
 1677
1677
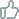 2
2
 0
0
 2020-06-08 15:23:39
2020-06-08 15:23:39
 2020-06-08
2020-06-08
【導(dǎo)語】隨著Web服務(wù)數(shù)量不斷增加,越來越多的Web服務(wù)提供相似的功能,。服務(wù)質(zhì)量(Quality of Service,,QoS)描述了Web服務(wù)的非功能特性,是區(qū)分這些功能相似Web服務(wù)的重要標準,。準確的QoS預(yù)測對于這些QoS感知方法越來越重要,。協(xié)同過濾(CF)是推薦系統(tǒng)中最成功的個性化預(yù)測技術(shù)之一,在Web服務(wù)QoS預(yù)測中也得到了廣泛的應(yīng)用,。盡管在這方面已有大量的工作,,但似乎沒有一個權(quán)威的調(diào)研綜述。為了彌補這一不足,,最近,,中山大學(xué)InPlusLab關(guān)于協(xié)同過濾在Web服務(wù)QoS預(yù)測應(yīng)用的調(diào)研綜述論文Web Service QoS Prediction via Collaborative Filtering: A Survey被IEEE Transactions on Services Computing(TSC)期刊錄用,影響因子5.707,。文章首先總結(jié)和分析了傳統(tǒng)的基于內(nèi)存和基于模型的CF-QoS預(yù)測方法以及擴展CF方法,。其次,調(diào)研了混合CF-QoS預(yù)測方法,,并給出了適當?shù)姆诸惡头治?。此外,還介紹了幾個用于QoS預(yù)測評估的Web服務(wù)QoS數(shù)據(jù)集,,并在最后提出一些可能的未來QoS預(yù)測的研究方向,。
論文下載鏈接: http://inpluslab.com/files/wsqos.pdf

1. 簡介
QoS預(yù)測對一些QoS感知的方法非常重要,比如圖1的基于QoS的服務(wù)選擇:復(fù)合服務(wù)S_com由幾個抽象服務(wù)(S1到S5)組成,,每個抽象服務(wù)都可以從一組功能相似的具體服務(wù)(si1, si2, ..., siN)中選擇,。QoS感知服務(wù)選擇的目的是從這些功能相似的服務(wù)集合中選擇合適的服務(wù),形成一個優(yōu)化的復(fù)合服務(wù),。
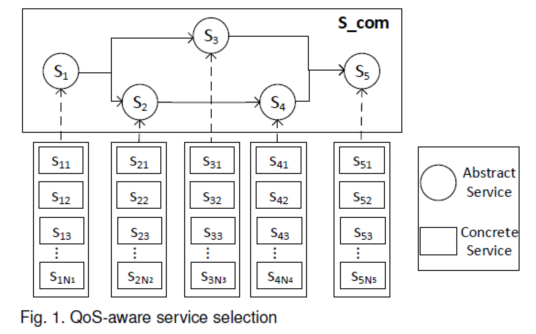
QoS預(yù)測的方法分類如下:
2. QoS預(yù)測問題介紹
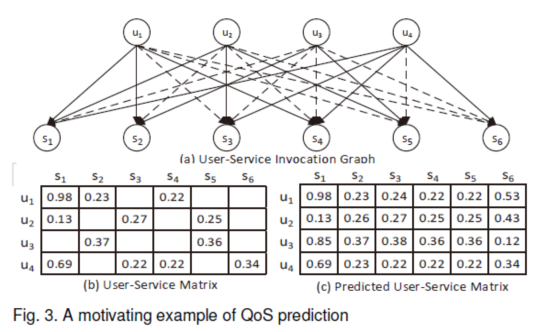
圖3是QoS預(yù)測的一個示例,。在圖3(a)中,,U={u1,u2,,…,,u4}為Web服務(wù)用戶集,S={s1,,s2,,…,s6}為Web服務(wù)集,,E(實線)為U和S之間的調(diào)用集,。ui和sj之間的連線eij表示用戶ui以前調(diào)用過Web服務(wù)sj。線段eij上的權(quán)重wij指的是該調(diào)用的QoS值(例如,,響應(yīng)時間等),。用戶服務(wù)調(diào)用可以由矩陣P表示,如圖3(b)所示,。P中的每個值pij表示服務(wù)用戶ui觀察到的Web服務(wù)si的QoS值,。P中缺少的QoS值表示對應(yīng)的用戶和Web服務(wù)之間沒有調(diào)用。Web服務(wù)QoS預(yù)測問題可以定義為:給定已知的用戶調(diào)用Web服務(wù)的QoS值矩陣P(用戶-服務(wù)矩陣),,預(yù)測P中缺失的QoS值,。
