 2925
2925
 2022-11-21 19:38:04
2022-11-21 19:38:04
 2022-11-21
2022-11-21










來源:北京大學數(shù)據(jù)與智能實驗室


關鍵詞
Database Management System
Performance Optimization
Performance Prediction
Anomaly Diagnosis
Database Tuning
Survey
導 讀
SCIENCE CHINA Information Sciences (SCIS)中文全稱為中國科學信息科學,,是中國科學院和國家自然科學基金委員會共同主辦、《中國科學》雜志社出版的學術刊物,,其2022影響因子7.275,,主要發(fā)表信息科學領域的高質(zhì)量學術論文。PKU-DAIR實驗室研究成果《Survey on Performance Optimization for Database Systems》已被SCIENCE CHINA Information Sciences接收,。近年來,,性能優(yōu)化作為數(shù)據(jù)庫運維的重要環(huán)節(jié),在工業(yè)界與學術界均受到廣泛關注,。該綜述旨在梳理總結關于數(shù)據(jù)庫性能優(yōu)化的研究工作,,以供相關領域的研究人員與工業(yè)界人士進行快速了解。該綜述根據(jù)運維的不同環(huán)節(jié),,按照性能預測,、異常診斷、調(diào)優(yōu)這三個主題,,分析了相關任務的目標與挑戰(zhàn),,總結了現(xiàn)有工作的應對方案、優(yōu)點與局限性,,并闡述了未來有待進一步探索的方向,。
論文鏈接:
https://www.sciengine.com/SCIS/doi/10.1007/s11432-021-3578-6
01 引言
隨著現(xiàn)代數(shù)據(jù)庫系統(tǒng)與業(yè)務日益復雜,性能優(yōu)化已成為數(shù)據(jù)庫領域的研究熱點,。作為服務級別協(xié)議(Service Level Agreement, SLA)的重要組成部分,,數(shù)據(jù)庫性能是用戶所關心的重要指標,也是運維人員的重點優(yōu)化對象,。數(shù)據(jù)庫性能的衡量指標主要包括事務或查詢的吞吐量與延遲,,部分場景還會考慮資源用量。本文僅關注以吞吐量與延遲作為主要優(yōu)化目標的研究工作,。在數(shù)據(jù)庫系統(tǒng)中,,影響性能的主要因素包括系統(tǒng)設計、配置,、工作負載,。其中,系統(tǒng)設計通常由開發(fā)人員考慮,,本文則是從運維角度,,關注配置與工作負載相關優(yōu)化。相應主題包括:性能預測(Performance Prediction)、異常診斷(Anomaly Diagnosis),、調(diào)優(yōu)(Tuning),。本文圍繞這些主題,評述了具有代表性的研究工作,,闡述了研究挑戰(zhàn)與未來有待進一步探索的方向,。
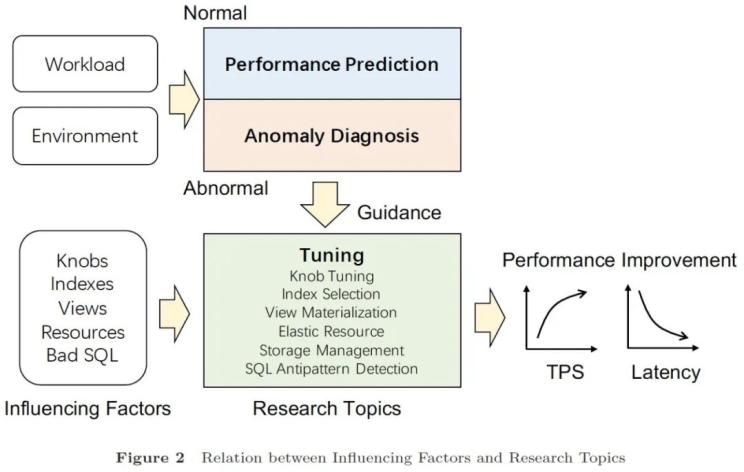
圖 1 數(shù)據(jù)庫性能影響因素與研究主題的關聯(lián)
02 數(shù)據(jù)集
