 286
286
 0
0
 2025-03-14
2025-03-14
 2025-03-14
2025-03-14

該論文發(fā)表于Pattern Recognition(中科院一區(qū),,IF=7.5),,題目為《Self-distillation with β label smoothing-based cross-subject transfer learning for P300 classification》,。
華東理工大學(xué)博士后李舒蕊為論文第一作者,華東理工大學(xué)金晶教授為論文通訊作者,。
論文鏈接:https://www.sciencedirect.com/science/article/pii/S0031320324008653
P300 拼寫器是腦機(jī)接口(BCI)最著名的系統(tǒng)之一,它通過解碼大腦活動(dòng)為用戶提供了一種與環(huán)境交流的新方式。然而,,大多數(shù)基于P300的BCI系統(tǒng)需要很長的校準(zhǔn)階段來開發(fā)特定被試的模型,這可能既不方便又耗時(shí),。此外,,由于個(gè)體間存在顯著的差異,實(shí)施跨被試 P300 分類仍具有挑戰(zhàn)性,。為了解決這些問題,,本研究提出了一種免校準(zhǔn)的 P300 信號(hào)檢測方法。具體來說,,本研究結(jié)合自蒸餾(Self-Distillation)和β標(biāo)簽平滑(β Label Smoothing)技術(shù),,以增強(qiáng)模型泛化和整體系統(tǒng)性能,這不僅可以從其他被試的腦電圖 (EEG) 數(shù)據(jù)中提煉出有效信息知識(shí),,還可以有效減少個(gè)體差異所帶來的影響,。在公開可用的OpenBMI數(shù)據(jù)集上進(jìn)行的結(jié)果表明,與現(xiàn)有方法相比,,所提出的方法在統(tǒng)計(jì)學(xué)上實(shí)現(xiàn)了顯著更高的性能,。值得注意的是,本研究的方法在無需校準(zhǔn)的情況下,,字符識(shí)別準(zhǔn)確率高達(dá) 97.37%,。信息傳輸率和可視化分析進(jìn)一步證實(shí)了其有效性。這種方法對腦機(jī)接口應(yīng)用的未來發(fā)展提供了重要前景,。
腦機(jī)接口(BCI)系統(tǒng)通過解碼神經(jīng)活動(dòng)并將其轉(zhuǎn)化為控制指令,,為用戶提供了一種無需肌肉參與的交互途徑,。該技術(shù)在通信,、康復(fù)和娛樂等領(lǐng)域具有廣闊應(yīng)用前景,尤其為肌萎縮側(cè)索硬化癥(ALS)等神經(jīng)肌肉疾病患者提供了新的生活改善方案,。黎曼幾何方法在 BCI 領(lǐng)域的應(yīng)用推動(dòng)了新型分類器的發(fā)展,,實(shí)現(xiàn)了更快的P300響應(yīng),深度學(xué)習(xí)技術(shù)的突破也為BCI系統(tǒng)帶來了新機(jī)遇,。盡管這些研究取得了有效成果,但不同被試之間存在個(gè)體差異,,且同一被試在不同時(shí)段的腦電數(shù)據(jù)也有所差異,,這些影響并沒有得到有效解決。