 998
998
 2022-09-15 15:03:55
2022-09-15 15:03:55
 2022-09-15
2022-09-15










https://mp.weixin.qq.com/s/gbMpds_GHENUQQvy0fZSLw
DSE精選文章
Set-Based Adaptive Distributed Diferential Evolution for Anonymity-Driven Database Fragmentation
數(shù)據(jù)庫碎片可以通過打破屬性之間的敏感關(guān)聯(lián)來保護(hù)外包數(shù)據(jù)存儲(chǔ)的隱私,。數(shù)據(jù)庫碎片算法需要先驗(yàn)知識(shí)處理數(shù)據(jù)庫中的敏感關(guān)聯(lián),,因此這些算法的有效性受到先驗(yàn)知識(shí)的限制,。受匿名技術(shù)中匿名度度量的啟發(fā),該文提出了一種基于集合的自適應(yīng)分布式差分進(jìn)化(S-ADDE)算法,,用于解決匿名驅(qū)動(dòng)的數(shù)據(jù)庫碎片問題,。S-ADDE中的個(gè)體代表數(shù)據(jù)庫分片的解,每個(gè)解的匿名度設(shè)置為個(gè)體的ftness值,。S-ADDE中個(gè)體的更新反映了數(shù)據(jù)庫碎片化匿名度的增加,。此外,該文的主要貢獻(xiàn)如下:
1.為了保證種群的多樣性,,該文采用包含四個(gè)亞種群的島嶼模型,;
2.該文提出了兩種基于集合的算子,即基于集合的變異算子和基于集合的交叉算子,,將傳統(tǒng)差分進(jìn)化中的連續(xù)域轉(zhuǎn)移到數(shù)據(jù)庫碎片問題中的離散域,;
3.在基于集合的變異算子中,,每個(gè)個(gè)體的變異策略根據(jù)進(jìn)化性能自適應(yīng)選擇,;
4.實(shí)驗(yàn)結(jié)果表明,該文提出的S-ADDE明顯優(yōu)于文中比較的方法,,驗(yàn)證了提出的算子的有效性,。
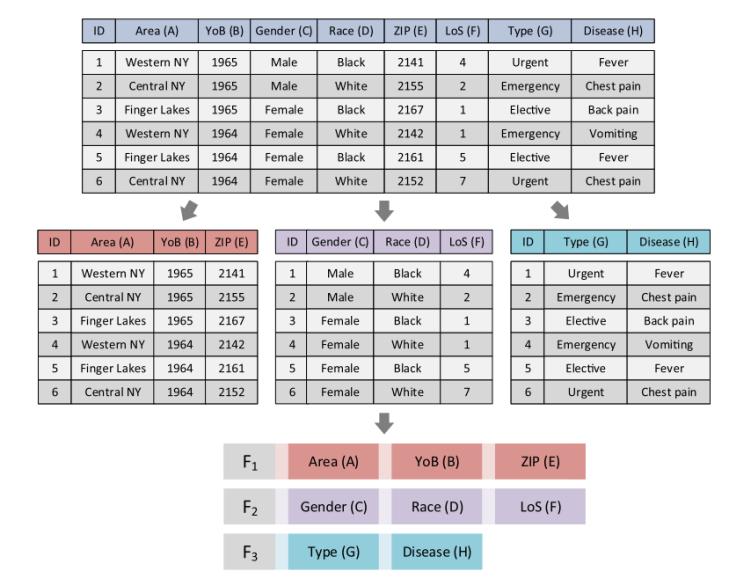
如圖1所示,描述了一個(gè)樣本數(shù)據(jù)庫,,包含九個(gè)屬性和六個(gè)記錄,。其中數(shù)據(jù)庫分為三個(gè)片段,這三個(gè)片段構(gòu)成圖底部所示的片段解決方案,。所提出的S-ADDE算法中的每個(gè)個(gè)體代表一個(gè)數(shù)據(jù)庫碎片解決方案,。因此,個(gè)體中的每個(gè)位表示數(shù)據(jù)庫中的一個(gè)屬性,,其值表示選擇相應(yīng)屬性進(jìn)行分配的片段,。