數(shù)據(jù)集是性能優(yōu)化實驗的基礎。大多數(shù)研究工作使用開源benchmark構建數(shù)據(jù),,其工作負載分為OLTP(事務型)與OLAP(分析型)兩種,。典型的OLTP benchmark包括TPC-C, TPC-E, YCSB, TATP, Smallbank等。典型的OLAP benchmark包括TPC-H, TPC-DS, JOB等,。部分研究工作則使用來自真實業(yè)務的數(shù)據(jù),。這些數(shù)據(jù)往往更具可信度,但通常難以獲取,,因為它們?nèi)菀咨婕皵?shù)據(jù)庫用戶隱私,,而且數(shù)據(jù)采集與打標簽的開銷較大。
03 性能預測 Performance Prediction
數(shù)據(jù)庫性能預測的目標是在給定的環(huán)境下,,預測查詢的執(zhí)行時間(延遲)或吞吐量,。與數(shù)據(jù)庫優(yōu)化器(Optimizer)內(nèi)部的代價估計(Cost Estimation)有所不同,,它往往是監(jiān)控系統(tǒng)或自適應數(shù)據(jù)庫系統(tǒng)(Self-driving Database System)的組成部分,,以指導正常環(huán)境下的性能調(diào)優(yōu)。隨著機器學習技術的發(fā)展,,許多研究工作用機器學習模型代替基于公式與規(guī)則的算法,,在數(shù)據(jù)庫環(huán)境相對固定的情形下,能夠取得較好的效果,。相關工作按預測對象可分為單查詢,、多查詢兩類。
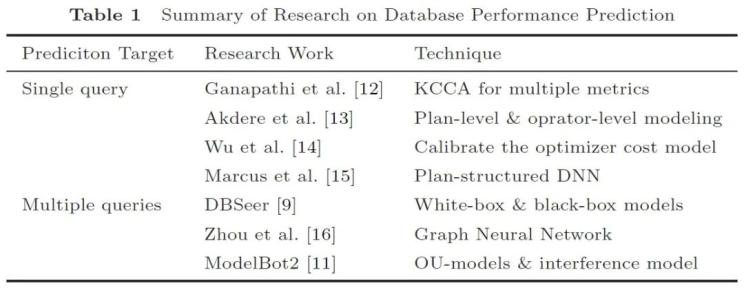
圖 2 數(shù)據(jù)庫性能預測研究工作匯總
(3-1)單查詢
此類工作僅針對單一查詢,,不考慮并發(fā)執(zhí)行的影響,。我們選取了近年來采用機器學習算法的代表性工作進行評述。它們將執(zhí)行計劃以算子粒度編碼為向量,,訓練機器學習模型用于預測,。其中,編碼的信息可包括來自數(shù)據(jù)庫優(yōu)化器的信息,,如基數(shù)(Cardinality),、代價(Cost)等。
(3-2)多查詢
此類工作以整個工作負載為輸入,,通常先進行聚類和采樣,,再輸入模型進行預測。部分工作不僅考慮工作負載信息,還將環(huán)境信息加入模型輸入,,例如配置參數(shù),、硬件信息等,這有助于模型適應動態(tài)變化的環(huán)境,。
04 異常診斷 Anomaly Diagnosis
數(shù)據(jù)庫性能異常主要表現(xiàn)為吞吐量下降或較長的查詢延遲,。異常診斷的目標是定位異常根因,可作為異常環(huán)境下性能調(diào)優(yōu)的指導,。在不同研究工作中,,診斷系統(tǒng)的輸入、輸出,、支持的異常類型均有所不同,。我們根據(jù)輸入數(shù)據(jù)的不同,將其分為三類:
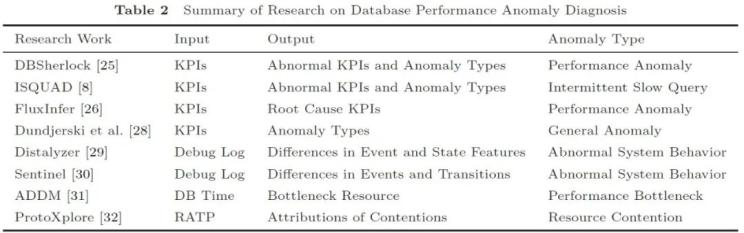
圖 3 數(shù)據(jù)庫性能異常診斷研究工作匯總
(4-1)基于監(jiān)控指標
此類方法的輸入是操作系統(tǒng)和數(shù)據(jù)庫的關鍵績效指標(Key Performance Indicator, KPI),,包括CPU,、內(nèi)存、I/O,、網(wǎng)絡等資源指標,,以及讀寫行數(shù)等工作負載指標。其輸出通常包含異常監(jiān)控指標與推測的異常類型,,通常能支持大多數(shù)常見的性能異常,。
