








灣區(qū)時訊 幾千年華夏文明留下的海量古籍文獻資料,,反映了當(dāng)時社會在政治、軍事,、經(jīng)濟,、科技、教育,、文化等各個領(lǐng)域的發(fā)展,,具有寶貴的歷史價值和社會價值。但由于語言的演變,,通讀理解古籍文獻的難度較大,,華南理工大學(xué)電子與信息學(xué)院金連文教授所在的“深度學(xué)習(xí)與視覺計算實驗室”,致力于利用先進的AI技術(shù)使古籍更易讀懂,,發(fā)布了“通古大模型”“古籍文檔分析與識別系統(tǒng)”“彝文文檔分析識別系統(tǒng)”等多項成果,,為中國古籍文物數(shù)據(jù)挖掘,、知識發(fā)現(xiàn)、智能化開發(fā)與利用等領(lǐng)域提供了技術(shù)支撐,。

“通古大模型”操作界面
日前,,“深度學(xué)習(xí)與視覺計算實驗室”在EvaHan2023古籍文白翻譯國際比賽中獲得冠軍。賽后,,金連文教授團隊?wèi){借在古籍領(lǐng)域長期積累的豐富大數(shù)據(jù)資源,,加以自動生成的對話模板,通過大模型指令微調(diào)技術(shù)訓(xùn)練,,構(gòu)建了數(shù)字人文模型——通古大模型,。該模型可智能實現(xiàn)文白翻譯、句讀標(biāo)點和古籍檢索等功能,,使大眾更便捷有效地了解中國傳統(tǒng)文化,。

“古籍文檔分析與識別系統(tǒng)”演示界面
金連文教授團隊還開發(fā)了業(yè)內(nèi)先進的古籍文檔分析與識別系統(tǒng),集成了該團隊自主研發(fā)的古籍句讀(自動標(biāo)點)和文本翻譯兩大功能,。用戶只需提供一張古籍圖片,,系統(tǒng)便能自動識別并定位其中所有的文本,將識別出的文本按照正確的閱讀順序排序,,添加標(biāo)點符號并翻譯為現(xiàn)代文,,便于閱讀。
團隊精心對這一系統(tǒng)進行了算法優(yōu)化,,能夠應(yīng)對現(xiàn)實場景中古籍文檔可能出現(xiàn)的各種挑戰(zhàn),,例如書本彎曲、傾斜,、密集以及低分辨率等問題,,實現(xiàn)了技術(shù)的突破。該系統(tǒng)兼具實用性和穩(wěn)健性,,為推動古籍?dāng)?shù)字化工作提供了有力支持,。
系統(tǒng)相關(guān)技術(shù)曾獲2019年首屆數(shù)字中國創(chuàng)新大賽“文化傳承——漢字多場景識別”賽道第一名及總決賽唯一最佳算法能力獎、2022年首屆大灣區(qū)國際算法算例大賽-古籍圖像分析與識別競賽冠軍,。
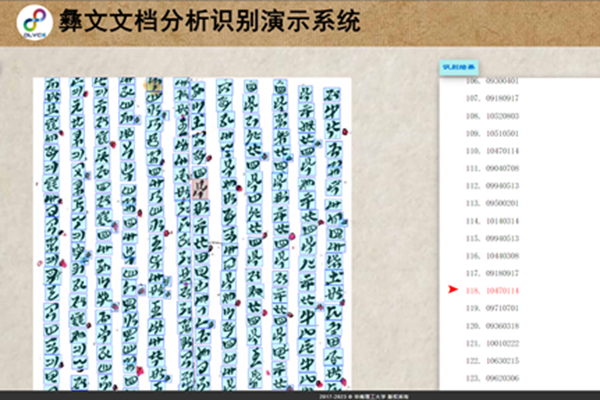
“彝文文檔分析識別系統(tǒng)”演示界面
此外,,團隊還開發(fā)了彝文文檔分析識別系統(tǒng),能自動精確定位并辨識圖片中的彝文文字(以自定義編碼給出輸出),。這項識別技術(shù)采用的彝文編碼基于團隊今年早前與上海大學(xué),、上海合合信息科技公司聯(lián)合發(fā)布的業(yè)界首個古彝文基礎(chǔ)編碼數(shù)據(jù)庫。
古籍文獻是中國傳統(tǒng)文化的載體,,金連文教授團隊開發(fā)的一系列技術(shù),,有助于促進中華優(yōu)秀傳統(tǒng)文化傳承與發(fā)展,對增強國家文化軟實力具有重要意義,。
通訊員/華軒
編輯/劉秀
載")

評論 0