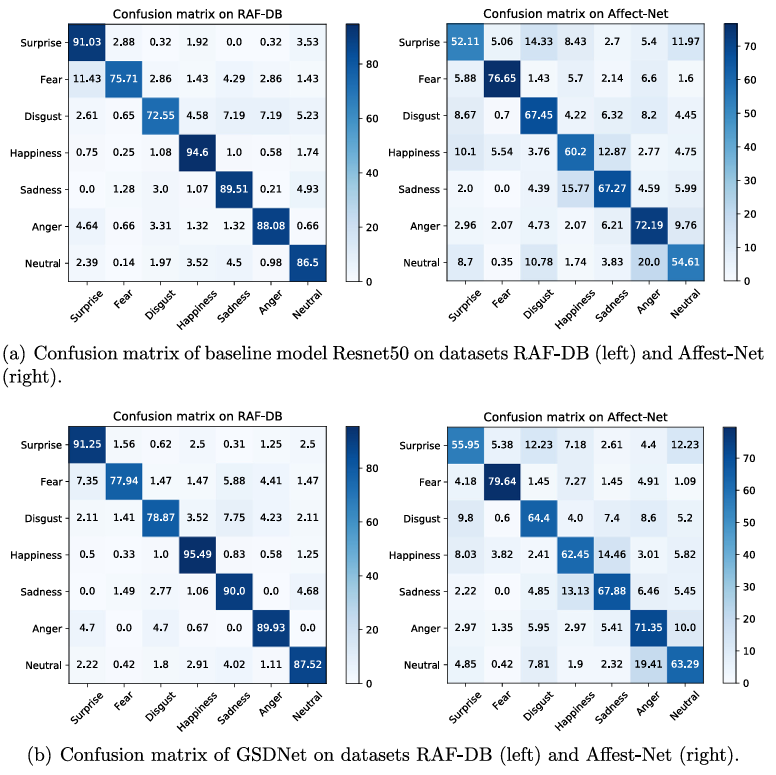
圖4 Resnet50 和提出的 GSDNet 在數(shù)據(jù)集 RAF-DB(左)和數(shù)據(jù)集 Affect-Net(右)上的混淆矩陣,。
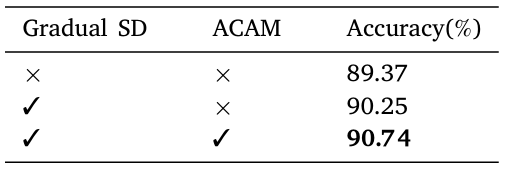
為了驗證漸進(jìn)式自蒸餾策略和自適應(yīng)通道注意模塊(ACAM)的有效性,作者在RAF-DB數(shù)據(jù)集上進(jìn)行了消融實驗,。實驗結(jié)果表明,,基線模型(ResNet50)與沒有漸進(jìn)式自蒸餾或ACAM的模型相比,采用漸進(jìn)式自蒸餾策略后,,準(zhǔn)確率提高了0.88%,;結(jié)合漸進(jìn)式自蒸餾和ACAM后,準(zhǔn)確率進(jìn)一步提高了1.37%,。這一消融實驗充分證明了漸進(jìn)式自蒸餾策略和ACAM在GSDNet中的有效性,。下表展示了漸進(jìn)式自蒸餾和ACAM的實驗結(jié)果。
表2 在 RAF-DB 數(shù)據(jù)集上對所提出的漸進(jìn)自蒸餾策略和 ACAM 進(jìn)行消融評估,。粗體表示最好的結(jié)果,。
結(jié)論
本研究提出了一種輕量級的結(jié)合自適應(yīng)通道注意模塊(ACAM)的漸進(jìn)式自蒸餾網(wǎng)絡(luò)(GSDNet)用于面部表情識別。文章中提出了一種新的漸進(jìn)式自蒸餾方法,,通過引導(dǎo)淺層學(xué)生模塊從相鄰深層教師模塊學(xué)習(xí),,增強(qiáng)了特征表示能力。自適應(yīng)通道注意模塊通過動態(tài)調(diào)整最大池化和平均池化特征的權(quán)重,,提升了通道特定的注意力,。通過在三個常用FER數(shù)據(jù)集上的廣泛實驗,驗證了GSDNet的有效性與實用性,。
撰稿人:閆玉龍
審稿人:梁艷
載")







載")