(4-2)基于日志
此類方法的輸入是數(shù)據(jù)庫的debug日志,通常以兩份日志為輸入,,比較其系統(tǒng)行為的差異,。若兩份日志分別來自正常、異常環(huán)境,,則其系統(tǒng)行為的差異可反映異常根因,。此類方法的主要局限性在于記錄debug日志的開銷較大。
(4-3)基于時間
此類方法的輸入是時間指標,,通常僅限于診斷資源瓶頸與競爭,,相關算法通常基于圖結構的分析,,以探索不同組件的資源開銷,。
05 調(diào)優(yōu)
數(shù)據(jù)庫調(diào)優(yōu)旨在對性能影響因素進行調(diào)整,以提高吞吐量或降低延遲,。相關的影響因素包括配置旋鈕(Configuration Knobs),、索引(Indexes)、視圖(View),、資源(Resource),、存儲(Storage),、查詢語句設計等。近年來,,機器學習算法在該領域得到廣泛應用,,代表性方法包括強化學習(Reinforcement Learning)、貝葉斯優(yōu)化(Bayesian Optimization)等,。我們根據(jù)調(diào)優(yōu)對象的不同,,將相關工作分為以下六類:
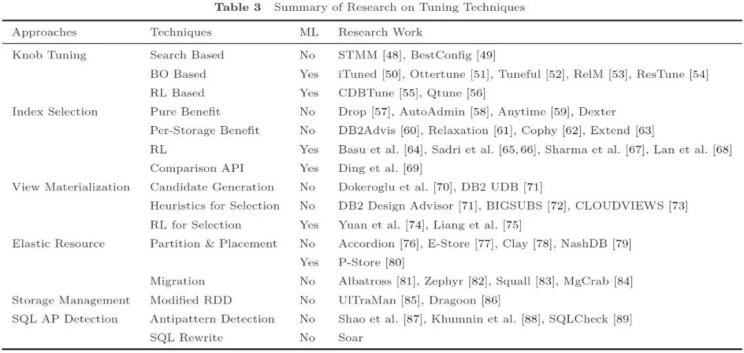
圖 4 數(shù)據(jù)庫性能調(diào)優(yōu)研究工作匯總
(5-1)調(diào)參(Knob Tuning)
數(shù)據(jù)庫系統(tǒng)內(nèi)通常有上百個可供調(diào)節(jié)的旋鈕(Knob),對性能和資源使用有著重要影響,。局部最優(yōu)的參數(shù)往往并非全局最優(yōu),,不同參數(shù)之間存在相互影響,搜索空間大而復雜,。常見調(diào)參技術包括基于規(guī)則搜索,、貝葉斯優(yōu)化、強化學習等,。
(5-2)索引選擇(Index Selection)
索引選擇是指對給定的工作負載與存儲限制,,選擇合適的列建立索引。該任務的主要挑戰(zhàn)包括:(1)備選的索引很多,,因為可以建立多列索引,;(2)索引之間存在相互影響;(3)索引并非越多越好,,例如增刪改操作會有索引開銷,。傳統(tǒng)研究工作通常以純收益或單位空間收益為優(yōu)化目標,基于貪心,、迭代,、線性規(guī)劃等方法尋找最優(yōu)解,。近年來,,強化學習也被應用于這一問題。也有研究工作從代價比較的角度,,利用機器學習模型進行優(yōu)化,。
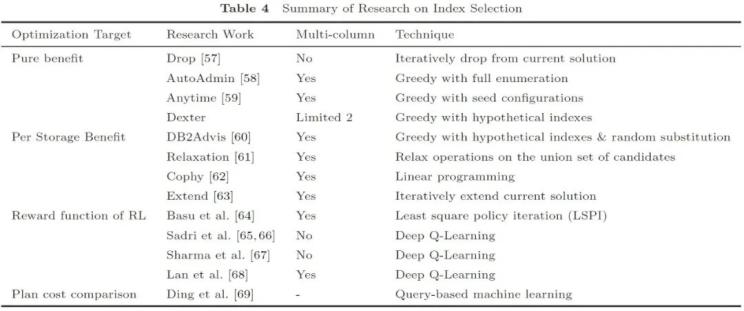
圖 5 索引選擇研究工作細節(jié)匯總(屬于調(diào)優(yōu)方法之一)
(5-3)視圖物化(View Materialization)
視圖物化是指保存一些查詢或子查詢的結果,供其他查詢使用,。它可以通過減少重復操作來提升性能,,但具有一定的存儲和維護代價。傳統(tǒng)方法主要有遺傳爬山算法,、整數(shù)線性規(guī)劃等,,近年來也有基于強化學習的方法被提出。
(5-4)彈性資源(Elastic Resource)
