
 1812
1812
 1
1
 0
0
 2020-08-07 12:29:10
2020-08-07 12:29:10
 2020-08-14
2020-08-14
基于清華大學(xué)李涓子教授“知識(shí)圖譜研究綜述”一文的閱讀筆記
根據(jù)論文大概分為幾個(gè)模塊
一,、概念
知識(shí)圖譜旨在描述客觀世界的概念,、實(shí)體、事件及其間的關(guān)系
概念是指人們認(rèn)識(shí)世界過程中形成的對(duì)客觀事物的概念化,如人,、動(dòng)物、組織機(jī)構(gòu)等,;
實(shí)體是客觀世界中的具體事物,,如籃球運(yùn)動(dòng)員姚明、互聯(lián)網(wǎng)公司騰訊等,;
事件是客觀世界的活動(dòng),,如地震、買賣行為等,;
關(guān)系描述概念,、實(shí)體事件之間客觀存在的關(guān)聯(lián),,如畢業(yè)學(xué)院描述了個(gè)人及其所在院校的關(guān)系,運(yùn)動(dòng)員和籃球運(yùn)動(dòng)員之間的概念和子概念的關(guān)系等,。
知識(shí)圖譜是將互聯(lián)網(wǎng)的信息表達(dá)成更接近人類認(rèn)知世界的形式,,提供了一種更好地組織、管理和理解互聯(lián)網(wǎng)信息的能力,。涉及的技術(shù):認(rèn)知計(jì)算,、知識(shí)表示和推理、信息檢索與抽取,、自然語言處理和語義web,、數(shù)據(jù)挖掘與機(jī)器學(xué)習(xí)等, 知識(shí)圖譜技術(shù)具體地包括知識(shí)表示,、知識(shí)圖譜構(gòu)建和知識(shí)圖譜的應(yīng)用三方面,。
知識(shí)表示研究客觀世界知識(shí)的建模,從知識(shí)的表示和存儲(chǔ),,以及知識(shí)的使用和計(jì)算來使得知識(shí)便于機(jī)器的識(shí)別和理解,;
知識(shí)圖譜的構(gòu)建解決如何建立計(jì)算機(jī)算法從客觀世界或者或聯(lián)網(wǎng)的各種數(shù)據(jù)資源中獲取客觀世界的知識(shí),主要研究使用何種數(shù)據(jù)和方法抽取何種知識(shí),;
知識(shí)圖譜應(yīng)用主要研究如何利用知識(shí)圖譜建立基于知識(shí)的智能服務(wù)系統(tǒng),,更好地解決實(shí)際應(yīng)用問題。
二,、現(xiàn)有的知識(shí)圖譜資源
人工構(gòu)建(英文wordNet和Cyc項(xiàng)目以及中文的HowNet,,Cyc是世界知識(shí)庫)
群體智慧構(gòu)建(維基百科是至今利用群體智能建立的互聯(lián)網(wǎng)上最大的知識(shí)資源,因此出現(xiàn)了很多使用維基百科構(gòu)建知識(shí)庫的項(xiàng)目,,如DBpedia,、YAGO和Freebase等。)
基于互聯(lián)網(wǎng)鏈接 數(shù) 據(jù) 構(gòu) 建 的 知 識(shí) 資 源(國際萬維網(wǎng)組織W3C 于2007年發(fā)起的開放互聯(lián)數(shù)據(jù)項(xiàng)目(LOD)
基于機(jī)器學(xué)習(xí)和信息抽取構(gòu)建的知識(shí)圖譜(從互聯(lián)網(wǎng)數(shù)據(jù)自動(dòng)獲取知識(shí)是建立可持續(xù)發(fā)展知識(shí)圖譜的發(fā)展趨勢(shì),。這類知識(shí)圖譜構(gòu)建的特點(diǎn)是面向互聯(lián)網(wǎng)的大規(guī)模,、開放、異構(gòu)環(huán)境,,利用機(jī)器學(xué)習(xí)和信息抽取技術(shù)自動(dòng)獲取 Web上的信息構(gòu)建知識(shí)庫,。如華盛頓大學(xué)圖靈中心的KnowItAll和TextRunner)
三、知識(shí)表示
基于符號(hào)邏輯的表示(與人類的自然語言比較接近,,是最早使用的一種知識(shí)表示方法,,但在大數(shù)據(jù)時(shí)期不能很好的解決知識(shí)表示的問題)
萬維網(wǎng)內(nèi)容的知識(shí)表示(XML,基于萬維網(wǎng)資源語義元數(shù)據(jù)描述框架RDF,,基于描述邏輯的本體描述語言O(shè)WL,,XML通過內(nèi)容標(biāo)記,便于數(shù)據(jù)交換,;(重點(diǎn))RDF通過三元組(主體,,謂詞,,客體)描述互聯(lián)網(wǎng)資源之間的語義關(guān)系;OWL構(gòu)建在RDF之上,,具有更強(qiáng)的表達(dá)及解釋能力的語言,。)