圖1(a)展示了不同被試的 P300 波幅和潛伏期存在顯著個(gè)體差異,且同一被試的腦電數(shù)據(jù)在不同時(shí)段也呈現(xiàn)分布差異,,圖 1(b) 進(jìn)一步揭示多源被試的兩類數(shù)據(jù)存在嚴(yán)重重疊,表明傳統(tǒng)離線訓(xùn)練的 P300 系統(tǒng)存在耗時(shí)且泛化能力不足的問題,。近年來,,現(xiàn)有研究嘗試通過卷積神經(jīng)網(wǎng)絡(luò)(CNN)模型提升跨被試性能,,然而,,傳統(tǒng)神經(jīng)網(wǎng)絡(luò)模型普遍存在過擬合和預(yù)測置信度過高的問題,導(dǎo)致校準(zhǔn)性能下降,。
為了解決這些問題,,本研究提出基于域泛化的跨被試遷移學(xué)習(xí)框架(圖1(c)),,將自蒸餾與 β 標(biāo)簽平滑正則化方法相結(jié)合,,命名為SDB-Deepnet方法,可以提取更多的判別性特征,,并將學(xué)到的知識(shí)遷移到新的被試中且無需任何校準(zhǔn),。具體貢獻(xiàn)如下:
(1)利用深層卷積神經(jīng)網(wǎng)絡(luò)構(gòu)建無需校準(zhǔn)的P300檢測模型;
(2)通過自蒸餾框架提取跨被試有效知識(shí),,結(jié)合β標(biāo)簽平滑緩解數(shù)據(jù)分布差異和過擬合問題;
(3)所提出的方法在從 54 名被試收集的公開可用的OpenBMI 數(shù)據(jù)集上進(jìn)行評估,。實(shí)驗(yàn)結(jié)果表明,,所提出的方法比基線方法有顯著的改進(jìn)。
BCI 系統(tǒng)可分為信號(hào)采集,、特征提取和分類識(shí)別三個(gè)關(guān)鍵階段,,但由于被試之間的個(gè)體差異和同一被試不同時(shí)間段的腦電數(shù)據(jù)也有差異的影響,需要實(shí)現(xiàn)高效分類任務(wù)的整體框架與訓(xùn)練策略,。
作為輸出正則化器,,引入標(biāo)簽平滑正則化 (LSR)來提高網(wǎng)絡(luò)的泛化能力和學(xué)習(xí)效率,可以給每個(gè)非真實(shí)標(biāo)簽類別一個(gè)小而相等的概率,,從而降低過擬合的風(fēng)險(xiǎn),。Softmax 函數(shù)用作激活函數(shù),對最后一層的輸出進(jìn)行歸一化,,生成與輸入類別匹配概率相關(guān)的依賴概率分布,。給定模型的第k類概率可通過Softmax函數(shù)進(jìn)行如下計(jì)算:
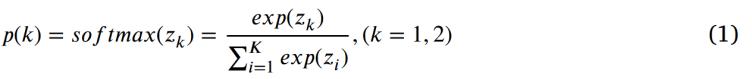 其中,zk 為前一層的第 k 個(gè)原始分?jǐn)?shù),,K 為類別總數(shù),。對數(shù)幾率輸出由最后一個(gè)全連接層生成。對對數(shù)幾率輸出應(yīng)用Softmax 函數(shù),以獲取每個(gè)類別的概率得分,。真實(shí)標(biāo)簽分布可表示為 q(k∣x),,為簡化表述,記作 q(k),。模型通過最小化對應(yīng)的交叉熵?fù)p失進(jìn)行訓(xùn)練,損失函數(shù)定義為:
其中,zk 為前一層的第 k 個(gè)原始分?jǐn)?shù),,K 為類別總數(shù),。對數(shù)幾率輸出由最后一個(gè)全連接層生成。對對數(shù)幾率輸出應(yīng)用Softmax 函數(shù),以獲取每個(gè)類別的概率得分,。真實(shí)標(biāo)簽分布可表示為 q(k∣x),,為簡化表述,記作 q(k),。模型通過最小化對應(yīng)的交叉熵?fù)p失進(jìn)行訓(xùn)練,損失函數(shù)定義為:
硬標(biāo)簽 yi 的分布可表示為:當(dāng) k=yi 時(shí),,q(y∣x)=1,;當(dāng) k≠yi 時(shí),q(k∣x)=0,。在標(biāo)簽平滑機(jī)制中,,平滑標(biāo)簽取代了獨(dú)熱向量標(biāo)簽。平滑標(biāo)簽分布 q′(k) 與標(biāo)簽分布 q(k) 的關(guān)系可寫為:
其中,,α 為平滑參數(shù),,u(k) 為均勻分布,且 u(k)=1/K,?;谄交瑯?biāo)簽的交叉熵?fù)p失如下:
因此,標(biāo)簽平滑對應(yīng)的模型損失函數(shù)可寫為:
其中,,KL 為 KL 散度,,H(u) 為固定均勻分布 u 的熵。
標(biāo)簽平滑正則化(LSR)方法,,通過將獨(dú)熱硬標(biāo)簽替換為平滑標(biāo)簽,,調(diào)整標(biāo)簽分布,向非真實(shí)類別分配概率,,優(yōu)化交叉熵?fù)p失,,使模型有效利用類間信息,提升分類任務(wù)穩(wěn)健性,,增強(qiáng)對未知數(shù)據(jù)的適應(yīng)性,。
知識(shí)蒸餾(KD)用于從大型深度神經(jīng)網(wǎng)絡(luò)(教師模型)提取知識(shí)并遷移至小型網(wǎng)絡(luò)(學(xué)生模型),以提升學(xué)生模型泛化能力,。實(shí)際上,,知識(shí)蒸餾為學(xué)生模型訓(xùn)練提供了更多信息,優(yōu)化了其性能,。鑒于訓(xùn)練后的神經(jīng)網(wǎng)絡(luò)可能在概率分布峰值過度集中而損失信息,,有研究提出溫度可以縮放軟化概率,此時(shí),,知識(shí)蒸餾損失LKD通過 KL 散度損失匹配學(xué)生ps=softmax(as/T)與教師pt=softmax(at/T)的軟化輸出,,公式如下:
其中,,as、at為學(xué)生與教師網(wǎng)絡(luò)的原始分?jǐn)?shù),,T為固定溫度超參數(shù),,用于調(diào)控教師網(wǎng)絡(luò)軟化輸出。T值增加會(huì)使Softmax概率分布更均勻,,捕獲更多信息,。學(xué)生網(wǎng)絡(luò)通過以下?lián)p失函數(shù)訓(xùn)練:
超參數(shù) β 權(quán)衡兩種損失,LSL為學(xué)生網(wǎng)絡(luò)輸出與真實(shí)標(biāo)簽的交叉熵?fù)p失,?;谏鲜鰮p失,有研究將知識(shí)蒸餾視為改進(jìn)的標(biāo)簽平滑正則化,,可對網(wǎng)絡(luò)分類器層正則化,。同時(shí),標(biāo)簽平滑與知識(shí)蒸餾相關(guān),,當(dāng)溫度T設(shè)為 1 時(shí),,可重新審視教師模型的隨機(jī)精度與平滑溫度。