彈性資源主要通過增減設備節(jié)點數(shù)量,、調(diào)整備份等方式進行性能優(yōu)化,。以增加設備節(jié)點為例,,首先數(shù)據(jù)被重新分片并決定備份數(shù),其次決定如何在各節(jié)點上分配這些數(shù)據(jù)分片,,最后進行數(shù)據(jù)遷移,。刪除節(jié)點的過程也是類似的。據(jù)此,,相關研究工作主要分為兩類:一類關注資源與數(shù)據(jù)的分配,,包括如何調(diào)整節(jié)點數(shù)、數(shù)據(jù)分片,、備份等,;另一類則關注如何動態(tài)遷移數(shù)據(jù),以降低遷移過程中的性能損失,。
(5-5)存儲管理(Storage Management)
分布式存儲管理也是性能優(yōu)化的一種方式,。一方面,這樣的技術有利于彌補通用分布式框架(如Spark)的不足,,例如垃圾回收,、索引構建等。另一方面,,它們可以為特定的數(shù)據(jù)和方法提供支持,,例如軌跡數(shù)據(jù)上的K近鄰算法等。
(5-6)SQL不良模式檢測(SQL Antipattern Detection)
SQL不良模式(SQL Antipattern)包括不良的查詢(Queries)和模式(Schema),。此類工作可協(xié)助數(shù)據(jù)庫管理人員進行定位和改寫,。目前,相關工作主要依賴于人工制定的規(guī)則進行匹配檢測,。
06 挑戰(zhàn)與未來工作
數(shù)據(jù)庫性能優(yōu)化仍然面臨眾多挑戰(zhàn),。我們針對不同主題,提出了一些有待解決的問題,。
(6-1)性能預測
優(yōu)化器的估計不準確:現(xiàn)有方法大多依賴于優(yōu)化器的基數(shù)估計或代價估計,,而這一估計是不準確的。近年來,,機器學習算法被廣泛應用于此類問題,,但仍具有一定挑戰(zhàn)性。
與性能調(diào)優(yōu)的隔閡:此類方法雖然能預測調(diào)優(yōu)前后的性能,,但并不能指導何時調(diào)優(yōu)與如何調(diào)優(yōu),,以降低調(diào)優(yōu)過程中的系統(tǒng)性能損失。
(6-2)性能異常診斷
有限的異常數(shù)據(jù):數(shù)據(jù)對此類工作的評測至關重要,,但由于發(fā)生頻率低,、缺乏標準、打標簽難度大,,往往難以獲得,。
數(shù)據(jù)采集的開銷:從數(shù)據(jù)庫系統(tǒng)視圖中采集一些表級指標,,或者記錄debug日志,都會造成顯著的性能開銷,。
OLTP與OLAP:二者的性能異常表現(xiàn)有較大差異,,這一問題在混合負載中尤其顯著。
(6-3)性能調(diào)優(yōu)
何時優(yōu)化:現(xiàn)有的調(diào)優(yōu)過程通常是在發(fā)生性能下降之后進行的,,并不能避免低性能的出現(xiàn)
動態(tài)工作負載:當工作負載發(fā)生變化時,,原先的優(yōu)化方案可能并不適用。
這些問題的一種解決方案是在線優(yōu)化,,但其安全性仍具有挑戰(zhàn),。
(6-4)其他