表示學(xué)習(xí)(通過機(jī)器學(xué)習(xí)或深度學(xué)習(xí),將研究對(duì)象的語義信息表示為稠密低維的實(shí)值向量,。對(duì)不同粒度的知識(shí)單元進(jìn)行隱式的向量化表示,,來支持大數(shù)據(jù)環(huán)境下知識(shí)的快速計(jì)算)
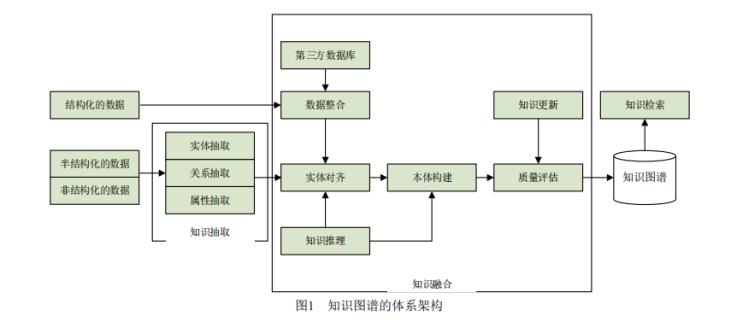
三、知識(shí)圖譜的構(gòu)建技術(shù)
互聯(lián)網(wǎng)上分布,、異構(gòu)的海量資源 ->概念層次學(xué)習(xí),,事實(shí)學(xué)習(xí);已有的結(jié)構(gòu)化異構(gòu)語義資源->異構(gòu)資源的語義集成
1.概念層次學(xué)習(xí)通過合理的技術(shù),,抽取知識(shí)表示中的概念,,確定其上下位關(guān)系
2.事實(shí)學(xué)習(xí):
有監(jiān)督的事實(shí)知識(shí)獲取方法需要有已標(biāo)注文檔作為訓(xùn)練集,可以分為基于規(guī)則學(xué)習(xí),、基于分類標(biāo)注和基于序列標(biāo)注方法等,。基于規(guī)則學(xué)習(xí)的語義標(biāo)注方法從帶語義標(biāo)注的語料中自動(dòng)學(xué)習(xí)標(biāo)注規(guī)則,,利用規(guī)則對(duì)數(shù)據(jù)資源進(jìn)行語義標(biāo)注,,適合比較規(guī)范資源上的知識(shí)獲取,;基于分類的知識(shí)獲取方法將知識(shí)獲取轉(zhuǎn)化為分類問題,,根據(jù)確定的標(biāo)注特征從標(biāo)注語料中學(xué)習(xí)標(biāo)注模型;基于序列模式標(biāo)注的方法同時(shí)考慮多個(gè)語義標(biāo)注之間的關(guān)系,,可以提高標(biāo)注的準(zhǔn)確率,。
半監(jiān)督的知識(shí)獲取方法主要包括自擴(kuò)展方法和弱監(jiān)督方法。自擴(kuò)展方法需要初始的種子實(shí)體對(duì),,根據(jù)這些種子實(shí)體對(duì),,發(fā)現(xiàn)新的語義模板,再對(duì)語料進(jìn)行迭代抽取以發(fā)現(xiàn)新的實(shí)體對(duì),,其主要問題是語義漂移;弱監(jiān)督方法使用知識(shí)庫中的關(guān)系啟發(fā)式地標(biāo)注文本,,其主要問題在于訓(xùn)練實(shí)例中本身帶有大量噪音,。
無監(jiān)督的知識(shí)獲取方法主要是開放信息抽取,使用自然語言處理方法,,無須預(yù)先給定要抽取的關(guān)系類別,,自動(dòng)將自然語言句子轉(zhuǎn)換為命題,這種方法在處理復(fù)雜句子時(shí)效果會(huì)受到影響
3.語義集成,,就是在異構(gòu)知識(shí)庫之間,,發(fā)現(xiàn)實(shí)體間的等價(jià)關(guān)系,,從而實(shí)現(xiàn)知識(shí)共享。主要方法包括:
基于文本的方法主要利用本體中實(shí)體的文本信息,,例如實(shí)體的標(biāo)簽和摘要,。通過計(jì)算兩個(gè)實(shí)體字符串之間的相似度來確定實(shí)體之間是否具有匹配關(guān)系。
基于結(jié)構(gòu)的 方 法 主 要 利 用 本 體 的 圖 結(jié) 構(gòu) 信 息 對(duì) 本 體 進(jìn) 行 匹 配,。利用本體的圖結(jié)構(gòu),,對(duì)實(shí)體間的相似度進(jìn)行傳播,從而提高對(duì)齊的效果,。
基于背景知識(shí)的方法一般使用DBpedia或WordNet等已有的大規(guī)模領(lǐng)域無關(guān)知識(shí)庫作為背景知識(shí)來提高匹配效果,。
基于機(jī)器學(xué)習(xí)的方法將本體匹配問題視為機(jī)器學(xué)習(xí)中的分類或優(yōu)化問題,從而采取機(jī)器學(xué)習(xí)方法獲得匹配結(jié)果,。
四,、知識(shí)圖譜的應(yīng)用
語義搜索、知識(shí)問答,,以及基于知識(shí)的大數(shù)據(jù)分析與決策






載")
贊")