本研究提出結(jié)合 β 平滑正則化方法的自蒸餾框架 SDB-Deepnet,。自蒸餾無需復(fù)雜教師模型,,減少訓(xùn)練開銷,訓(xùn)練中教師與學(xué)生網(wǎng)絡(luò)共享架構(gòu),??蚣芗?xì)節(jié)如圖 2,分為輸入層,、特征提取與分類層,、預(yù)測器和損失項(xiàng)。原始腦電數(shù)據(jù)先拼接,,預(yù)處理后尺寸為試次數(shù) × 通道數(shù) × 時(shí)間點(diǎn)數(shù),輸入數(shù)據(jù)尺寸為NT×NC×NF(NT為訓(xùn)練試次總數(shù),,NC為通道數(shù),,NF為時(shí)間點(diǎn)數(shù)),輸入網(wǎng)絡(luò)獲得概率pt和ps,。關(guān)鍵步驟為標(biāo)簽平滑策略,,將獨(dú)熱硬標(biāo)簽轉(zhuǎn)為平滑標(biāo)簽向量,再根據(jù)教師模型概率對學(xué)生模型的輸出排序,,得到排序概率p's,。
圖2展示了所設(shè)計(jì)算法的組成及方法。在輸入層,,對多個(gè)被試的腦電數(shù)據(jù)進(jìn)行預(yù)處理和連接,,以構(gòu)建輸入數(shù)據(jù),。pt 是教師模型的輸出,ps 是學(xué)生模型的輸出,,p's 是根據(jù)指數(shù)移動(dòng)平均 (EMA) 對學(xué)生模型的排序序列,。將兩個(gè)損失項(xiàng)(CE Loss和SD Loss)組合在一起,以端到端的方式優(yōu)化基礎(chǔ)模型,,其中 CE Loss是具有獨(dú)熱真實(shí)值的交叉熵?fù)p失,,SD Loss是具有 β 分布標(biāo)簽的自蒸餾損失。
在本研究中,,教師和學(xué)生具有相同的神經(jīng)網(wǎng)絡(luò),,稱為基礎(chǔ)模型,特征提取層的基礎(chǔ)模型是 DeepNet,。以深度卷積神經(jīng)網(wǎng)絡(luò) DeepNet 為基礎(chǔ)模型,,其自蒸餾部分的教師與學(xué)生網(wǎng)絡(luò)共享架構(gòu)(含四種卷積層和全連接層,見圖 3),。
以 DeepNet 為例:先經(jīng) 25 個(gè) (1, 4) 時(shí)間維度 2D 卷積,,再經(jīng) 25 個(gè) (62, 1) 空間維度 2D 卷積,用 ELU 激活函數(shù),,接 (1, 2) 最大池化(步長 2)降采樣,,最后 dropout rate設(shè) 0.25。經(jīng)四個(gè)卷積模塊(ConvPool-1 至 ConvPool-4)后,,數(shù)據(jù)輸入分類器,。學(xué)生模型的標(biāo)準(zhǔn)交叉熵?fù)p失 LCE 可以表示為:
其中,q(k) 是獨(dú)熱標(biāo)簽向量的第k個(gè)元素,,ps(k) 是學(xué)生模型輸出的分布,,接著是學(xué)生模型與基于Softmax函數(shù)輸出的 β 分布標(biāo)簽之間的損失。標(biāo)簽平滑部分包括對輸出進(jìn)行排序,、創(chuàng)建排序后的 β 平滑標(biāo)簽,,以及計(jì)算負(fù)對數(shù)似然(NLL)損失。本研究沒有采用公式(5)中描述的均勻分布u,,而是為標(biāo)簽平滑策略分配一個(gè) β 分布,。相應(yīng)的分布Q(k)如下:
其中,K 是類別總數(shù),,c(c=1,…,K)是正確標(biāo)簽,。b1≤?≤bm 是來自 β (a,1) 的一組隨機(jī)變量,其中m 是小批量大小,,a 對應(yīng)與 β 分布相關(guān)的超參數(shù),。由于本研究是二分類問題,K設(shè)置為2,。為了分配合適的權(quán)重,,本研究還充分利用訓(xùn)練過程中設(shè)計(jì)的指數(shù)移動(dòng)平均(EMA)預(yù)測,,獲取試驗(yàn)(從小到大)的標(biāo)簽,如圖 2 所示,??傊ㄟ^ EMA 預(yù)測得到的置信度較高的樣本將接受較少的標(biāo)簽平滑,,反之亦然,。同時(shí),對學(xué)生模型的輸出應(yīng)用排序操作,,得到排序后的分布p's(k),。自蒸餾的KL散度可以用NLL損失代替,其描述如下:
超參數(shù)γ用于調(diào)控兩種損失間的權(quán)衡,,本研究中將γ設(shè)定為0.1。對于知識(shí)蒸餾(KD)方法,,其通過師生學(xué)習(xí)機(jī)制輔助學(xué)生網(wǎng)絡(luò)學(xué)習(xí)判別性特征,,進(jìn)而提升學(xué)生模型性能。因此,,經(jīng)多次迭代更新流程后,,作為分類器的學(xué)生模型最終被用于識(shí)別其他被試的P300信號(hào)。
本研究采用公開的ERP數(shù)據(jù)集(命名為OpenBMI數(shù)據(jù)集)進(jìn)行方法驗(yàn)證,,該數(shù)據(jù)集采集自 54 名健康被試(S01-S54),。數(shù)據(jù)集包含不同日期的兩個(gè)階段,每個(gè)階段包括離線和在線部分,。本研究僅使用 ERP 階段的第一階段(session 1)進(jìn)行分析,。
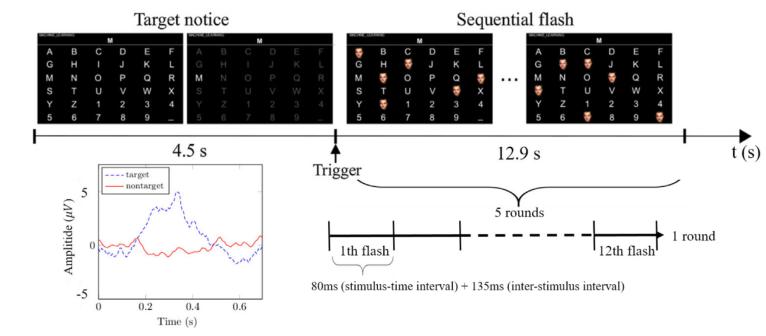
實(shí)驗(yàn)前,被試需坐在扶手椅上,,實(shí)驗(yàn)過程中要求被試放松并盡量減少眼動(dòng)和肌肉活動(dòng),。圖 4展示了 P300 拼寫器界面,包含6行6列共 36個(gè)符號(hào)(A-Z,、1-9 及空格),。
實(shí)驗(yàn)中每個(gè)目標(biāo)字符呈現(xiàn) 5 輪,每輪包含 12 次刺激閃爍(試次),,刺激間隔(ISI)為135 毫秒,,刺激持續(xù)時(shí)間80毫秒,。采用隨機(jī)序列呈現(xiàn)和熟悉面孔圖像作為刺激,,總時(shí)間間隔為:(135ms+80ms)×12×5=12.9秒。包含目標(biāo)字符的閃爍定義為目標(biāo)試次(含P300信號(hào)),,否則為非目標(biāo)試次(圖 4 左下),。被試需通過注視屏幕上的目標(biāo)字符拼寫包含 33個(gè)字符的句子("NEURAL_NETWORKS_AND_DEEP_LEARNING"),。