3. 協(xié)同過濾背景簡介
協(xié)同過濾算法大致可以分為兩類:基于內(nèi)存的和基于模型的協(xié)同過濾。
典型的基于內(nèi)存的CF方法可以描述為一個三階段的過程:相似性計算,、鄰居選擇和缺失值預(yù)測,。Pearson相關(guān)系數(shù)(PCC)算法和向量空間相似性(VSS)算法通常用于相似性計算,,然后選擇相似度高的用戶或項目作為彼此的相似鄰居,,在確定了鄰居集之后,下一步是利用來自相似鄰居的信息來預(yù)測未知評分,。根據(jù)相似度的計算類型,,基于內(nèi)存的CF方法可以分為三類:基于項目的方法、基于用戶的方法以及這兩種方法的融合,。與基于內(nèi)存的方法不同,,基于模型的CF方法通常先構(gòu)造具有適當參數(shù)的預(yù)定義模型,該模型在學(xué)習(xí)過程結(jié)束后將具有一定的預(yù)測未知評分的能力,,可以對整體結(jié)構(gòu)產(chǎn)生良好的估計,。許多CF方法只處理兩種類型的實體,即用戶和項目,,而不考慮任何上下文信息,,如時間、位置等,。然而,,僅考慮用戶和項目可能是不夠的,。通過考慮上下文信息,可以提供更好的建議,。
4. 基于內(nèi)存的QoS預(yù)測
4.1 傳統(tǒng)的基于內(nèi)存的QoS預(yù)測方法
許多方法使用傳統(tǒng)的基于內(nèi)存的CF來進行QoS預(yù)測,。它們只使用用戶-服務(wù)QoS矩陣,并試圖從以下四個方面來提高預(yù)測性能:
(1)數(shù)據(jù)預(yù)處理:數(shù)據(jù)預(yù)處理是提高數(shù)據(jù)質(zhì)量的重要步驟,,提高了Web服務(wù)QoS預(yù)測的性能,。
(2)相似度計算:在基于內(nèi)存的協(xié)同預(yù)測方法中,相似性扮演著雙重角色:過濾不同的鄰居(為目標用戶或服務(wù)獲取相似的鄰居)和加權(quán)相似鄰居對協(xié)同預(yù)測的重要性,。因此,,相似性計算是CF中最重要的設(shè)計決策之一,良好的度量往往會帶來良好的性能,。
(3)相似鄰居選擇:在預(yù)測缺失的值之前,,需要確定包含相似用戶或服務(wù)的鄰居。相似鄰居的選擇是準確預(yù)測缺失值的重要步驟,,因為不相似的鄰域會降低預(yù)測精度,。
(4)QoS值預(yù)測:在為每個用戶或服務(wù)計算了一組鄰居之后,通常通過這些鄰居來預(yù)測QoS值,?;谟脩舻姆椒ㄊ褂孟嗨朴脩舻腝oS值,基于項的方法使用相似Web服務(wù)的QoS值來預(yù)測QoS值,。融合方法責(zé)結(jié)合基于用戶和基于項目的方法來預(yù)測缺失值,。
4.2 融合地理位置的基于內(nèi)存的QoS預(yù)測方法