近年來,自適應數(shù)據(jù)庫系統(tǒng)(Self-driving Database System)是一個熱門話題,,此類數(shù)據(jù)庫系統(tǒng)能根據(jù)工作負載和數(shù)據(jù)庫環(huán)境進行自動優(yōu)化,,而無需人工干預。然而,,數(shù)據(jù)庫系統(tǒng)內(nèi)部包含大量組件,,如何作為統(tǒng)一的系統(tǒng)進行設計,仍有待進一步探索,。此外,,一些新的數(shù)據(jù)庫組件設計,例如基于學習的優(yōu)化器,、非易失性存儲,、大規(guī)模分布式引擎等,如何將數(shù)據(jù)庫優(yōu)化工作遷移到此類系統(tǒng)上,,進行不同于傳統(tǒng)數(shù)據(jù)庫的設計,,也是值得研究的方向。
詳細了解本工作,,請訪問下方鏈接地址:
論文鏈接:
https://www.sciengine.com/SCIS/doi/10.1007/s11432-021-3578-6
References:
[1] Zhou X, Chai C, Li G, et al. Database meets artificial intelligence: A survey. TKDE, 2022.
[2] Pavlo A, Angulo G, Arulraj J, et al. Self-driving database management systems. CIDR, 2017.
[3] Mozafari B, Curino C, Jindal A, et al. Performance and resource modeling in highly-concurrent OLTP workloads. SIGMOD, 2013.
[4] Ma M, Yin Z, Zhang S, et al. Diagnosing root causes of intermittent slow queries in large-scale cloud databases. VLDB, 2020.
[5] Zhang X, Chang Z, Li Y, et al. Facilitating database tuning with hyper-parameter optimization: A comprehensive experimental evaluation. VLDB, 2022.
END
實驗室簡介
北京大學數(shù)據(jù)與智能實驗室(Data And Intelligence Research Lab at Peking Univeristy,,PKU-DAIR實驗室)由北京大學計算機學院崔斌教授領導,長期從事數(shù)據(jù)庫系統(tǒng),、大數(shù)據(jù)管理與分析,、人工智能等領域的前沿研究,,在理論和技術創(chuàng)新以及系統(tǒng)研發(fā)上取得多項成果,,已在國際頂級學術會議和期刊發(fā)表學術論文100余篇,發(fā)布多個開源項目,。課題組同學曾數(shù)十次獲得包括CCF優(yōu)博,、北大優(yōu)博、微軟學者,、蘋果獎學金,、谷歌獎學金等榮譽,。PKU-DAIR實驗室持續(xù)與工業(yè)界展開卓有成效的合作,與騰訊,、阿里巴巴,、蘋果、微軟,、百度,、快手、中興通訊等多家知名企業(yè)開展項目合作和前沿探索,,解決實際問題,,進行科研成果的轉化落地。
鏈接:[SCIS 2022] 數(shù)據(jù)庫性能優(yōu)化綜述 (qq.com)