數(shù)據(jù)采集62 通道 EEG 信號(hào),采樣率 1000Hz,,參考電極(鼻根)和接地電極(AFz),。對選定的EEG信號(hào)應(yīng)用四階巴特沃斯濾波器進(jìn)行0.5Hz-40Hz的帶通濾波,然后從每個(gè)通道的刺激呈現(xiàn)中提取-200ms到800ms的時(shí)間特征,,將EEG信號(hào)下采樣至100Hz,,并通過減去 -200ms 到 0ms 刺激前間隔的平均振幅來執(zhí)行基線校正。最終得到特征向量尺寸為(54×1980)×62×80,,即(被試數(shù)×試次數(shù))×通道數(shù) × 時(shí)間點(diǎn)數(shù),。
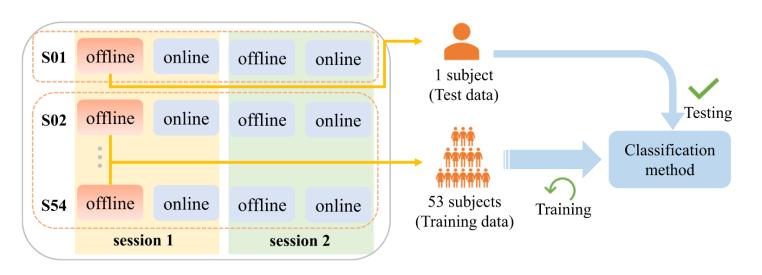 圖5 54折交叉驗(yàn)證深度學(xué)習(xí)模型單被試框架
圖5 54折交叉驗(yàn)證深度學(xué)習(xí)模型單被試框架
圖 5 展示了所選訓(xùn)練樣本示例。本研究使用第一階段(橙色框)的離線數(shù)據(jù),,并執(zhí)行留一被試交叉驗(yàn)證(LOO-CV),。使用自適應(yīng)矩估計(jì)(ADAM)優(yōu)化器優(yōu)化損失函數(shù),初始學(xué)習(xí)率η設(shè)為5e−4,,權(quán)重衰減設(shè)為1e−3,,并采用 0.25 的dropout rate。本實(shí)驗(yàn)將每個(gè)被試獨(dú)立分類的批量大小設(shè)為 64 ,,訓(xùn)練迭代次數(shù)設(shè)為 100,。采用t分布隨機(jī)鄰域嵌入(t-SNE)方法來顯示投影后的腦電圖試次,一個(gè)類與其他類分離的實(shí)例越多,,相關(guān)功能的性能就越好,。
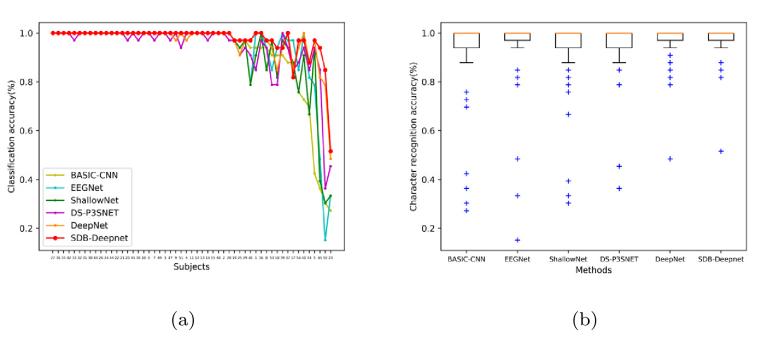
表1 各深度學(xué)習(xí)算法平均字符識(shí)別準(zhǔn)確率和信息傳輸率
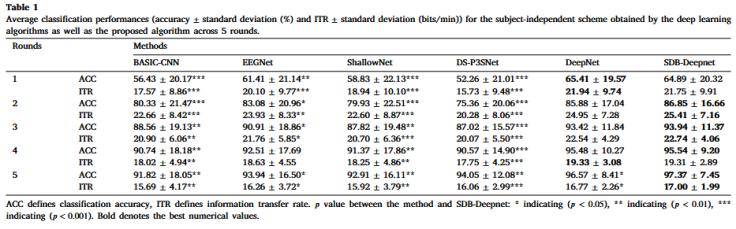
表 1 中所提出的方法在五輪后達(dá)到了最高的分類準(zhǔn)確率,分別比BASIC-CNN,、EEGNet,、ShallowNet、DS-P3SNet和DeepNet平均高出5.55%,、3.43%,、4.46%、3.32% 和 0.8%,。
圖6 各算法字符識(shí)別準(zhǔn)確率和對應(yīng)箱線圖
使用與被試無關(guān)的深度學(xué)習(xí)方法時(shí),,超過一半的被試在五輪后準(zhǔn)確率可達(dá) 100%。此外,,在跨被試分類任務(wù)中,,DeepNet 在四種基線方法中取得了最佳結(jié)果。
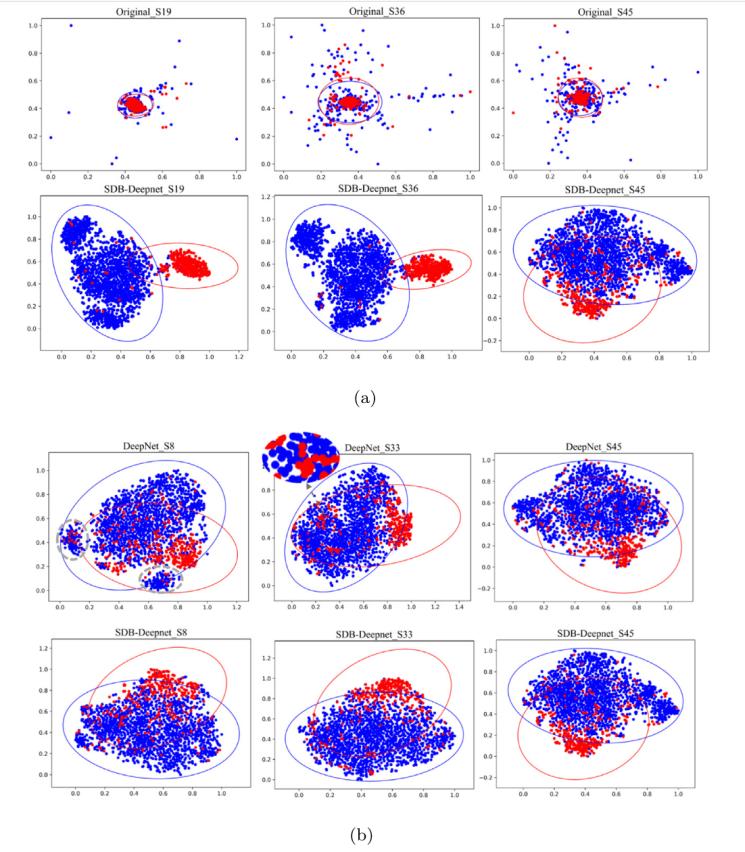