QoS高度依賴于底層網(wǎng)絡(luò)的性能。如果用戶和被調(diào)用的服務(wù)位于因特網(wǎng)上彼此相距較遠的不同網(wǎng)絡(luò)中,,則由于數(shù)據(jù)傳輸延遲和不同網(wǎng)絡(luò)之間鏈路的有限帶寬,,網(wǎng)絡(luò)性能可能較差。相反,,當用戶和Web服務(wù)位于同一個網(wǎng)絡(luò)中時,,更可能獲得高的網(wǎng)絡(luò)性能。因此,,用戶和服務(wù)的位置是影響QoS的關(guān)鍵因素,。通過考慮位置信息,可以避免選擇不合適的鄰居的問題,,從而提高QoS預(yù)測的準確性,。
根據(jù)位置的表示方法,我們將融合地理位置的基于內(nèi)存的QoS預(yù)測方法分為三類:經(jīng)緯度坐標,、IP地址和自治系統(tǒng)方法,。
4.3 融合時間信息的基于內(nèi)存的QoS預(yù)測方法
Web服務(wù)的QoS性能與服務(wù)調(diào)用時間密切相關(guān),因為服務(wù)狀態(tài)(例如,,工作負載或客戶端數(shù)量)和網(wǎng)絡(luò)環(huán)境(例如,,擁塞)隨時間而變化,。一般來說,較長的時間跨度表示QoS值偏離其原始值的概率較高,。因此,,時間因素是預(yù)測QoS的一個非常重要的因素。
我們將融合時間信息的基于內(nèi)存的QoS預(yù)測方法分為三類:時間間隔模型,、時間衰減模型和時間序列模型,。
4.4 融合其他上下文的基于內(nèi)存的QoS預(yù)測方法
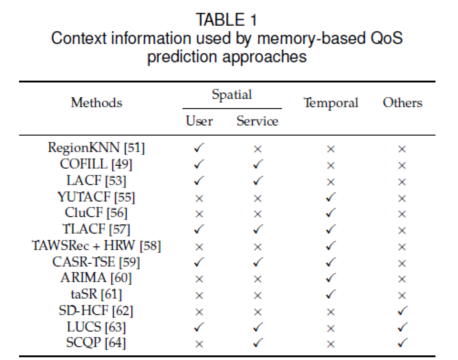
除了與用戶或服務(wù)相關(guān)聯(lián)的空間和時間信息,在實際應(yīng)用中,,如果加入更多的上下文信息,,CF算法的性能將得到提高。Table 1總結(jié)了基于內(nèi)存的QoS預(yù)測方法使用的上下文信息,。
5. 基于模型的QoS預(yù)測
5.1 傳統(tǒng)的基于模型的QoS預(yù)測方法
基于內(nèi)存的CF算法實現(xiàn)簡單,,效率高,但受數(shù)據(jù)稀疏性的影響較大,,并且存在冷啟動,、可擴展性差等問題?;趦?nèi)存的CF方法的關(guān)鍵步驟是通過利用用戶的歷史QoS值和上下文信息來識別每個用戶或服務(wù)的相似鄰居,。這些方法很好地利用了本地信息,但卻忽略了全局結(jié)構(gòu),。由于基于模型的CF算法使用用戶服務(wù)矩陣(全局信息)中的所有QoS值來構(gòu)建用于進行QoS值預(yù)測的全局模型,,因此它們能夠很好地估計與所有用戶或服務(wù)相關(guān)的總體結(jié)構(gòu)。
5.2 融合地理位置的基于模型的QoS預(yù)測方法
矩陣分解是比較受關(guān)注的基于模型的方法,。為了整合位置信息,,矩陣分解模型需要完成兩個任務(wù)。首先,,對相似性進行改進,,融合位置信息,,然后選擇相似的鄰域,。其次,將相似鄰居的QoS值集成到矩陣分解模模型中,。
5.3 融合時間信息的基于模型的QoS預(yù)測方法
我們將融合時間信息的基于模型的QoS預(yù)測方法分成:張量的潛在因子分解模型,、統(tǒng)計時間序列模型、基于神經(jīng)網(wǎng)絡(luò)的模型以及其他模型,。
5.4 融合其他上下文的基于模型的QoS預(yù)測方法
Table 2總結(jié)了基于模型的QoS預(yù)測方法使用的上下文信息,。

6. 混合協(xié)同過濾的QoS預(yù)測方法
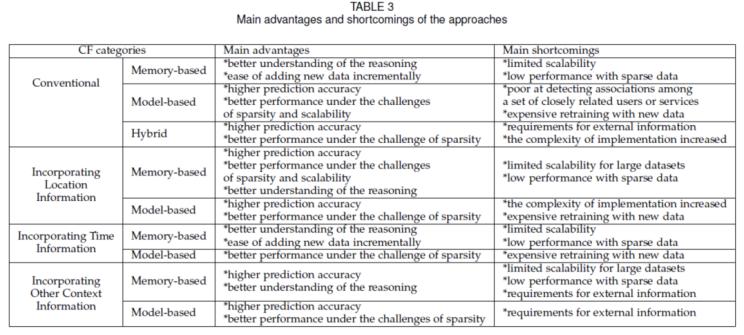