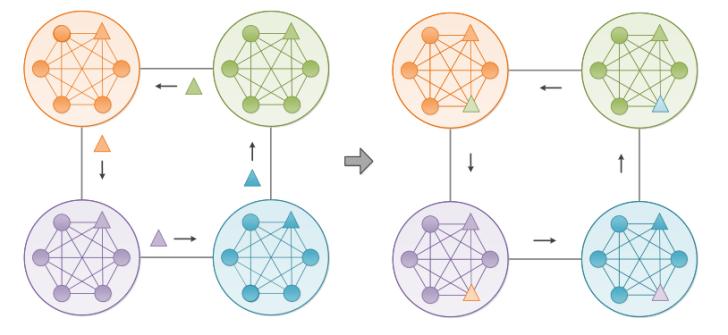
如圖2所示,描述了島嶼模型的一個(gè)示例,其中每個(gè)大圓表示一個(gè)子種群,。在大圓中,,小三角形和圓代表最好的個(gè)體和個(gè)體其他亞群體個(gè)體。子種群中的最佳個(gè)體以預(yù)定義的遷移間隔被發(fā)送到通信拓?fù)渖系泥徲蜃臃N群,。然后,,隨機(jī)選擇每個(gè)子群體中的一個(gè)個(gè)體,并由接收到的精英個(gè)體代替,。
如表1所示,,描述了其他方法在實(shí)驗(yàn)中獲得的平均值和標(biāo)準(zhǔn)偏差值,最佳結(jié)果用黑體標(biāo)出,??梢钥吹剑琒-ADDE算法在所有測試用例上都優(yōu)于其他方法,,可以在探索性搜索和開發(fā)性搜索之間實(shí)現(xiàn)更好的平衡,。但是在復(fù)雜的測試用例(如和)中,S-ADDE更容易陷入局部最優(yōu),。

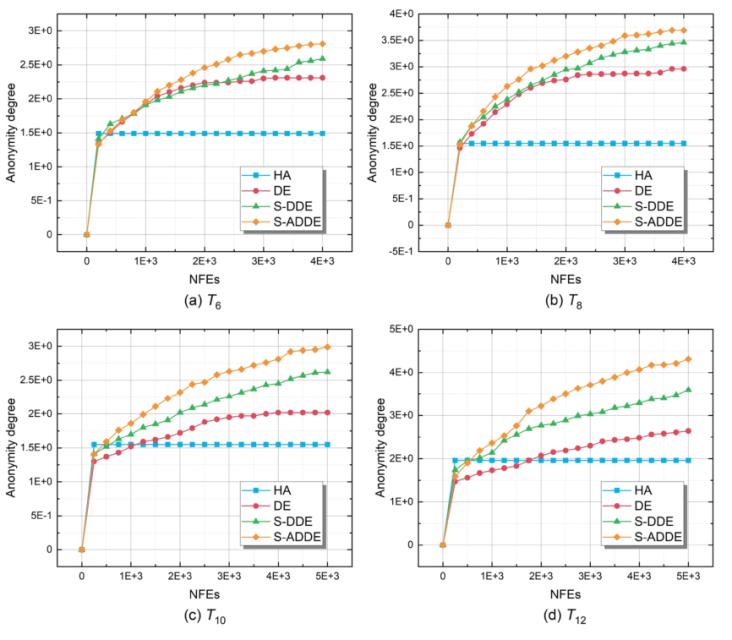
如圖3所示,,描述了四個(gè)典型測試用例的收斂曲線。其中,,HA是一種針對(duì)數(shù)據(jù)庫碎片問題的最先進(jìn)的啟發(fā)式算法,,DE用作基線算法,S-DDE算法中數(shù)據(jù)庫碎片問題通過基于集合的變異和交叉算子進(jìn)行優(yōu)化,。
一開始,,這三種算法都收斂得很快。HA很快陷入局部最優(yōu)并停滯,。由于DE和S-ADDE的探索能力,,它們可以在搜索過程中不斷提高匿名度。S-ADDE的綠線和DE的紅線之間的差異驗(yàn)證了孤島模型和所提出的基于集合的算子在S-ADDE中的有效性,。
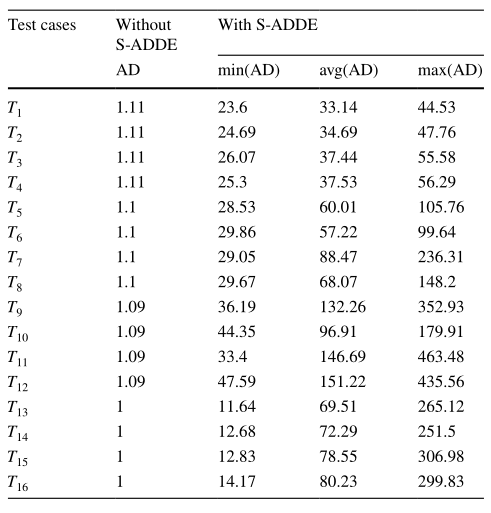
如表2所示,,描述了S-ADDE算法結(jié)果對(duì)原始數(shù)據(jù)集的影響。其中,,AD表示每個(gè)數(shù)據(jù)集的匿名程度,,min(AD)、avg(AD)和max(AD)表示由S-ADDE中的片段獲得的匿名度的最小值,、平均值和最大值,。
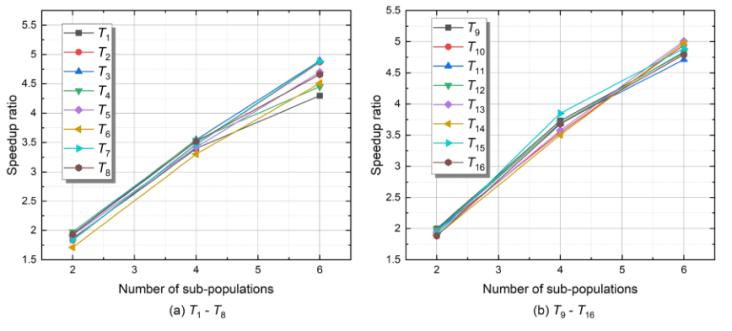
如圖4所示,描述了16個(gè)測試用例的S-ADDE加速比,。隨著S-ADDE的并行粒度不斷增加,,加速比也顯著增加,。不同測試用例中的加速比曲線各不相同,這是因?yàn)椴煌臏y試用例具有不同的復(fù)雜性,,需要不同的評(píng)估時(shí)間,。