紅點(diǎn)表示從目標(biāo)樣本中獲得的特征,,藍(lán)點(diǎn)表示從非目標(biāo)樣本中獲得的特征,。圖 7(a)分別描繪了應(yīng)用SDB-Deepnet 前后特征分布的 t-SNE 可視化結(jié)果??梢杂^察到,,在原始分布中,,兩類特征相互重疊,而在SDB-Deepnet 方法中邊界清晰,,這表明所提出的方法可以有效地實(shí)現(xiàn)領(lǐng)域不變特征表示,。圖 7(b)展示了使用DeepNet和SDB-Deepnet 方法,以與被試無關(guān)的方式對三名代表性參與者(S8,、S33 和 S50)的可視化結(jié)果,。根據(jù)置信橢圓的重疊情況,可以得出結(jié)論,,在SDB-Deepnet中,,不同類別變得更加集中且更容易區(qū)分。
表2 各傳統(tǒng)機(jī)器學(xué)習(xí)算法平均字符識(shí)別準(zhǔn)確率和信息傳輸率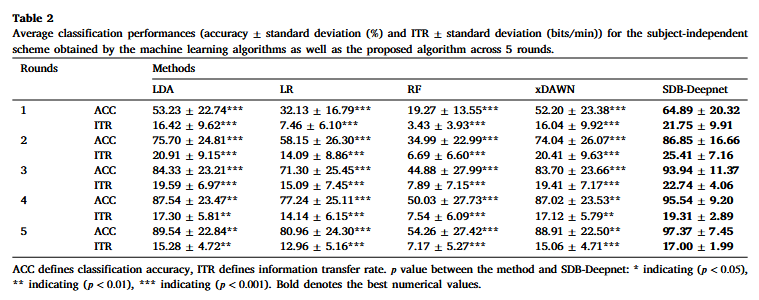
經(jīng)過五輪后,,所有被試使用 LDA,、LR、RF 和 xDAWN的平均分類準(zhǔn)確率分別為89.54%,、80.96%,、54.26% 和 88.91%,這些方法的平均信息傳輸率分別為15.28 bits/min,、12.96 bits/min,、7.17 bits/min和 15.06 bits/min。所提出的方法獲得了最高的準(zhǔn)確率,,在五輪后分別比LDA,、LR、RF和xDAWN平均高出 7.83%,、16.41%,、43.11% 和 8.46%。
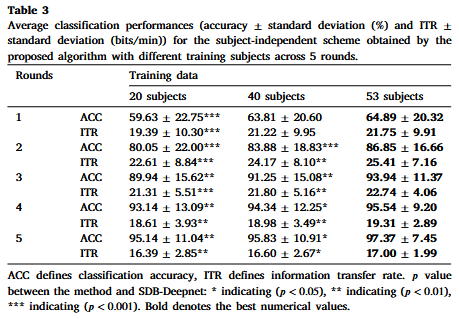
表3 使用不同數(shù)量被試時(shí)的性能
隨著訓(xùn)練數(shù)據(jù)的增加,,分類準(zhǔn)確率相應(yīng)提高,,使用 53 名被試的訓(xùn)練集取得了最高的性能。使用標(biāo)準(zhǔn) 21個(gè)通道(缺少通道FPz)在五輪后的字符識(shí)別準(zhǔn)確率和標(biāo)簽預(yù)測準(zhǔn)確率分別為 96.28% 和 90.50%,,相應(yīng)的信息傳輸率分別為 16.69 bits/min和 14.66 bits/min,。因此,本實(shí)驗(yàn)選擇了所有 62個(gè)通道進(jìn)行分析,。
為證明正則化和知識(shí)蒸餾(KD)方法在 P300 檢測中的有效性,,本研究以與被試無關(guān)的方式,擴(kuò)展了其他方法來泛化深度網(wǎng)絡(luò)模型,。通過將LSR作為一個(gè)隨機(jī)準(zhǔn)確性的虛擬教師模型來執(zhí)行無教師知識(shí)蒸餾(TF-KD),。教師模型的輸出分布定義如下:

其中,u(k) 是手動(dòng)設(shè)計(jì)的均勻分布,超參數(shù) a 設(shè)為 0.99,。將學(xué)生模型設(shè)為 DeepNet,同時(shí)將教師模型更改為Shallow-Deep,。
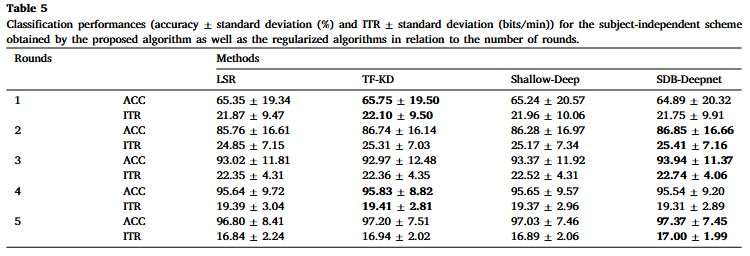
表5 各算法與被試無關(guān)分類方式下的平均字符識(shí)別準(zhǔn)確率和信息傳輸率
SDB-Deepnet 在五輪后達(dá)到 97.37% 的最高準(zhǔn)確率,,同時(shí)產(chǎn)生 25.41 bits/min的最佳信息傳輸率。根據(jù)表 5 的結(jié)果,,與擴(kuò)展方法相比,,所提方法有統(tǒng)計(jì)學(xué)上的顯著提升,這證明了當(dāng)前正則化和 KD 方法在 P300 分類任務(wù)中展現(xiàn)出良好的性能,。