基于內(nèi)存的方法利用用戶-服務(wù)矩陣中相似用戶或服務(wù)的局部信息來檢測鄰域關(guān)系,往往忽略了用戶的絕大多數(shù)QoS值,,因此它們無法捕獲包含在用戶的所有QoS值中的弱信號,?;谀P偷姆椒ɑ谟^測到的QoS數(shù)據(jù)構(gòu)造一個全局模型,它們通常能有效地估計與大部分或所有服務(wù)相關(guān)的總體結(jié)構(gòu),。然而,,這些方法在檢測一組密切相關(guān)的用戶或服務(wù)之間的強關(guān)聯(lián)方面很差?;趦?nèi)存和基于模型的方法處理數(shù)據(jù)中不同層次的結(jié)構(gòu),,因此它們都不是自己的最佳方法?;旌螩F方法結(jié)合了基于內(nèi)存和基于模型的方法,,解決了上述CF方法的局限性,提高了預(yù)測性能,。Table 3總結(jié)了基于內(nèi)存的,、基于模型的以及混合的QoS預(yù)測方法的優(yōu)缺點。
7. 現(xiàn)有的一些挑戰(zhàn)
以上討論的方法集中在如何在稀疏性,、可伸縮性和客觀性的挑戰(zhàn)下提高預(yù)測的準確性,。然而,最近一段時間,,又出現(xiàn)了三個挑戰(zhàn):
(a)在動態(tài)環(huán)境中,,現(xiàn)有的QoS值將用新觀察到的值不斷更新。
(b)某些用戶提供的QoS值可能不可信,,這是由惡意用戶提交不正確的QoS值造成的,。
(c)由于用戶的隱私信息可能是從提交的QoS值中推斷出來的,因此應(yīng)該有保護用戶隱私的策略,。
在這一部分中,,我們分別討論了通過自適應(yīng)CF-QoS預(yù)測、可信CF-QoS預(yù)測和隱私保護CF-QoS預(yù)測來應(yīng)對這三個挑戰(zhàn)的方法,。
8. 數(shù)據(jù)集介紹
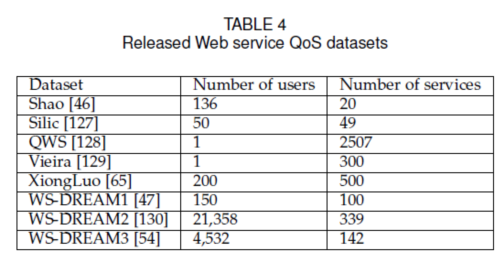
隨著各種Web服務(wù)QoS預(yù)測方法的深入研究,,需要一個大規(guī)模的現(xiàn)實Web服務(wù)QoS數(shù)據(jù)集來比較它們的預(yù)測性能。在Table 4中,,我們總結(jié)了一些用于QoS預(yù)測的數(shù)據(jù)集,。
9. 未來可研究方向
以往的工作表明,CF方法在Web服務(wù)QoS預(yù)測方面已經(jīng)取得了很大的進展,。然而,,在某些條件下,CF方法還不能提供令人滿意的解決方案,。在這一部分中,,我們考慮了一些有希望的進一步研究方向。
(1)其他新興服務(wù)的QoS預(yù)測:
Web服務(wù)QoS預(yù)測的研究應(yīng)該擴展到非WSDL描述的服務(wù),因為現(xiàn)代Web服務(wù)中有很大一部分是非WSDL描述的,,如基于云的服務(wù),、移動服務(wù)和物聯(lián)網(wǎng)服務(wù)。首先,,云計算的普及促進了云服務(wù)的快速增長,。數(shù)以百萬計的基于云的服務(wù)提供多種實時功能。其次,,智能手機,、平板電腦、可穿戴設(shè)備和自主車輛等智能移動設(shè)備越來越受歡迎,。在移動設(shè)備時代,,數(shù)百萬的移動服務(wù)可以從應(yīng)用商店下載。第三,,在物聯(lián)網(wǎng)環(huán)境中,,大量的異構(gòu)設(shè)備引起了對QoS的關(guān)注,在物聯(lián)網(wǎng)體系結(jié)構(gòu)的每一層都提出了QoS方法,,并考慮了不同的QoS特性,。為了滿足用戶需求,預(yù)測大規(guī)模,、高動態(tài)服務(wù)的QoS值是一個關(guān)鍵的挑戰(zhàn),。