該文定義了一個(gè)匿名驅(qū)動(dòng)的數(shù)據(jù)庫碎片問題。為了解決這個(gè)問題,,該文提出了S-ADDE 算法,。S-ADDE算法利用孤島模型來提高種群多樣性,這在復(fù)雜性高的搜索問題中至關(guān)重要,。該文提出了兩種基于集合的算子,,即具有自適應(yīng)變異策略選擇的基于集合的變異算子和基于集合的交叉算子。S-ADDE的計(jì)算效率驗(yàn)證了所提出算子的有效性,。此外,,該文對(duì)數(shù)據(jù)庫分片的隱私問題(即匿名度)進(jìn)行了優(yōu)化。在未來工作中,,作者計(jì)劃進(jìn)一步研究和優(yōu)化數(shù)據(jù)庫碎片的效用問題,。





張彥春,,廣州大學(xué)/鵬城實(shí)驗(yàn)室特聘教授,澳大利亞維多利亞大學(xué)名譽(yù)教授,。多年來一直從事社會(huì)計(jì)算和電子健康,,大數(shù)據(jù)與AI算法與應(yīng)用研究工作,在信息技術(shù)及醫(yī)學(xué)領(lǐng)域發(fā)表國際期刊和學(xué)術(shù)會(huì)議文400余篇,。已經(jīng)出版,,編輯書刊和專輯20余部,完成指導(dǎo)相關(guān)方向40多名博士生和博士后,。

Data Science and Engineering(DSE)是由中國計(jì)算機(jī)學(xué)會(huì)(CCF)主辦,、數(shù)據(jù)庫專業(yè)委員會(huì)承辦、施普林格自然(Springer Nature)出版的Open Access期刊,。為了迎合相關(guān)領(lǐng)域的快速發(fā)展需求,,DSE致力于出版所有和數(shù)據(jù)科學(xué)與工程領(lǐng)域相關(guān)的關(guān)鍵科學(xué)問題與前沿研究熱點(diǎn),以大數(shù)據(jù)作為研究重點(diǎn),,征稿范疇主要包括4方面:(1)數(shù)據(jù)本身,,(2)數(shù)據(jù)信息提取方法,(3)數(shù)據(jù)計(jì)算理論,,和(4)用來分析與管理數(shù)據(jù)的技術(shù)和系統(tǒng),。
目前期刊已被EI、ESCI與SCOPUS收錄,,CiteScore 2021為6.4,,在Computer Science Applications領(lǐng)域排名# 157/747(位列前21%)。稿件處理費(fèi)由贊助商中新賽克(Sinovatio)承擔(dān),,歡迎大家免費(fèi)下載閱讀期刊全文,,并積極投稿,。
論文原文鏈接:https://link.springer.com/article/10.1007/s41019-021-00170-4