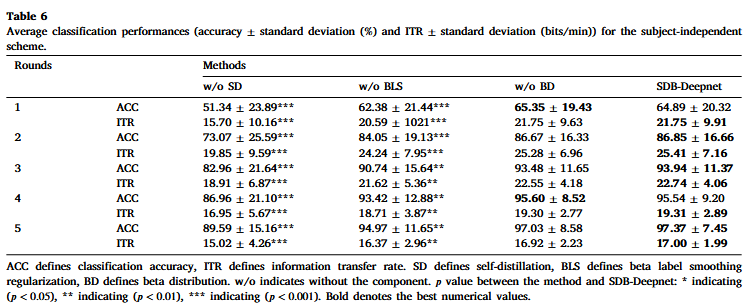
表6 SDB-Deepnet三個(gè)模塊的消融研究
第一個(gè)實(shí)驗(yàn)(w/o SD)中,,移除自蒸餾,采用 β 平滑機(jī)制對模型訓(xùn)練進(jìn)行正則化,;第二個(gè)實(shí)驗(yàn)(w/o BLS)中,,移除 β 平滑機(jī)制,保留自蒸餾機(jī)制,;第三個(gè)實(shí)驗(yàn)(w/o BD)中,,去除 β 標(biāo)簽平滑機(jī)制,改用標(biāo)簽平滑正則化(LSR)計(jì)算用于模型訓(xùn)練的平滑標(biāo)簽,。從SDB-Deepnet 中移除自蒸餾方法后,,分類準(zhǔn)確率(p<0.001)和 ITR(p<0.001)顯著降低,五輪 P300 分類任務(wù)后,,準(zhǔn)確率下降 7.78%,,ITR 下降 1.98 bits/min。而 β 標(biāo)簽平滑機(jī)制的貢獻(xiàn)小于自蒸餾,,五輪后分類準(zhǔn)確率僅下降 0.34%/0.08bits/min,,無顯著下降。當(dāng)用標(biāo)簽平滑正則化機(jī)制替代 β 平滑正則化機(jī)制時(shí),,準(zhǔn)確率(p<0.01)和 ITR(p<0.01)顯著提升,。
本研究提出一個(gè)融合自蒸餾與β標(biāo)簽平滑正則化機(jī)制的SDB-Deepnet框架,在模型自身內(nèi)部提取知識(shí)來提升訓(xùn)練網(wǎng)絡(luò)的有效性,,無需任何額外大型復(fù)雜網(wǎng)絡(luò)的指導(dǎo),,將 β 平滑正則化機(jī)制融入該框架,通過最小化 β 分布與網(wǎng)絡(luò)預(yù)測分布的Kullback-Leibler散度,,進(jìn)一步減少類內(nèi)差異,,通過從多個(gè)被試中提取共有的 P300 信息來提升泛化能力,探索了訓(xùn)練跨被試模型的可行性,。實(shí)驗(yàn)結(jié)果證明了所提 SDB-Deepnet方法的有效性,,該方法在無需任何校準(zhǔn)數(shù)據(jù)的情況下實(shí)現(xiàn)了優(yōu)越的分類性能。未來工作將進(jìn)一步探索平滑參數(shù)自適應(yīng)的可能性,將構(gòu)建不同的損失函數(shù)以懲罰關(guān)系中的結(jié)構(gòu)差異,,并將 ERP 特征作為先驗(yàn)信息來指導(dǎo)網(wǎng)絡(luò)優(yōu)化,,從而提升模型性能,也會(huì)將其擴(kuò)展到快速序列視覺呈現(xiàn)任務(wù),。
載")
贊")







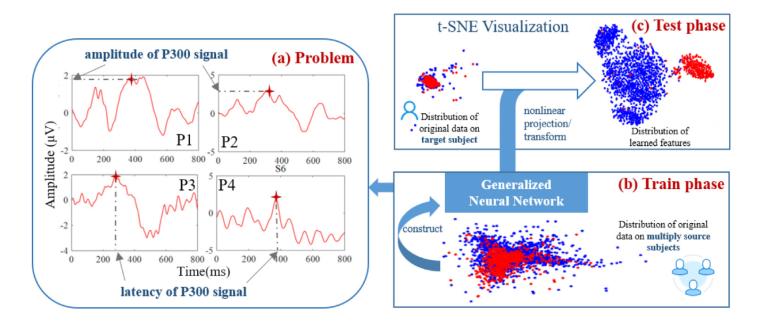



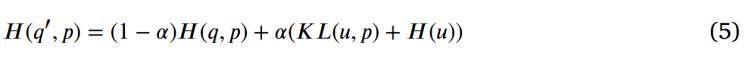



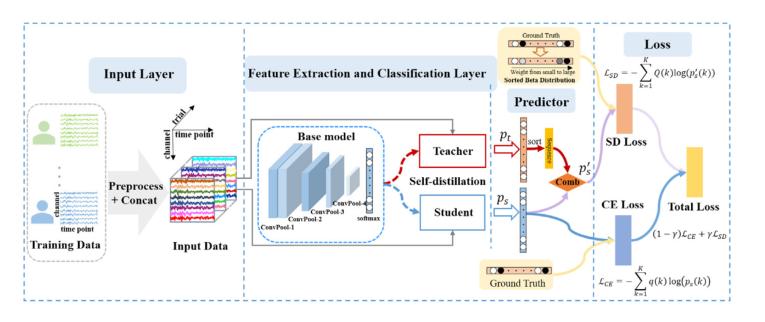 圖2 SDB-Deepnet 算法的圖形說明
圖2 SDB-Deepnet 算法的圖形說明




載")