(2)分布式QoS預(yù)測方法:
典型的QoS預(yù)測系統(tǒng)收集自己用戶的QoS數(shù)據(jù)。這導(dǎo)致了歷史QoS數(shù)據(jù)分布在不同的平臺上,。其中一些平臺可能沒有足夠的用戶數(shù)據(jù)來實現(xiàn)高預(yù)測精度,。由于數(shù)據(jù)隱私,這些平臺可能愿意但不敢與其他平臺共享數(shù)據(jù),。盡管有人提出了一些解決分布式場景下數(shù)據(jù)隱私的研究,,但是在分布式場景中,性能和隱私保護仍然是一個挑戰(zhàn),。另一方面,,預(yù)測是基于用戶貢獻的QoS數(shù)據(jù)。不過,,目前還沒有鼓勵用戶捐款的激勵機制,。需要一個公平的激勵機制,即用戶貢獻越多,,獲得的回報就越大,。此外,參與者的真實性應(yīng)該是可驗證的,,因為有些參與者可能會表現(xiàn)出不正常的行為,甚至故意表現(xiàn)出模糊或潛在的敵對行為,以最大限度地提高他們的經(jīng)濟利益,。設(shè)計基于區(qū)塊鏈的QoS預(yù)測方法,,通過保證用戶不受欺詐的影響,鼓勵用戶參與,,將是未來的一個重要研究方向,。
(3)QoS預(yù)測的新方法:
雖然最近的方法在一定程度上取得了良好的效果,但仍有很大的改進空間,。采用新技術(shù)進一步提高預(yù)測精度是一個有希望的方向,。例如,圖神經(jīng)網(wǎng)絡(luò)(GNN)作為一種新興的推薦模型,,最近被用于推薦系統(tǒng)中,。GNN對相鄰節(jié)點的特征信息進行聚合,得到目標節(jié)點的特征信息,,然后通過逐層融合獲取整個圖的結(jié)構(gòu)信息,。將GNN應(yīng)用于QoS預(yù)測中,可以利用相鄰節(jié)點的特征信息和整個圖的結(jié)構(gòu)信息進行預(yù)測,,從而緩解數(shù)據(jù)稀疏和冷啟動的問題,。作為另一個例子,上下文感知服務(wù)網(wǎng)絡(luò)中存在著各種各樣的對象和豐富的關(guān)系,,例如空間和時間信息,,它們自然形成了一個異構(gòu)的信息網(wǎng)絡(luò)。豐富的異構(gòu)信息可以結(jié)合到QoS預(yù)測中,,解決數(shù)據(jù)稀疏和冷啟動問題,。
(4)工業(yè)實施案例研究:
QoS預(yù)測在基于服務(wù)的系統(tǒng)開發(fā)中扮演著越來越重要的角色。但目前對于QoS預(yù)測的工業(yè)實現(xiàn)還缺乏研究,。一方面,,在現(xiàn)實世界的實現(xiàn)中,數(shù)以百萬計的服務(wù)為數(shù)以百萬計的用戶提供實時功能,。為了滿足用戶的需求,,預(yù)測大規(guī)模、高動態(tài)服務(wù)的QoS值是一項困難的任務(wù),。另一方面,,由于用戶數(shù)據(jù)隱私問題,工業(yè)公司可能不愿意披露如何使用QoS預(yù)測方法的信息,。然而,,研究基于CF的QoS預(yù)測在工業(yè)中的應(yīng)用是非常重要的,這將增加本文工作的意義,。工業(yè)實施的案例研究可能提供一個有希望的方向,,這需要迫切關(guān)注,。






載")

